当开发中出现类似报错 : nested exception is org.springframework.beans.factory.BeanCurrentlyInCreationException 就是项目中出现循环依赖了,项目中的处理方式一般是将公共调用的功能放到另一个文件,避免循环引用.那spring 是怎么解决这类问题的呢。A引用B,B引用A的
使用场景 :
| 依赖情况 | 依赖注入方式 | 循环依赖是否被解决 |
|---|---|---|
| AB相互依赖(循环依赖) | 均采用setter方法注入 | 是 |
| AB相互依赖(循环依赖) | 均采用构造器注入 | 否 |
| AB相互依赖(循环依赖) | A中注入B的方式为setter方法,B中注入A的方式为构造器 | 是 |
| AB相互依赖(循环依赖) | B中注入A的方式为setter方法,A中注入B的方式为构造器 | 否 |
从上面的测试结果我们可以看到,不是只有在setter方法注入的情况下循环依赖才能被解决,即使存在构造器注入的场景下,循环依赖依然被可以被正常处理掉。
spring 是怎么解决的 :
提到循环依赖,大脑中最先想到的是"三级缓存","提前暴露"...balabala 至于里面的流程和细节就已经忘的差不多了,下面梳理整个流程,方便加深记忆
Spring通过三级缓存解决了循环依赖,使用了三个MAP:
其中一级缓存为单例池(singletonObjects),一级缓存,存放的是单例 bean 的映射。注意,这里的 bean 是已经创建完成的。
二级缓存为早期曝光对象earlySingletonObjects,存放的是早期半成品(未初始化完)的 bean,对应关系也是 bean name --> bean instance。 它与 {@link #singletonObjects} 区别在于, 它自己存放的 bean 不一定是完整
三级缓存为早期曝光对象工厂(singletonFactories)。 三级缓存,存放的是 ObjectFactory,可以理解为创建早期半成品(未初始化完)的 bean 的 factory
- 当A、B两个类发生循环引用时,在A完成实例化后,就使用实例化后的对象去 创建一个对象工厂,并添加到三级缓存 中,如果A被AOP代理,那么通过这个工厂获取到的就是A代理后的对象,如果A没有被AOP代理,那么这个工厂获取到的就是A实例化的对象。
- 当A进行属性注入时,会去创建B,同时B又依赖了A,所以创建B的同时又会去调用getBean(a)来获取需要的依赖,此时的 getBean(a)会从缓存中 获取,
- 第一步,先获取到三级缓存中的工厂;
- 第二步,调用对象工工厂的 getObject方法 来获取到对应的对象,得到这个对象后将其注入到B中。
- 紧接着B会走完它的生命周期流程, 包括初始化、后置处理器 等。当B创建完后,会将B再注入到A中,此时A再完成它的整个生命周期。至此,循环依赖结束!
当初就是靠着这图让我搞清了一直不愿意看的循环依赖:
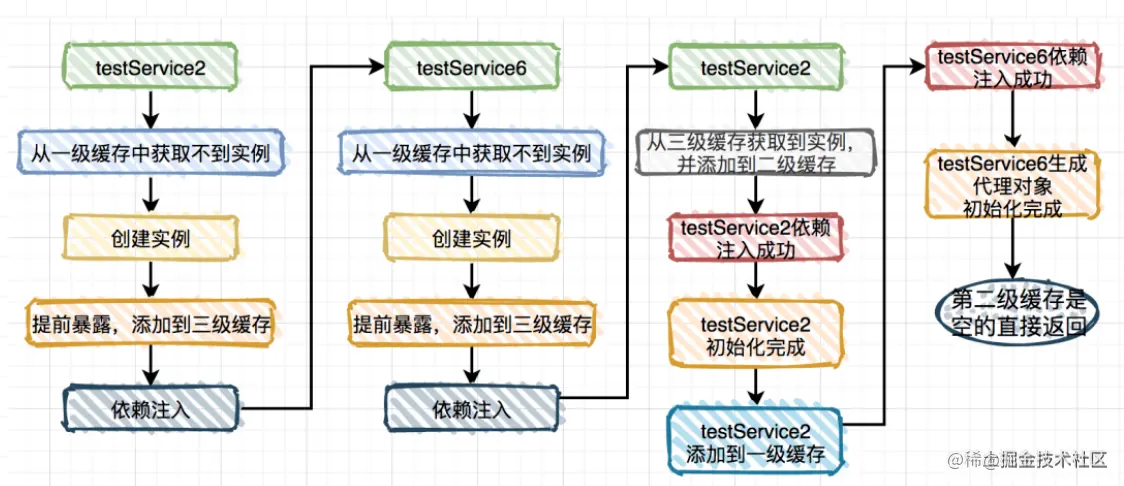 特征: 1.先调用的先完成初始化 2.先三后二最后一级 3.最后二级为空
特征: 1.先调用的先完成初始化 2.先三后二最后一级 3.最后二级为空
源码解读
// DefaultSingletonBeanRegistry.java
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 从单例缓冲中加载 bean
Object singletonObject = this.singletonObjects.get(beanName);
// 缓存中的 bean 为空,且当前 bean 正在创建
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 加锁
synchronized (this.singletonObjects) {
// 从 earlySingletonObjects 获取
singletonObject = this.earlySingletonObjects.get(beanName);
// earlySingletonObjects 中没有,且允许提前创建
if (singletonObject == null && allowEarlyReference) {
// 从 singletonFactories 中获取对应的 ObjectFactory
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 获得 bean
singletonObject = singletonFactory.getObject();
// 添加 bean 到 earlySingletonObjects 中
this.earlySingletonObjects.put(beanName, singletonObject);
// 从 singletonFactories 中移除对应的 ObjectFactory
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
- 首先,从一级缓存
singletonObjects获取。 - 如果,没有且当前指定的
beanName正在创建,就再从二级缓存earlySingletonObjects中获取。 - 如果,还是没有获取到且允许
singletonFactories通过#getObject()获取,则从三级缓存singletonFactories获取。如果获取到,则通过其#getObject()方法,获取对象,并将其加入到二级缓存earlySingletonObjects中,并从三级缓存singletonFactories删除
上面是从缓存中获取,但是缓存中的数据从哪里添加进来的呢?
// DefaultSingletonBeanRegistry.java
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
this.singletonFactories.put(beanName, singletonFactory);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
从这段代码我们可以看出,singletonFactories 这个三级缓存才是解决 Spring Bean 循环依赖的诀窍所在。同时这段代码发生在 #createBeanInstance(...) 方法之后,也就是说这个 bean 其实已经被创建出来了, 但是它还不是很完美(没有进行属性填充和初始化),但是对于其他依赖它的对象而言已经足够了(可以根据对象引用定位到堆中对象),能够被认出来了 。
现三级缓存 singletonFactories 和 二级缓存 earlySingletonObjects 中的值都有出处了,那一级缓存在哪里设置的呢
/ DefaultSingletonBeanRegistry.java
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
添加至一级缓存,同时从二级、三级缓存中删除。
补充:
为什么Sping不选择二级缓存方式,而是要额外加一层缓存?
如果要使用二级缓存解决循环依赖,意味着Bean在构造完后就创建代理对象,这样违背了Spring设计原则。Spring结合AOP跟Bean的生命周期,是在Bean创建完全之后通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来完成的,在这个后置处理的postProcessAfterInitialization方法中对初始化后的Bean完成AOP代理。如果出现了循环依赖,那没有办法,只有给Bean先创建代理,但是没有出现循环依赖的情况下,设计之初就是让Bean在生命周期的最后一步完成代理而不是在实例化后就立马完成代理。