CMS
Concurrent Mark Sweep 并发标记清除 垃圾回收期
CMS 使用在老年代回收一般触发为FGC
使用 -XX:+UseConcMarkSweepGC 使用CMS 老年代垃圾回收器 ,默认会使用ParNew做为新生代垃圾回收器,ParNew跟Serial差不多 只是将单线程变成了多线程
CMS也是采用三色标记的算法 对数据进行标记处理,CMS采用标记清除的方式清理垃圾且CMS作用于老年代的垃圾回收
并发垃圾回收器步骤
并发收集周期通常包括以下步骤 :
- 暂停所有应用线程线程(STW),确定第一层根可达对象集,恢复所有应用线程
- 在应用线程执行的同时,并发跟踪所有根可达对象集合
- 使用单线程跟踪记录 回溯上一步因并发 应用线程修改的对象引用
- 暂停应用程序线程(STW),重新标记 回溯自上次检查以来可能已修改的根和对象图的部分
- 并发清理所有无标记的 垃圾数据
- 调整堆大小并为下一个收集周期准备支持数据结构
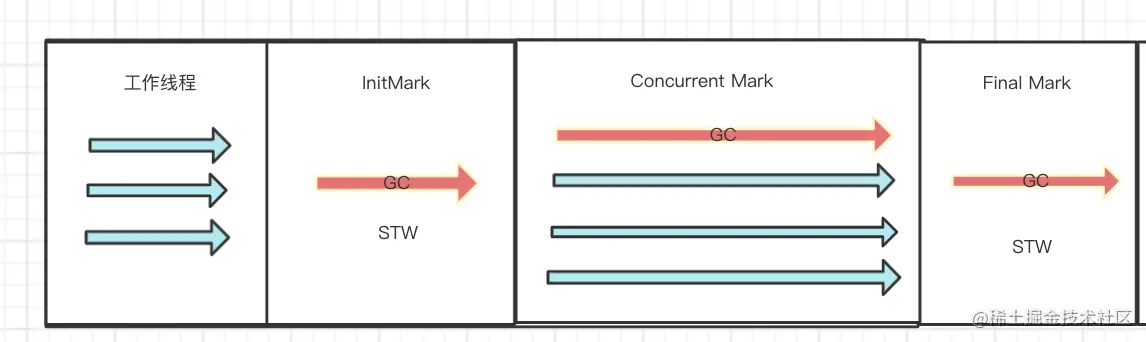
InitMark
初始标记阶段
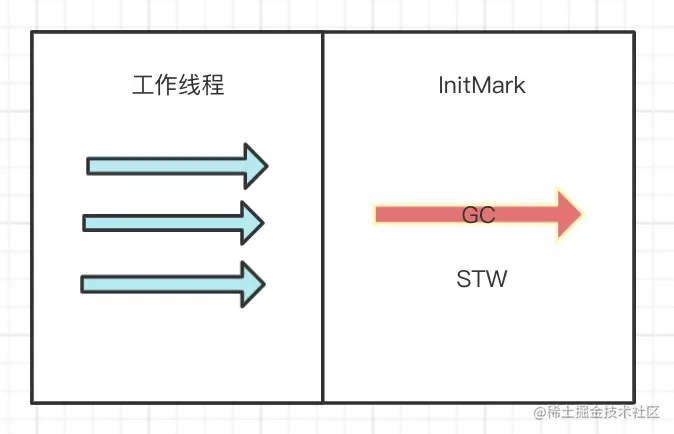 执行InitMark的时候 会触发STW 安全暂停(safePoint)所有工作线程
执行InitMark的时候 会触发STW 安全暂停(safePoint)所有工作线程
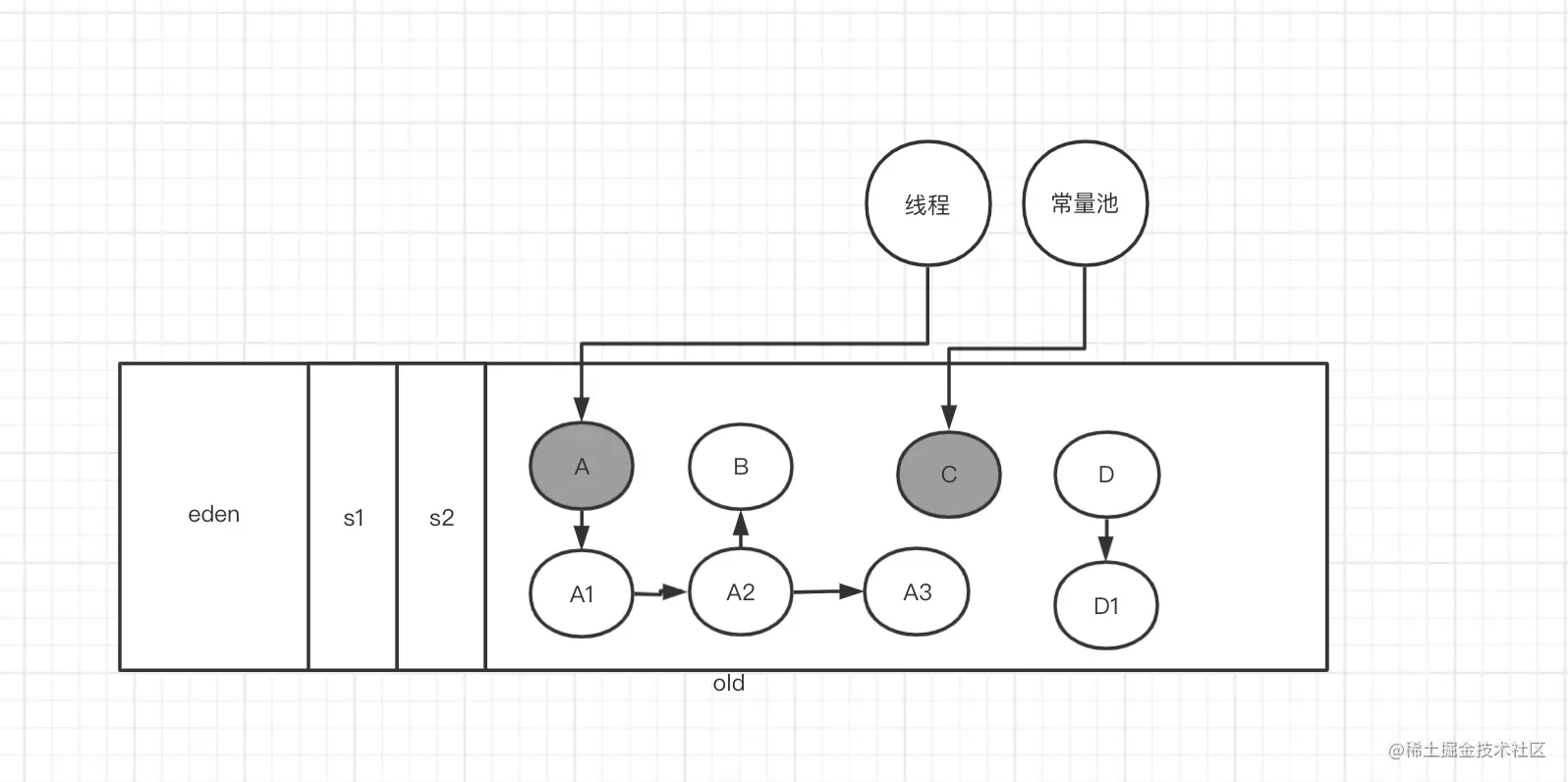 上图灰色 部分就是初始标记阶段 标记第一层根可达对象
上图灰色 部分就是初始标记阶段 标记第一层根可达对象
Concurrent Mark
并发标记阶段
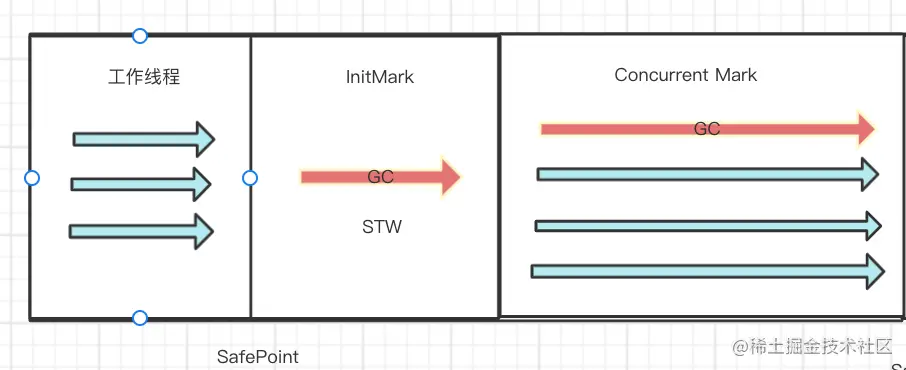 程序的工作线程会和GC线程同时运行
程序的工作线程会和GC线程同时运行
 并发标记 会从将初始阶段中标记的灰色部分 继续往下标记 寻找引用 这一块为并发标记 因为一般在标记内存中所有有用对象的时候 最为耗时 所以CMS采用在这一块使用并发减少STW停顿 并发标记时 不会产生STW停顿
并发标记 会从将初始阶段中标记的灰色部分 继续往下标记 寻找引用 这一块为并发标记 因为一般在标记内存中所有有用对象的时候 最为耗时 所以CMS采用在这一块使用并发减少STW停顿 并发标记时 不会产生STW停顿
漏标
CMS采用的是 增量写屏障的方式解决漏标问题 具体实现之前有写过CMS漏标问题
Final Mark
最终标记 我们一般称之为Remark重新标记 重新标记就是将并发标记 漏标的数据 进行重新标记, 在最终标记的时候 会产生STW暂停所有程序线程
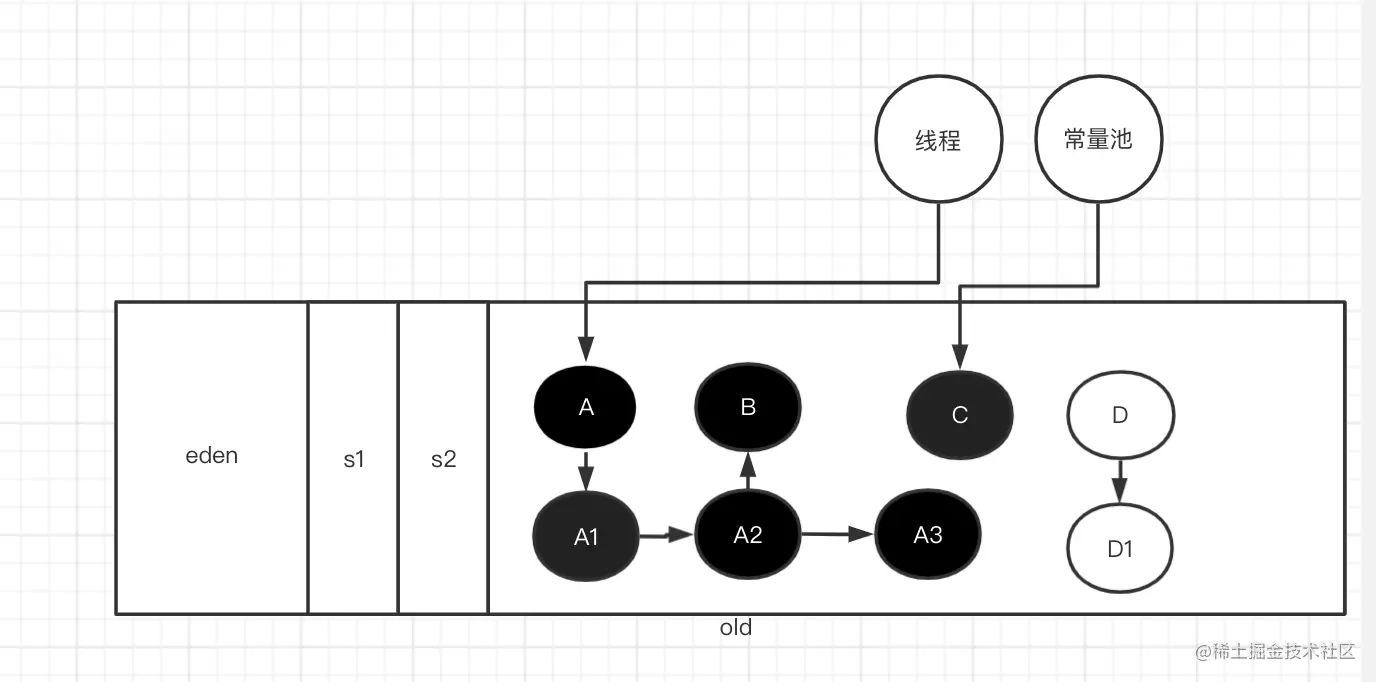
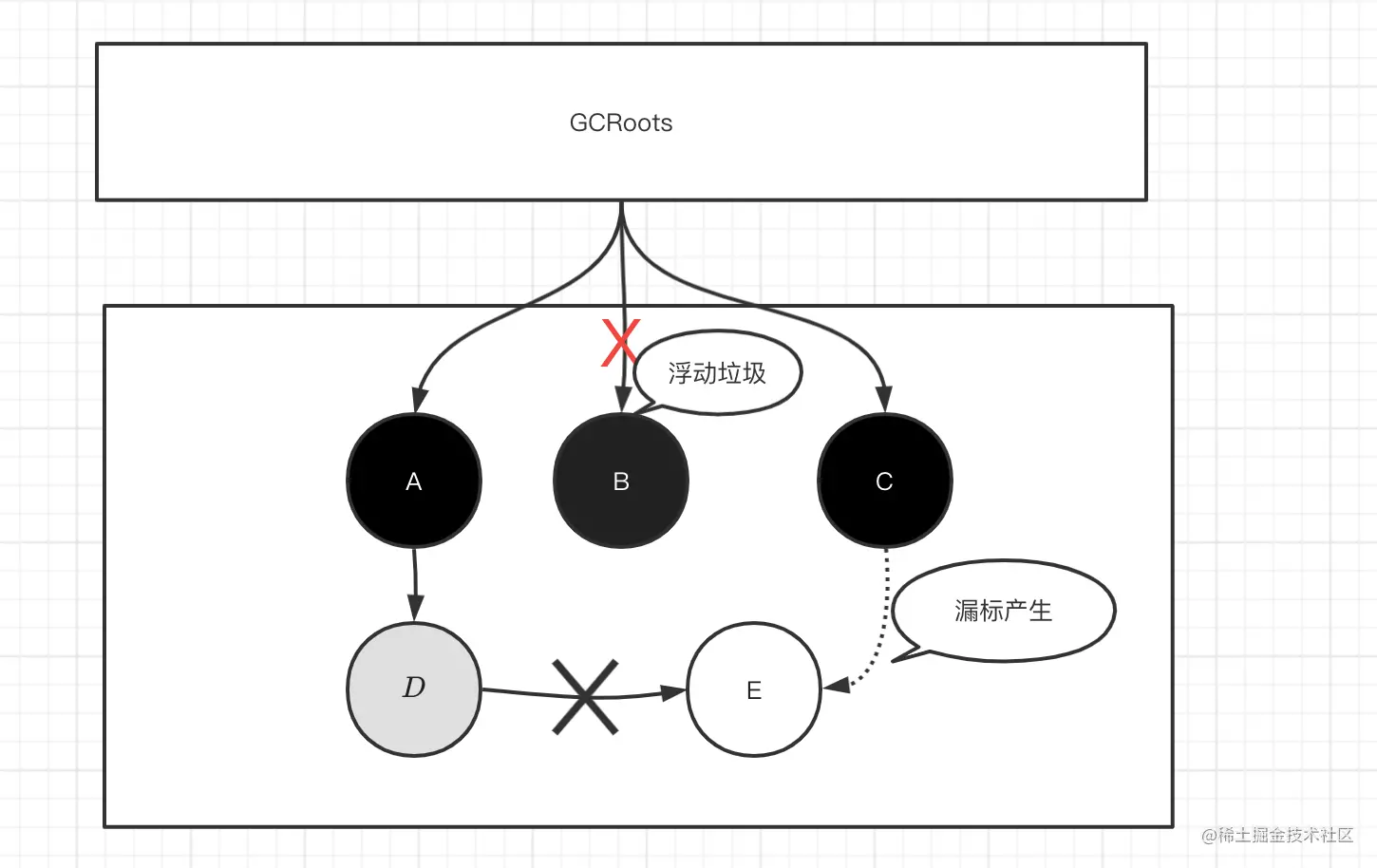
 比如之前漏标的数据有C 通过增量写屏障 已经将D变为灰色了
比如之前漏标的数据有C 通过增量写屏障 已经将D变为灰色了
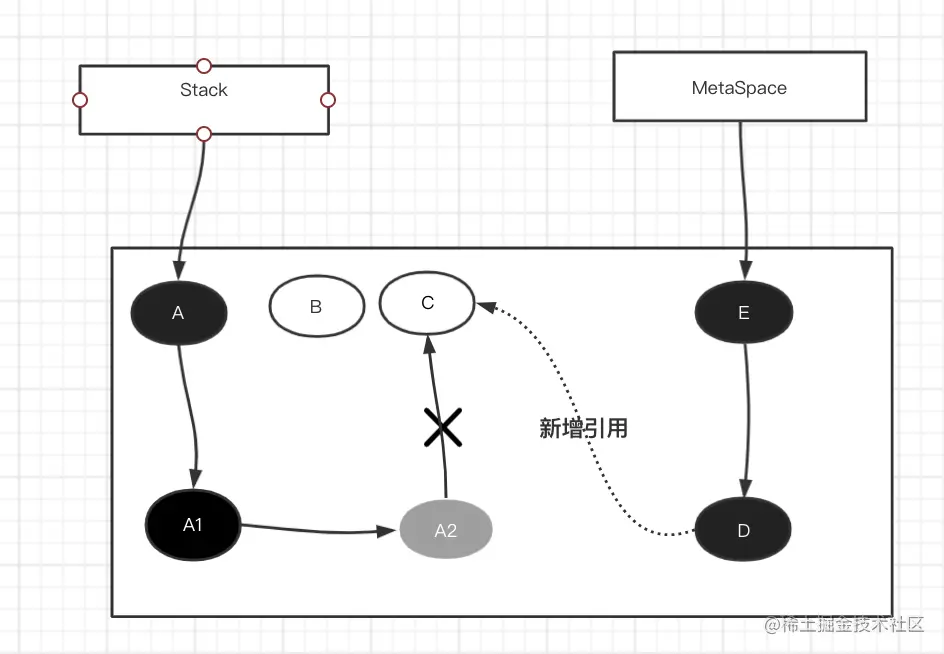
那么最终标记所完成的事情且重新扫描D所引用的对象 最终扫描完D和C以及A2
这里产生STW的时间相对较少,因为GC标记过程中最耗时的时候已经通过并发标记完成 所以在此扫描的时候只需要扫描并发标记过程中所改变的对象 相对来说STW时间很短
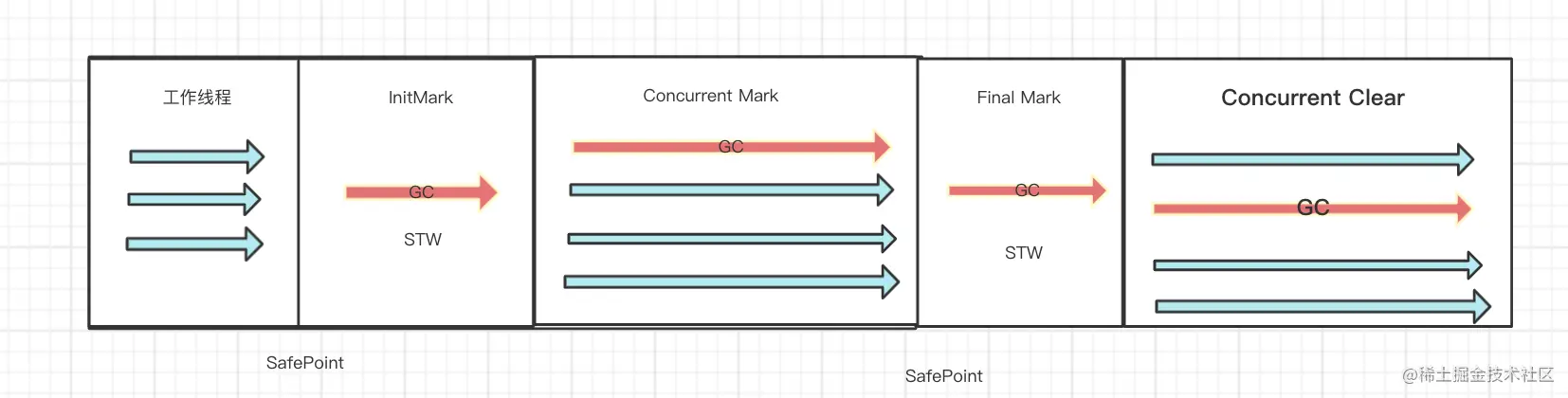
Concurrent Clear
并发清理过程,前面的步骤已经将 垃圾数据 和 非垃圾数据 通过三色标记已经区分出来了,并发清理主要为了 回收白色的数据垃圾 这个步骤不会产生STW
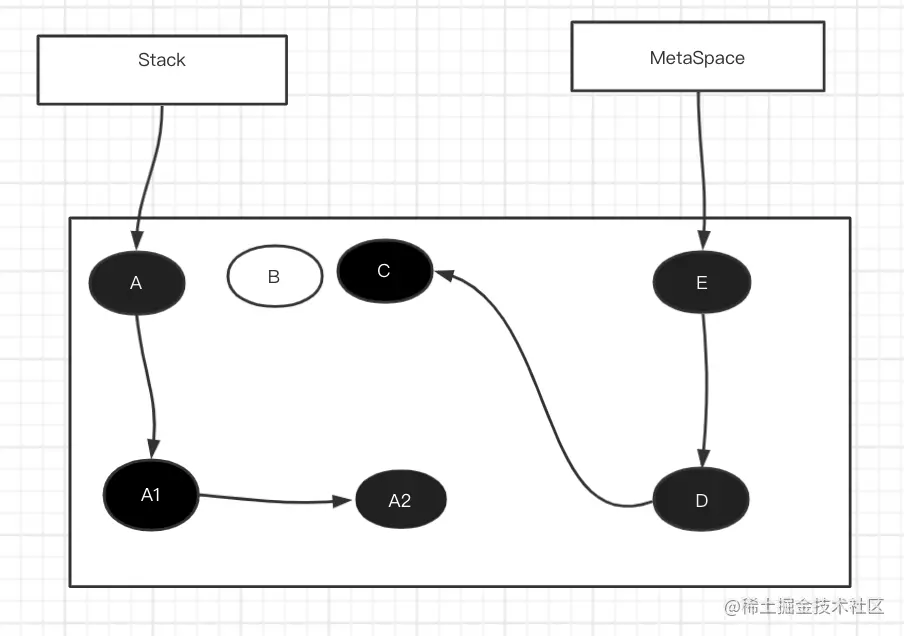
 清理将会将虚线为B的垃圾对象 回收
清理将会将虚线为B的垃圾对象 回收
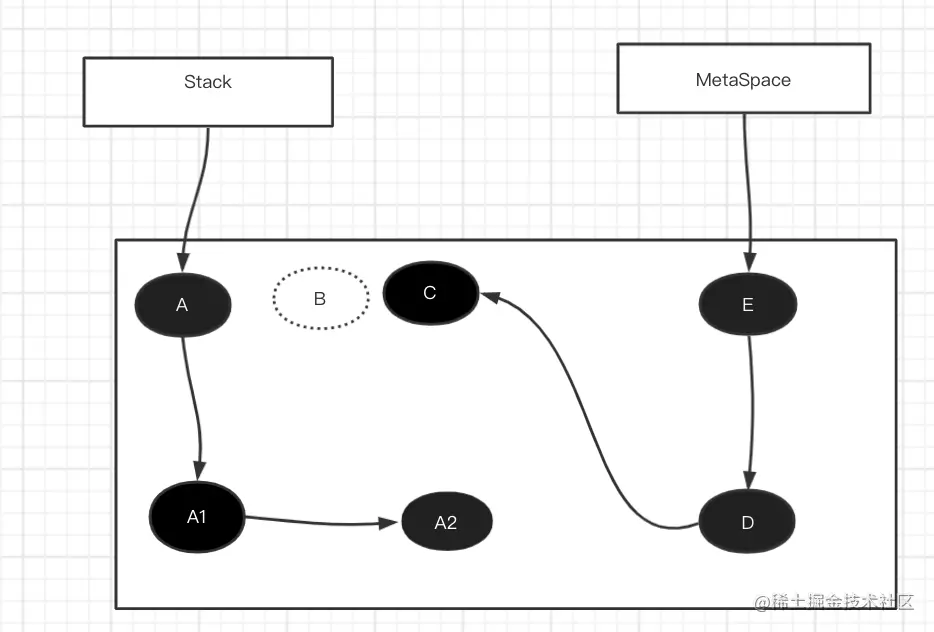
Floating Garbage
浮动垃圾 因为清理的时候采用的是并发清理 ,那么就有可能再清理的时候 又产生了新的垃圾 这个时候新垃圾 就被称之为浮动垃圾,浮动垃圾只有等下一次GC的时候 才能清理掉
CMS存在的问题
内存碎片
因为CMS采用的是 标记清除的方式,所以内存碎片会比较多,笔者之前也写过 采用标记清除的方式是需要维护一个空闲列表去分配对象 一旦最后的内存无法放入新的数据的时候(这里指的是 内存的连续空间不足以放新产生的对象的时候) CMS会使用Serial Old串行垃圾回收器 清理并且整理老年代垃圾
Serial Old垃圾回收器是单线程标记整理的垃圾回收器 所以一旦CMS采用了Serial Old方式去整理老年代垃圾,那么最后STW的时间可能无法预估,单线程串行回收且整理垃圾只适用于几M的内存大小,那么一旦老年代内存特别大 使用Serial Old 后果将不堪设想 可能会几小时 或者 更久
浮动垃圾
上面说到过漏标的问题,CMS是采用增量写屏障,增量写屏障只会记录新增加的引用 而不会记录删除的引用,比如在并发标记阶段 删除了某个GCRoots的引用,就算有重新标记但是在重新标记的时候并不知道删除了某个引用,当然在并发清理阶段再次产生的垃圾也是属于浮动垃圾
笔者之前说过产生漏标的情况
灰色对象D删除了对白色对象E的引用,同时又添加了黑色对象C对白色对象E的引用 CMS是采用增量写屏障,会记录对象C到对象E的引用 解决漏标问题,但是不会记录 GCRoots删除了对象B的引用 从而产生漏标 没有解决漏标问题
CMS 优化
一般针对于CMS的问题做优化,产生内存碎片最终导致Serial Old做压缩的 优化的方式一般提前处理老年代垃圾回收 尽可能的去避免内存碎片问题,但不能彻底解决内存碎片问题 所以Java从诞生CMS开始 到最后也从来没有将CMS垃圾回收器作为默认垃圾回收器
常见CMS调优参数
| 参数 | 描述 | 建议 |
|---|---|---|
| -XX:CMSInitiatingOccupancyFraction | 默认值是68%当老年代到68%的时候会触发CMS回收 | 这个可以根据实际业务场景决定CMS触发时间需要注意的时候这个值不能太小不然会频繁的触发CMS的GCCMS也是有2个时间段会产生STW的 |
| -XX:UseCMSInitiatingOccupancyOnly | 是否一直使用CMSInitiatingOccupancyFraction的值作为触发条件 | 只是用设定的CMSInitiatingOccupancyFraction,如果不指定CMS后续还是会自动调整 |
| -XX:CMSScavengeBeforeRemark | 在CMS的触发的时候是否执行一次YGC默认为Flase | 根据实际情况进行调整 |
| -XX:+CMSIncrementalMode | 启动增量模式 | |
| -XX:CMSFullGCsBeforeCompaction | 执行多少次FGC才会压缩老年代内存默认值为0 | 这个主要是为了预防内存碎片导致最后触发整个老年代整理 |
Promotion Failed
出现 promotion failed 一般指从年轻代 晋升至 老年代失败,一般都是内存碎片导致连续空间不足以放下新的对象数据
出现这个问题代价是非常大的,因为一般出现这个问题后都会让Serial Old 进行老年代内存整理 那么STW时间会非常长,Serial Old是一个单线程垃圾回收器 采用的是标记整理的算法
一般解决这个问题几种方式
- 提升内存但最好不要超过32G(HotSpot 会在32G以下内存的时候压缩指针)
- 提前执行cms gc
- 通过脚本的方式 再程序空闲时间执行 FGC
jmap -histo:live - 设置为
UseCMSCompactAtFullCollection、CMSFullGCsBeforeCompaction执行CMS的时候进行压缩 - 切换垃圾回收器为G1
Concurrent Mode Failure
上面说过CMS会产生浮动垃圾,CMS垃圾回收器 使用一个或多个与应用程序线程同时运行的垃圾收集器线程,目的是在年老代变满之前完成它的收集,如果在并发清理的同时无法即时回收老年代空间(浮动垃圾),并且同时程序线程又产生大量的数据导致老年代在没有清理完成的时候又再次被填满,也即是无法在老年代填满之前回收掉之前的垃圾数据,则会抛出 Concurrent Mode Failure并发收集错误 出现 Concurrent Mode Failure
解决方式 同样也是提前触发CMS回收阈值 通过修改调低CMSInitiatingOccupancyFraction的值 但是也不能太低,太低会导致频繁的FGC 比较 CMS还是会有2次STW 第二次STW的时间在一定的条件下也是会比较耗时 一般都是微调然后压测 看FGC回收的频率 以及 老年代大小
CMS被弃用
因为上面所说的CMS缺点以及本身机制存在的问题,所以JVM重新实现了G1的垃圾回收器去替换CMS垃圾回收器,在JDK14版本彻底的删除了CMS,也是JVM彻底删除的第一款垃圾回收器,后续笔者会将G1详细介绍
GC 时间过长和 OutOfMemoryError
如果总时间的 98% 以上花费在垃圾收集上,而回收的堆少于 2%,则OutOfMemoryError抛出an 。此功能旨在防止应用程序长时间运行而由于堆太小而进展甚微或没有进展。如有必要,可以通过将选项添加-XX:-UseGCOverheadLimit到命令行来禁用此功能。