为什么要有垃圾回收器
没有GC的世界
对于从事开发工作以来,只接触过等Java、Python等语言的人来说,虚拟机和垃圾回收器不是与生俱来、天经地义的吗?
其实并不是的,对于C或C++程序猿来说,自己需要的时候手动分配内存,使用完毕自己释放内存,这才是常态(自己动手,丰衣足食)。那既然可以自己操作,为啥还要搞一个垃圾回收器呢?自己掌控全局不好吗? 好!但是没必要 。 在进行开发工作时,大部分时候程序员关注的都是在逻辑上, 垃圾回收器就是为了让你可以在开发过程中只关注逻辑,而不要去考虑繁琐的内存管理。
GC帮我们做了什么
那既然开发者不需要管理内存了,每次创建对象都由虚拟机来分配内存, 但是内存不是无限的 ,我们需要有一个东西来帮我们清理那些不再使用的对象来释放内存,这个东西都是垃圾回收器。说得简单一点,它其实只做两件事情:
- 怎么找到这些可回收的对象:找到内存中非活动对象的内存地址
- 如何回收这些对象:释放内存,让程序可以再次利用

当Java开发回家陪女朋友的时候,C++开发还公司挠破头皮:到底是哪里忘记释放内存导致程序Crash了呢?
垃圾回收算法的演进
GC起源
 很多人谈到GC,可能第一反应Java/Python等,虽然垃圾回收技术确实通过这些语言让大家所熟知,但是第一个实现GC的确是Lisp语言。早在60年前的1960年,Lisp之父John McCarthy已经在其论文中发布了GC算法,Lisp语言也是第一个实现GC的语言。
很多人谈到GC,可能第一反应Java/Python等,虽然垃圾回收技术确实通过这些语言让大家所熟知,但是第一个实现GC的确是Lisp语言。早在60年前的1960年,Lisp之父John McCarthy已经在其论文中发布了GC算法,Lisp语言也是第一个实现GC的语言。
Lisp还有很多超前的设计,除了垃圾回收,还包括:函数式编程、变量的动态类型等等。
标记清除
1960年由John McCarthy提出,主要通过标记、清除两步操作来回收垃圾对象
【标记】如何标记需要回收的对象?
要清除对象,那么我们首先需要定义:哪些对象是可以被回收的。反向思考一下,如果我们可以知道哪些对象是活跃的/正在被使用的(或可以被使用),那么除去这些活跃对象以外的其它对象都是可以被回收的。这就是标记清除算法中的标记过程:可达性分析。
可达性分析
可达性分析粗略来看,主要分为两个步骤:
-
确定Root节点:直接活跃在线程上的对象
- 静态属性或常量引用的对象
- 活跃的线程(栈变量、方法参数等)
-
遍历所有对象,标记为可达(大部分为深度优先遍历)
在遍历完成所有对象之后,所有 未被标记为可达的对象 都将被回收
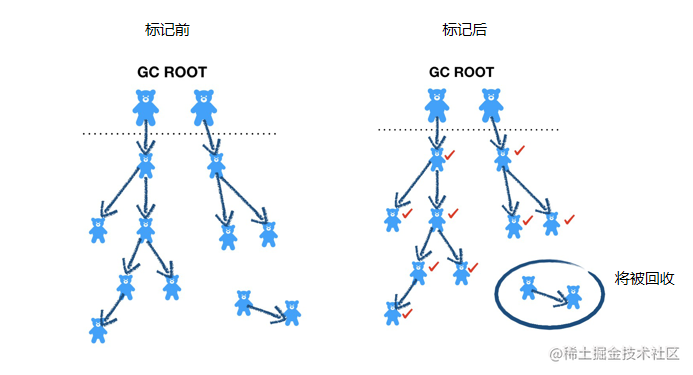
【清除】标记之后如何回收这些对象?
标记成功之后,会再次遍历所有对象,回收所有被标记为可达的对象。
整个标记清除算法简单来说用下图表示:
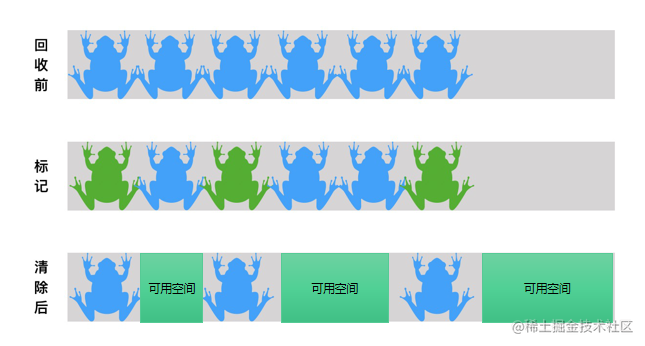
从上面可以看到,标记清除算法有一个很明显的缺点,那就是内存碎片化过多。很可能出现的一个场景是:当虚拟机需要为一个大对象分配内存,内存总量是足够的,但是没有足够大的连续空间。因此后面基本标记清除又提出了一个新的算法: 标记整理 。标记整理也是两步:
- 先进行可达性分析
- 不再直接清除所有未标记的对象,而是先对所有存活对象接内存地址排序,再将最后一个存活对象之后的内存空间全部回收。解决内存碎片问题
标记整理:

引用计数
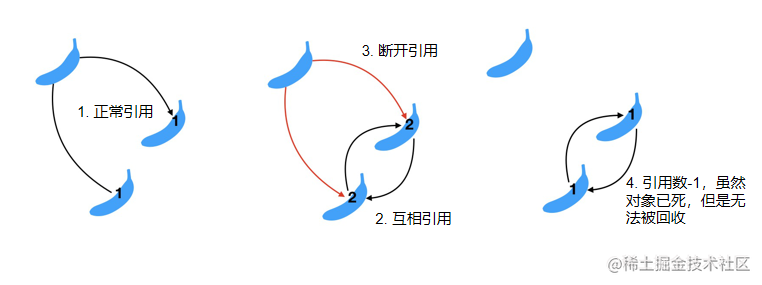
1960年由George E. Collins提出,主要通过对象的被引用数来回收对象
引用计数的原理说起来比较简单:在对象头中存储引用计数,在对象被引用时+1,取消引用时-1,当计数为0时,回收对象。

问题:循环引用
分区复制
1963年由Marvin L. Minsky提出,通过内存分区、复制来回收对象
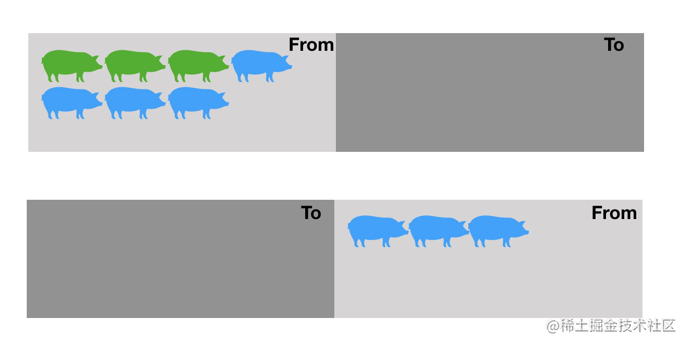
在使用分区复制算法时内存里面一般有两片内存区域:一片是是活跃区域,里面有我们分配的各种对象,另一片是空闲区。
当进行GC时,也是分两步进行:
- 标记活跃区域的存活内存对象
- 将活跃区域的存活对象复制到空闲区域,并清空原活跃区域
优劣对比
| 回收算法 | 优点 | 缺点 |
|---|---|---|
| 标记清除 | 实现简单 | 产生碎片回收效率低 |
| 标记整理 | 不会生产内存碎片 | 整理部分较复杂回收效率低 |
| 引用计数 | 停顿时间短(大部分情况)可以即时回收垃圾 | 需要额外的计数操作对象需要存储额外的计数信息存在循环引用的问题 |
| 分区复制 | 分配效率高大部分时候回收效率快不会产生碎片 | 内存使用率低存活对象多的话回收效率降低(大量复制) |
从上面我们可以看到,每个回收算法都有自己的优劣,没有一个算法是完美的。这时候就有聪明人会想:我可不可以想办法把他们进行结合,从而可以利用这些算法的优点,而尽量避免他们的缺点呢?这是就我们下面要说到的 分代收集
分代收集
人们从大量的程序中,总结出来一个经验:大部分的对象在生成后马上就变成了垃圾,很少有对象能活得很久。数十年来,基本上所有编程语言都表现出来了这种一致性。由此,在1984年,David Ungar在他的一篇论文中提出了分代收集的理论。
分代收集的核心:
-
堆分为生成空间(分配内存的位置)、2个大小相等的幸存空间(From和To)以及老年代空间。
-
记录集用于记录老年代指向新生代的引用,为了便于高效的寻找从老年代到新生代的引用。
-
对象需要增加三个字段:
- age:对象年龄
- forwarded:已经复制完毕的标志
- remembered:已经向记录集记录完毕的标志
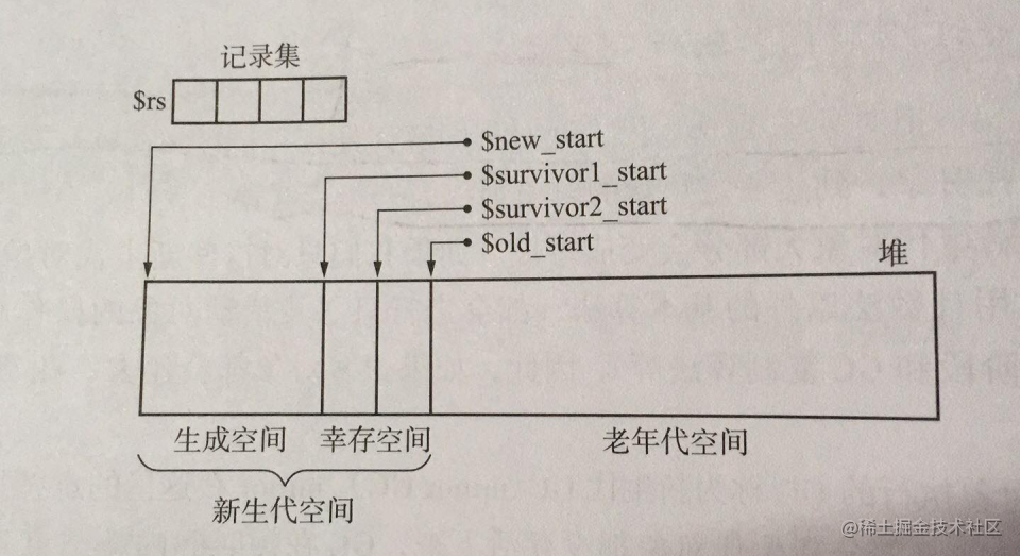
一看到两个相等的幸存空间是不是想到了 复制算法? 分代收集的新生代确实是使用复杂算法,完美的契合了复制算法的特性:分配效率高、回收效率快。同时大概率的规避的它的缺点:在存活对象多的时候回收效率低(在大部分时候新生对象的存活率都很低。长期活跃对象都被晋升到老年代了)
分代收集的优缺点
优点
- gc吞吐量提升
- 分配内存效率提升
- 大部分时候停顿时间短
缺点
- 实现复杂,不同分代互相引用
- 在违反了基本假设时,效率反而会更低
JAVA中的垃圾回收器
| do | xi | do | la |
|---|---|---|---|
| 新生代 | Serial 复制算法串行 | ParNew 复制算法并行可以和CMS配置使用 | ParalletScavenge 复制算法并行吞吐量优先GC自适应调节策略 |
| 老年代 | SerialOld 标记整理串行CMS后备方案,出现ConcurrentModeFailure时使用 | ParalletOld 标记整理并行可以和ParalletScavenge配合,用于吞吐量优先和CPU敏感场合 | CMS 并发标记清除低停顿时间优先CPU资源敏感,并发会占用用户程序CPU |
上面只列出了常规情况下大部分程序使用的垃圾回收器。对于G1和ZGC大家如果感兴趣可以自行了解。
如何评估垃圾回收对程序的影响
下面我们通过一个简单的公式计算一下GC对我们应用程序的影响,评估当前的GC频率是否是合理的
GC对请求的影响:
(响应时间+GC时间)* 时间范围内GC次数 / T
怎么理解呢?我们先看一个图:
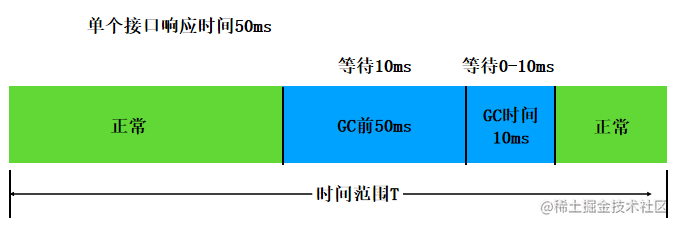
假设我们每个接口正常的响应时间是50ms,每次GC需要停顿10ms
那么如果在单位时间T内,发生了一次GC,那么在GC开始前的50ms内到达的请求响应时间都会增加10ms,而在GC期间到达的请求响应时间都会增加0~10ms不等。 因此GC对请求的影响 = (响应时间+GC时间)* 时间范围内GC次数。
举个栗子:
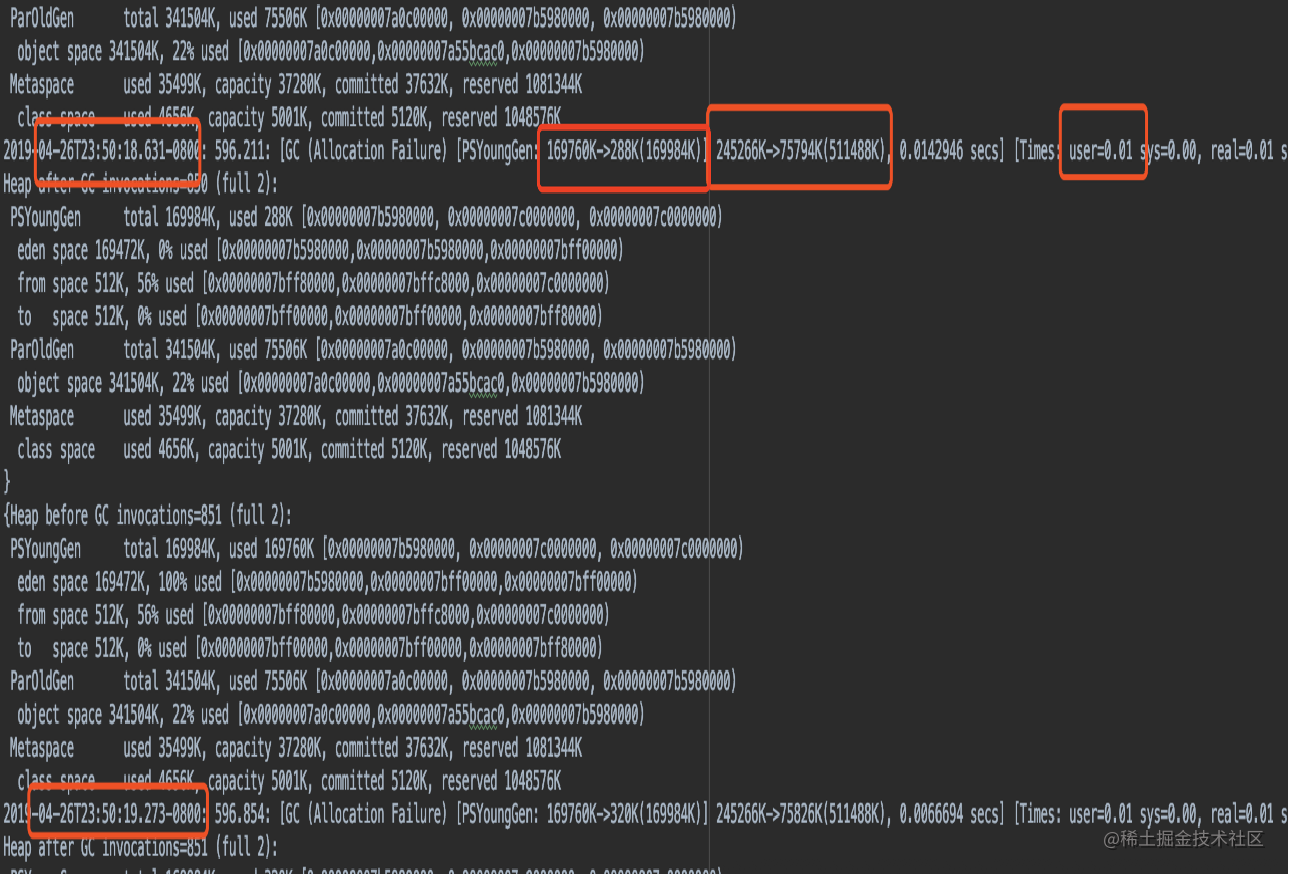 我们可以先看一下上面的GC日志
我们可以先看一下上面的GC日志
怎么看懂GC日志这里不详细展开,大家这么聪明,自行Google一下就明白了。
可以看到两次GC之间的间隔差不多为600ms(估算每分钟GC100次),每次耗时0.01s = 10ms
那么我们按一分钟来进行计算的话:
(50ms + 10ms) * 100 / 60000 = 0.1
即每分钟会有10%的请求受到GC的影响。
那如果我们需要进行优化,减少GC对请求的影响应该怎么做呢? 看公式就知道:
- 降低单次GC的时间
- 降低单位时间内GC的次数
总结
上面我们聊了为什么要有GC和GC的各种GC算法,知道他们的优缺点以及他们在HotSpot中的实现,最后还简单了解了一下如何快速评估GC对应用程序的影响。 希望可以帮助大家简单的了解垃圾回收到底是什么东西。如果引发大家的兴趣,并且自己去深入分析细节,那就更好不过了!
【重要】转载请注明出处:https://juejin.cn/post/6857391504907436040