更多文章请观看:www.shangsw.com
一 Spring容器
Spring环境的搭建我在这就不多做说明了,可以自行研究解决。我这里使用的是Spring Framework的5.2.15版本阅读的。
源码分析是一件非常煎熬非常有挑战性的任务,希望你能坚持下来。
1.1 Spring整体架构
Spring框架是一个分层架构,它包含一系列的功能要素,被分为大约20多个模块。这些模块总共被分为以下几个部分:
1.1.1 Core Container
Core Container(核心容器)包含Core、Beans、Context和Expression Language模块。
Core和Beans模块是框架的基础部分,提供IoC和依赖注入特性。这里的基础概念是BeanFactory,它提供对Factory模式的经典实现来消除对程序性单例模式的需要,并真正允许你从程序逻辑中分离出依赖关系和配置。
- Core模块主要包含Spring框架基本的核心工具类,Spring的其他组件都要使用到这个包里的类,Core模块是其他组件的基本核心。
- Beans模块是所有应用都用到的,它包含访问配置文件、创建和管理bean以及进行Inversion of Control/Dependency Injection操作相关的所有类
- Context模块构建于Core和Beans模块基础之上,提供了一种类似于JNDI注册器的框架式的对象访问方法。Context模块继承了Beans的特性,为Spring核心提供了大量扩展、添加国际化、事件传播、资源加载和对Context的透明创建的支持。ApplicationContext接口是Context模块的关键
- Expression Language模块提供了一个强大的表达式语言用于在运行时查询和操纵对象,它是JSP 2.1规范中定义的unifed expression language的一个扩展。该语言支持设置/获取属性的值,属性的分配,方法的调用,访问数组上下文、容器和索引器、逻辑和算术运算符、命名变量以及从Spring的IoC容器中根据名称检索对象
1.1.2 Data Access/Integration
Data Access/Integration层包含有JDBC、ORM、OXM、JMS和Transaction模块。
- JDBC模块提供了一个JDBC抽象层,它可以消除冗长的JDBC编码和解析数据库厂商特有的错误代码。这个模块包含了Spring对JDBC数据访问进行封装的所有类
- ORM模块为流行的对象-关系映射API,如JPA、JDO、Hibernate、iBatis等,提供了一个交互层,利用ORM封装包,可以混合使用所有Spring提供的特性进行O/R映射
- OXM模块提供了一个对Object/XML映射实现的抽象层,Object/XML映射实现包括JAXB、Castor、XMLBeans、JiBX和XStream
- JMS(Java Messaging Service)模块主要包含了一些制造和消费信息的特性
- Transaction模块支持编程和声明性的事务管理,这些事务类必须实现特定的接口,并且对所有的POJO都适用
1.1.3 Web
Web上下文模块建立在应用程序上下文模块之上,为基于Web的应用程序提供了上下文。所以,Spring框架支持与Struts集成。Web模块还简化了处理多部分请求以及将请求参数绑定到域对象的工作。Web层包含了Web、Web-Servlet、Web-Struts和Web-Porlet模块。
- Web模块:提供了基础的面向Web的集成特性。例如,多文件上传,使用servlet listeners初始化IoC容器以及一个面向Web的应用上下文
- Web-Servlet模块web.servlet.jar:该模块包含Spring的model-view-controller(MVC)实现。Spring的MVC框架使得模型范围内的代码和web forms之间能够清楚分离开来,并与Spring框架的其他特性集成在一起
- Web-Struts模块:该模块提供了对Struts支持,使得类在Spring应用中能够与一个典型的Struts Web层集成在一起
- Web-Porlet模块:提供了用于Porlet环境和Web-Servlet模块的MVC的实现
1.1.4 AOP
AOP模块提供了一个符合AOP联盟标准的面向切面编程的实现,它让你可以定义例如方法拦截器和切点,从而将逻辑代码分开,降低它们之间的耦合性。利用source-level的元数据功能,还可以将各种行为的信息合并到你的代码中。
通过配置管理特性,Spring AOP模块直接将面向切面的编程功能集成到了Spring框架中,所以可以很容易使Spring框架管理的任何对象支持AOP。
1.1.5 Test
Test模块支持使用JUnit和TestNG对Spring组件进行测试。
1.2 容器基本用法
bean是Spring最核心的东西,因为Spring就像个大水桶,而bean就像容器中的水。我们首先看看bean的定义:
public class MyBeanTest {
private String testStr = "www.shangsw.com";
public String getTestStr() {
return testStr;
}
public void setTestStr(String testStr) {
this.testStr = testStr;
}
}
很普通的一个bean,Spring的目的就是让我们的bean能成为一个纯粹的POJO,这也是Spring所追求的,配置文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.0.xsd">
<bean id="myTestBean" class="com.bianjf.bean.MyBeanTest"/>
</beans>
Spring的入门示例到这里已经结束了,如下,是我们的测试代码:
public class BeanFactoryTest {
@Test
public void testSimpleLoad() throws Exception {
BeanFactory beanFactory = new XmlBeanFactory(new ClassPathResource("beanFactoryTest.xml"));
MyBeanTest myTestBean = (MyBeanTest) beanFactory.getBean("myTestBean");
System.out.println("结果: " + myTestBean.getTestStr());
}
}
直接使用BeanFactory作为容器对于Spring的使用来说并不多见,在企业级的应用中大多数都会使用的是ApplicationContext(后续介绍)。
1.3 功能分析
这段测试代码的功能是以下几点:
- 读取配置文件beanFactoryTest.xml
- 根据beanFactoryTest.xml中配置找到对应的类的配置,并实例化
- 调用实例化后的实例
通过代码追踪,发现BeanFactory是在spring-beans这个工程下面。我们接下来看spring-beans这个工程
1.4 Spring的结构组成
1.4.1 核心类介绍
1.4.1.1 DefaultListableBeanFactory
XmlBeanFactory继承自DefaultListableBeanFactory,而DefaultListableBeanFactory是整个bean加载的核心部分,是Spring注册及加载bean的默认实现 。而对于XmlBeanFactory与DefaultListableBeanFactory不同的地方其实是在XmlBeanFactory中使用了自定义的XML读取器XmlBeanDefinitionReader,实现了个性化的BeanDefinitionReader读取,DefaultListableBeanFactory继承了AbstractAutowireCapableBeanFactory并实现了ConfigurableListableBeanFactory以及BeanDefinitionRegistry接口。如下图所示,是其类图:
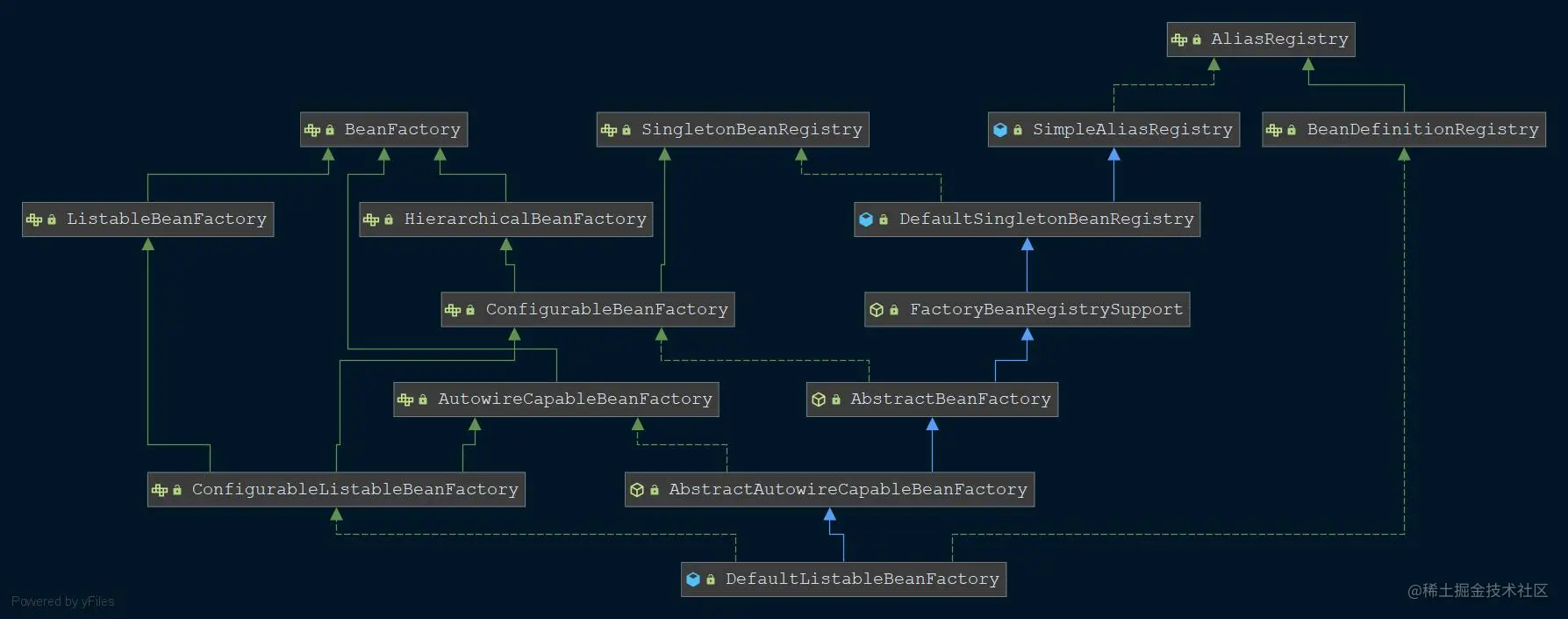
- ConfigurableBeanFactory:提供配置Factory的各种方法
- ListableBeanFactory:根据各种条件获取bean的配置清单
- AbstractBeanFactory:综合FactoryBeanRegistrySupport和ConfigurableBeanFactory的功能
- AutowireCapableBeanFactory:提供创建bean、自动注入、初始化以及应用bean的后处理器
- AbstractAutowireCapableBeanFactory:综合AbstractBeanFactory并对接口AutowireCapableBeanFactory进行实现
- ConfigurableListableBeanFactory:BeanFactory配置清单,指定忽略类型及接口等
- DefaultListableBeanFactory:综合上面所有功能,主要是对bean注册后的处理
XmlBeanFactory对DefaultListableBeanFactory类进行了扩展,主要用于从XML文档中读取BeanDefinition,对于注册及获取Bean都是使用父类DefaultListableBeanFactory继承的方法实现。
1.4.1.2 XmlBeanDefinitionReader
XML配置文件的读取时Spring中重要的功能,因为Spring的大部分功能都是以配置作为切入点的。我们可以从XmlBeanDefinitionReader中梳理一下资源文件读取、解析及注册的大致流程:
- ResourceLoader:定义资源加载器,主要应用于根据给定的资源文件地址返回对应的Resource
- BeanDefinitionReader:主要定义资源文件读取并转换为BeanDefinition的各个功能
- EnvironmentCapable:定义获取Environment方法
- DocumentLoader:定义从资源文件加载到转换为Document的功能
- AbstractBeanDefinitionReader:对EnvironmentCapable、BeanDefinitionReader类定义的功能进行实现
- BeanDefinitionDocumentReader:定义读取Document并注册BeanDefinition功能
- BeanDefinitionPaserDelegate:定义解析Element的各种方法。
经过上述分析,梳理出整个XML配置文件读取的大致流程如下:
- 通过继承自AbstractBeanDefinitionReader中的方法,来使用ResourceLoader将资源文件路径转换为对应的Resource文件
- 通过DocumentLoader对Resource文件进行转换,将Resource文件转换为Document文件
- 通过实现接口BeanDefinitionDocumentReader的DefaultBeanDefinitionDocumentReader类对Document进行解析,并使用BeanDefinitionParserDelegate对Element进行解析
1.5 容器的基础XmlBeanFactory
如下,是我们实现的代码:
BeanFactory beanFactory = new XmlBeanFactory(new ClassPathResource("beanFactoryTest.xml"));
如下,是XmlBeanFactory的初始化时序图:
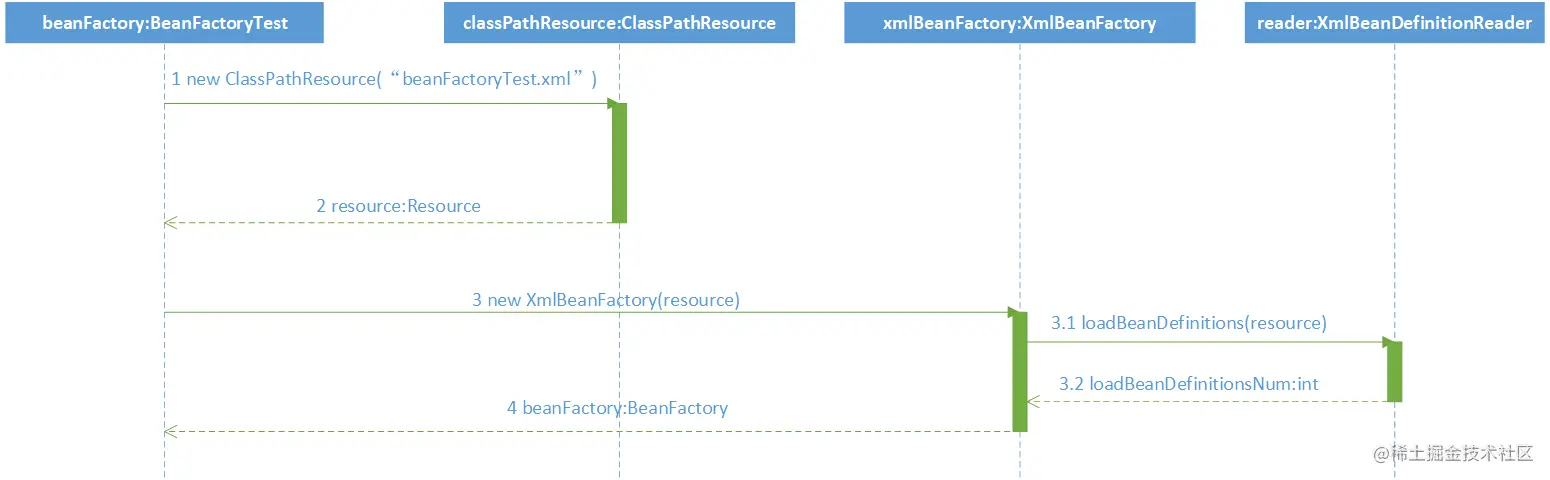
时序图从BeanFactoryTest测试类开始。首先调用ClassPathResource的构造函数来构造Resource资源文件的实例对象,这样后续的资源处理可以用Resource提供的各种服务来操作,当有了Resource后就可以进行XmlBeanFactory的初始化了。
1.5.1 配置文件封装
Spring的配置文件读取是通过ClassPathResource进行封装的,如 new ClassPathResource("beanFactoryTest.xml") 。
在Java中,将不同来源的资源抽象成URL,通过注册不同的handler(URL StreamHandler)来处理不同来源的资源的读取逻辑,一般handler的类型使用不同前缀(协议,Protocol)来识别,如“file:”、“http:”、“jar:”等,然而URL没有默认定义相对Classpath或ServletContext等资源的handler,虽然可以注册自己的URLStreamHandler来解析特定的URL前缀(协议),比如“classpath:”,然而这需要了解URL的实现机制,而且URL也没有提供一些基本的方法,如检查当前资源是否存在、检查当前资源是否可读等方法。因而Spring对其内部使用到的资源实现了自己的抽象封装:Resource接口来封装底层资源:
public interface InputStreamSource {
InputStream getInputStream() throws IOException;
}
public interface Resource extends InputStreamSource {
boolean exists();
default boolean isReadable();
default boolean isOpen();
URL getURL() throws IOException;
URI getURI() throws IOException;
File getFile() throws IOException;
long lastModified() throws IOException;
Resource createRelative(String relativePath) throws IOException;
String getFilename();
String getDescription();
}
InputStreamSource封装任何能返回InputStream的类,比如File、Classpath下的资源和Byte Array等。它有一个方法定义:getInputStream(),该方法返回一个新的InputStream对象。
Resource接口抽象了所有Spring内部使用到的底层资源:File、URL、Classpath等。首先,它定义了3个判断当前资源状态的方法:存在性(exists)、可读性(isReadable)、是否处于打开状态(isOpen) 。另外,Resource接口还提供了不同资源到URL、URI、File类型的转换,以及获取lastModified属性、文件名的方法。
对于不同来源的资源文件都有相应的Resource实现:文件(FileSystemResource)、Classpath资源(ClassPathResource)、URL资源(UrlResource)、InputStream资源(InputStreamResource)、Byte数组(ByteArrayResource)等。其类图如下:
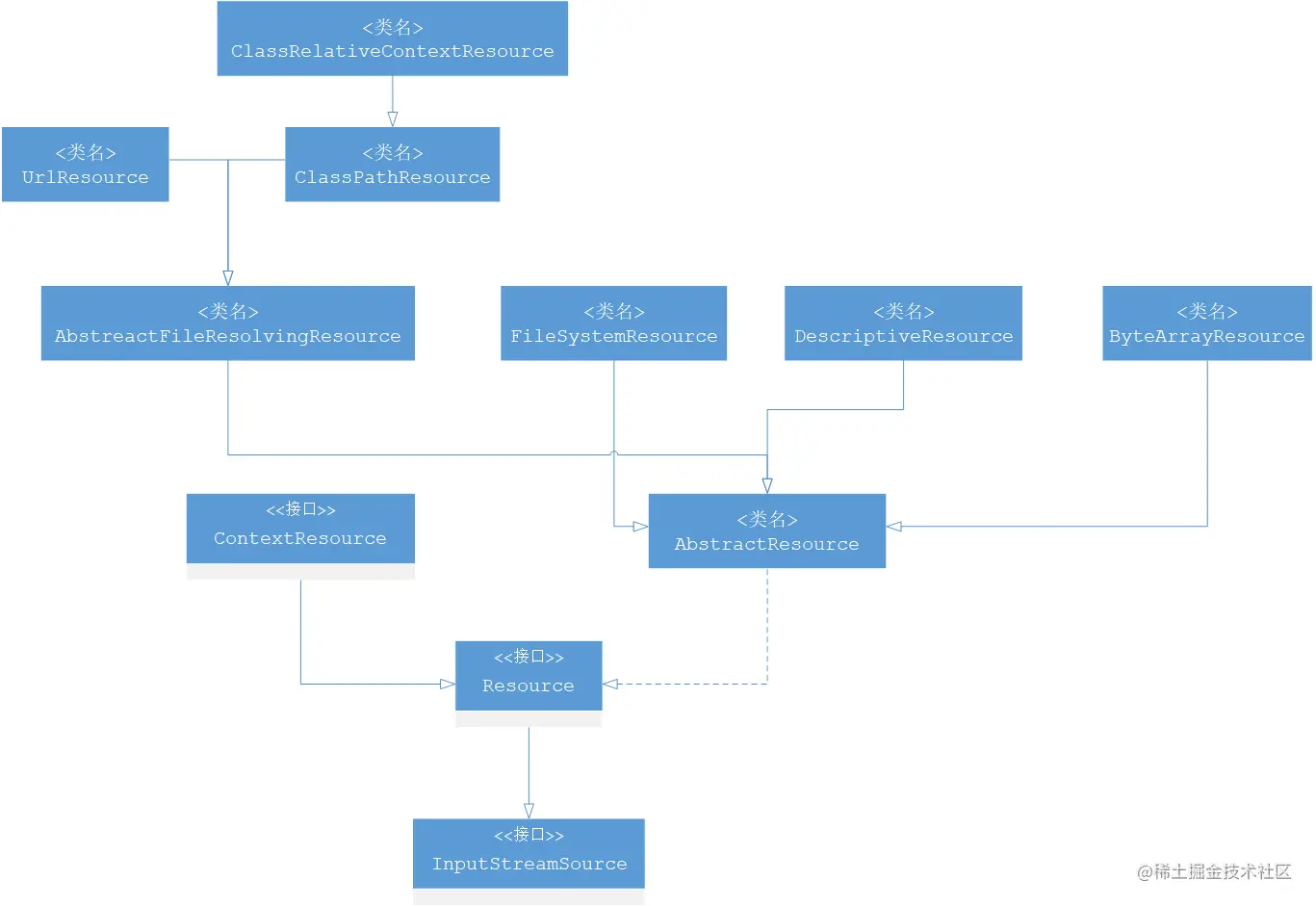
其实在日常的开发工作中,资源文件的加载也是能用到的,可以直接使用Spring提供的类,比如在希望加载文件时可以使用以下代码:
Resource resource = new ClassPathResource("beanFactoryTest.xml");
InputStream inputStream = resource.getInputStream();
有了Resource接口便可以对所有资源文件进行统一处理。至于实现,其实非常简单,以getInputStream为例, ClassPathResource中的实现方式便是通过class或者classLoader提供的底层方法进行调用,而对于FileSystemResource的实现其实更简单,直接使用FileInputStream对文件进行实例化 。
ClassPathResource#getInputStream()代码如下:
@Override
public InputStream getInputStream() throws IOException {
InputStream is;
if (this.clazz != null) {
is = this.clazz.getResourceAsStream(this.path);
} else if (this.classLoader != null) {
is = this.classLoader.getResourceAsStream(this.path);
} else {
is = ClassLoader.getSystemResourceAsStream(this.path);
}
if (is == null) {
throw new FileNotFoundException(getDescription() + " cannot be opened because it does not exist");
}
return is;
}
FileSystemResource#getInputStream()代码如下:
@Override
public InputStream getInputStream() throws IOException {
try {
return Files.newInputStream(this.filePath);
} catch (NoSuchFileException ex) {
throw new FileNotFoundException(ex.getMessage());
}
}
当通过Resource相关类完成了对配置文件进行封装后配置文件的读取工作就交给了XmlBeanDefinitionReader来处理了。
XmlBeanFactory的初始化有很多方法,Spring提供了很多构造函数,在这里分析的是使用Resource实例作为构造函数参数的办法,代码如下:
/**
* 通过给定的资源创建一个XmlBeanFactory
* @param resource 配置文件资源
* @throws BeansException Bean异常
*/
public XmlBeanFactory(Resource resource) throws BeansException {
//调用XmlBeanFactory(Resource, BeanFactory)的构造方法
this(resource, null);
}
/**
* 构造函数
* @param resource XML流资源
* @param parentBeanFactory 父BeanFactory, 用于factory合并, 可以为空
* @throws BeansException Bean异常
*/
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException {
super(parentBeanFactory);
this.reader.loadBeanDefinitions(resource);//加载资源
}
上面函数代码: this.reader.loadBeanDefinitions(resource)才是资源加载的真正实现 。通过时序图可以看到XmlBeanDefinitionReader加载数据就是在这里完成的,但是XmlBeanDefinitionReader加载数据前还有一个调用父类构造函数初始化的过程:super(parentBeanFactory),跟踪代码如下:
/**
* 创建一个新的AbstractAutowireCapableBeanFactory
*/
public AbstractAutowireCapableBeanFactory() {
super();
ignoreDependencyInterface(BeanNameAware.class);//忽略BeanNameAware
ignoreDependencyInterface(BeanFactoryAware.class);//忽略BeanFactoryAware
ignoreDependencyInterface(BeanClassLoaderAware.class);//忽略BeanClassLoaderAware
}
ignoreDependencyInterface()方法主要功能是忽略给定接口的自动装配功能。
举例来说,当A中有属性B,那么当Spring在获取A的Bean的时候如果其属性B还没有初始化,那么Spring会自动初始化B,这也是Spring提供的一个重要特性。但是,某些情况下,B不会被初始化,其中的一种情况就是B实现了BeanNameAware接口。Spring是这样介绍的: 自动装配忽略给定的依赖接口,典型应用是通过其他方式解析Application上下文注册依赖,类似于BeanFactory通过BeanFactoryAware进行注入或者ApplicationContext通过ApplicationContextAware进行注入 。
1.5.2 加载Bean
之前提到的在XmlBeanFactory构造函数中调用了XmlBeanDefinitionReader类型的reader属性提供的方法:this.reader.loadBeanDefinitions(resource),而这句代码则是整个资源加载的切入点,如下是这个方法的时序图:
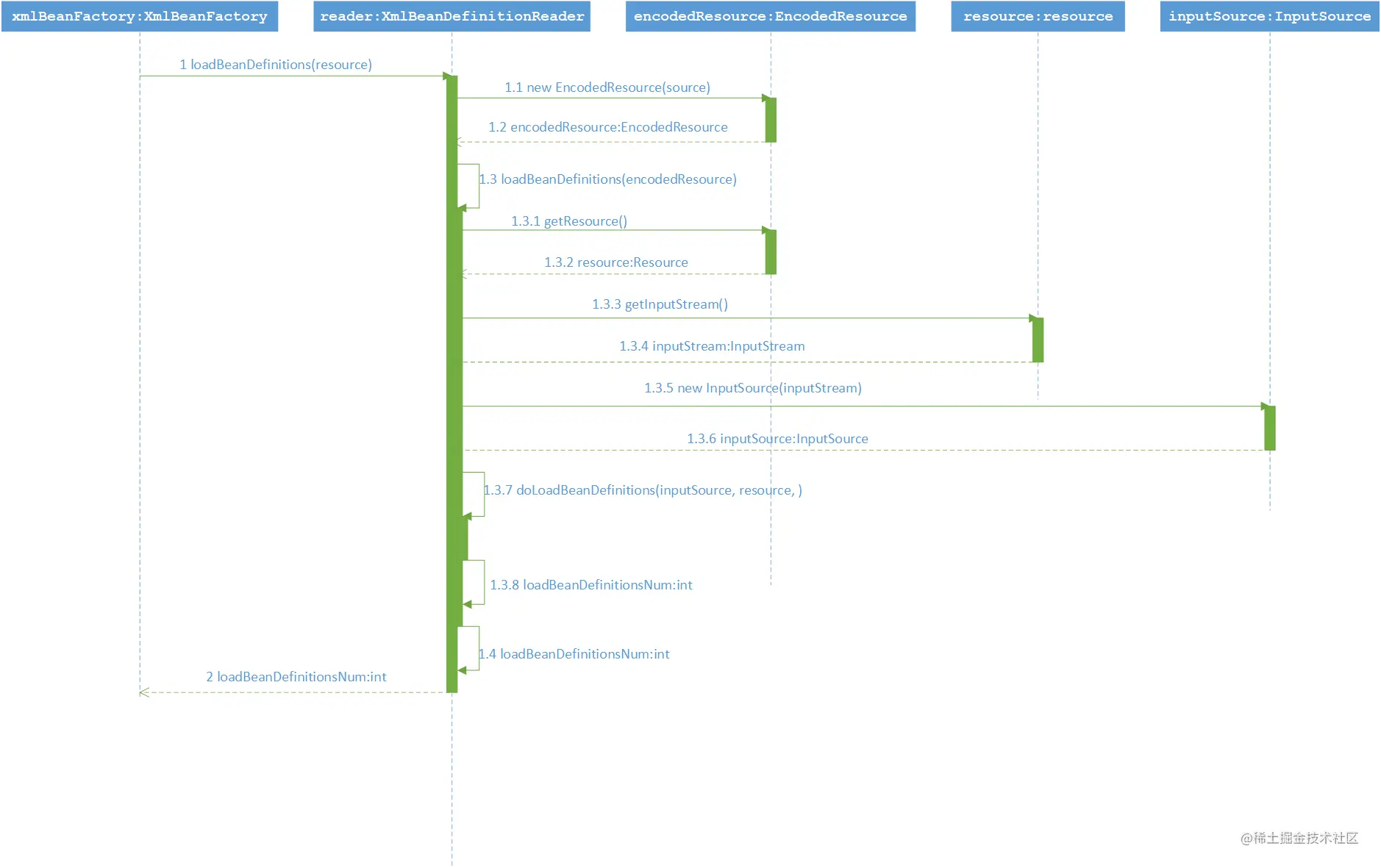
- 首先封装资源文件。当进入XmlBeanDefinitionReader后首先对参数Resource使用EncodedResource类进行封装
- 获取输入流,从Resource中获取对应的InputStream并构造InputSource
- 通过构造的InputSource实例和Resource实例继续调用函数doLoadBeanDefinitions
如下,loadBeanDefinitions函数具体的实现过程:
/**
* 从XML资源文件中加载Bean
* @param resource XML文件
* @return 找到的Bean数量
* @throws BeanDefinitionStoreException Bean存储异常
*/
@Override
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
return loadBeanDefinitions(new EncodedResource(resource));
}
其实我们可以简单推断这个类是对资源文件的编码进行处理的。主要的逻辑体现在getReader()方法中,当设置了编码属性的时候Spring会使用相应的编码作为输入流的编码:
/**
* 获取Reader流, 主要是进行编码的一些处理
* @return Reader
* @throws IOException IO异常
*/
public Reader getReader() throws IOException {
if (this.charset != null) {
return new InputStreamReader(this.resource.getInputStream(), this.charset);
} else if (this.encoding != null) {
return new InputStreamReader(this.resource.getInputStream(), this.encoding);
} else {
return new InputStreamReader(this.resource.getInputStream());
}
}
上面的代码构造了一个由编码(encoding)的InputStreamReader。当构造好encodedResource对象后,再次转入了方法loadBeanDefinitions(new EncodedResource(resource))。
/**
* 从XML资源文件中加载Bean
* @param resource 已经编码过的XML文件
* @return 找到的Bean数量
* @throws BeanDefinitionStoreException Bean存储异常
*/
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isTraceEnabled()) {
logger.trace("Loading XML bean definitions from " + encodedResource);
}
//获取已经加载的资源
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
//如果已经存在的资源, 则直接抛出异常 Start
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
//如果已经存在的资源, 则直接抛出异常 End
//从encodedResource中获取已经封装的Resource对象并再次从Resource对象中获取inputStream
try (InputStream inputStream = encodedResource.getResource().getInputStream()) {
InputSource inputSource = new InputSource(inputStream);//这个InputSource是XML的, 不是Spring的
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
//核心逻辑(真正的加载逻辑)
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
} catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
} finally {
currentResources.remove(encodedResource);//清除资源
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
首先对传入的resource参数做封装,目的是考虑到Resource可能存在编码要求的情况,其次,通过SAX读取XML文件的方式来准备InputSource对象,最后将准备的数据通过参数传入真正的核心处理部分:doLoadBeanDefinitions(inputSource, resource),其代码如下:
/**
* 从XML资源文件中真正加载Bean的定义
* @param inputSource SAX的输入源
* @param resource XML资源文件
* @return 已经找到的Bean的数量
* @throws BeanDefinitionStoreException 加载或者解析错误
*/
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource) throws BeanDefinitionStoreException {
try {
//获取XML文件的验证模式, 加载XML文件, 并得到对应的Document Start
Document doc = doLoadDocument(inputSource, resource);
//获取XML文件的验证模式, 加载XML文件, 并得到对应的Document End
//注册Document, 并返回已经注册的Bean数量 Start
int count = registerBeanDefinitions(doc, resource);
//注册Document, 并返回已经注册的Bean数量 End
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + count + " bean definitions from " + resource);
}
return count;
} catch (BeanDefinitionStoreException ex) {
throw ex;
} catch (SAXParseException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"Line " + ex.getLineNumber() + " in XML document from " + resource + " is invalid", ex);
} catch (SAXException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"XML document from " + resource + " is invalid", ex);
} catch (ParserConfigurationException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Parser configuration exception parsing XML from " + resource, ex);
} catch (IOException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"IOException parsing XML document from " + resource, ex);
} catch (Throwable ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Unexpected exception parsing XML document from " + resource, ex);
}
}
上面的代码做了几件事:
- 加载XML文件,并得到对应的Document
- 根据返回的Document注册Bean信息
在加载XML文件,得到Document时,需要进行XML的验证(DTD与XSD验证),具体这里的验证模式就不做过多介绍,可自行研究。
1.6 解析及注册BeanDefinitions
从上面的doLoadBeanDefinitions()方法可以发现,获取到Document对象后,就是解析和注册BeanDefinitions了(registerBeanDefinitions()),这个是主要的核心方法,代码如下:
/**
* 注册给定Document中的Bean的实例。该方法是从loadBeanDefinitions这个方法调用进来的
* @param doc Document
* @param resource XML资源文件
* @return 已经存在的Bean的数量
* @throws BeanDefinitionStoreException Bean存储异常
*/
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
//使用DefaultBeanDefinitionDocumentReader实例化BeanDefinitionDocumentReader
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
//记录统计前Bean的加载数量
int countBefore = getRegistry().getBeanDefinitionCount();
//加载及注册Bean
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
//返回本次加载的Bean的数量
return getRegistry().getBeanDefinitionCount() - countBefore;
}
在这个方法中将逻辑处理委托给单一的类进行处理,这个类就是BeanDefinitionDocumentReader。BeanDefinitionDocumentReader是一个接口,而 实例化的工作是在createBeanDefinitionDocumentReader()中完成的,而通过此方法,BeanDefinitionDocumentReader真正的类型其实已经是DefaultBeanDefinitionDocumentReader了 ,进入BeanDefinitionDocumentReader后,发现这个方法的重要目的之一就是提取root,以便于再次将root作为参数继续BeanDefinition的注册。
/**
* 注册Bean的实例。
*/
@Override
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
doRegisterBeanDefinitions(doc.getDocumentElement());
}
doRegisterBeanDefinitions()算是真正开始解析了,之前其实主要是准备阶段,解析XML组装相关对象的过程。
/**
* 注册XML文件中包含所有的<bean/>标签的Bean
* @param root root
*/
@SuppressWarnings("deprecation") // for Environment.acceptsProfiles(String...)
protected void doRegisterBeanDefinitions(Element root) {
//专门处理解析 Start
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
//专门处理解析 End
//环境处理 Start
if (this.delegate.isDefaultNamespace(root)) {
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
if (logger.isDebugEnabled()) {
logger.debug("Skipped XML bean definition file due to specified profiles [" + profileSpec +
"] not matching: " + getReaderContext().getResource());
}
return;
}
}
}
//环境处理 End
//解析前处理, 留给子类实现
preProcessXml(root);
//解析Bean
parseBeanDefinitions(root, this.delegate);
//解析后处理, 留给子类实现
postProcessXml(root);
this.delegate = parent;
}
首先对profile处理,然后开始进行解析,而preProcessXml(root)或者postProcessXml(root)代码时空的,这其实是面向继承而设计的,这两个方法就是为子类而设计的,子类如果需要在解析Bean前后做一些处理的话,就需要重新这两个方法就可以了。
1.6.1 profile属性的使用
首先在注册Bean是对PROFILE_ATTRIBUTE(profile)属性的解析,profile的用法如下:
<beans profile="dev"/>
<beans profile="production">
集成到Web环境中时,在web.xml中加入以下代码:
<context-param>
<param-name>Spring.profiles.active</param-name>
<param-value>dev</param-value>
</context-param>
有了这个特性就可以同时在配置文件中部署两套配置来适用于生产环境和开发环境,这样可以方便切换开发、部署环境。
首先程序获取了beans节点是否定义了profile属性,如果定义了则会需要到环境变量中去寻找,因为profile是可以同时指定多个,需要程序对齐拆分,并解析每个profile都符合环境变量中所定义的。
1.6.2 解析并注册BeanDefinition
处理了profile后就可以进行XML读取了,parseBeanDefinitions(root, this.delegate)代码如下:
/**
* 解析Bean定义
* @param root 根
* @param delegate bean解析的代理对象
*/
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {//解析默认标签
parseDefaultElement(ele, delegate);
} else {//解析自定义标签
delegate.parseCustomElement(ele);
}
}
}
} else {
delegate.parseCustomElement(root);
}
}
因为Spring的XML配置里面有两大类Bean声明,一种是默认的,如:
<bean id="test" class="test.TestBean"/>
另一个就是自定义的,如:
<tx:annotation-driven>
这两种方式的读取及解析差别是非常大的,如果采用Spring默认的配置,Spring知道该怎么做,但是如果是自定义的,那么就需要用户实现一些接口及配置了。
对于根节点或者子节点如果是默认命名空间的话则采用 parseDefaultElement 方法进行解析,否则使用 delefate.parseCustomElement 方法对自定义命名空间进行解析。
而判断是否默认命名空间还是自定义命名空间的办法其实使用node.getNamespaceURI()获取命名空间,并与Spring中固定的命名空间(www.Springframework.org/schema/bean…) 进行对比。如果一直则认为是默认,否则就认为是自定义。