引言
分析Java线程池就离不开Executor类
Executor框架
为了更好地控制多线程,JDK提供了一套Executor框架,可以有效地进行线程控制,其本质上就是一个线程池。
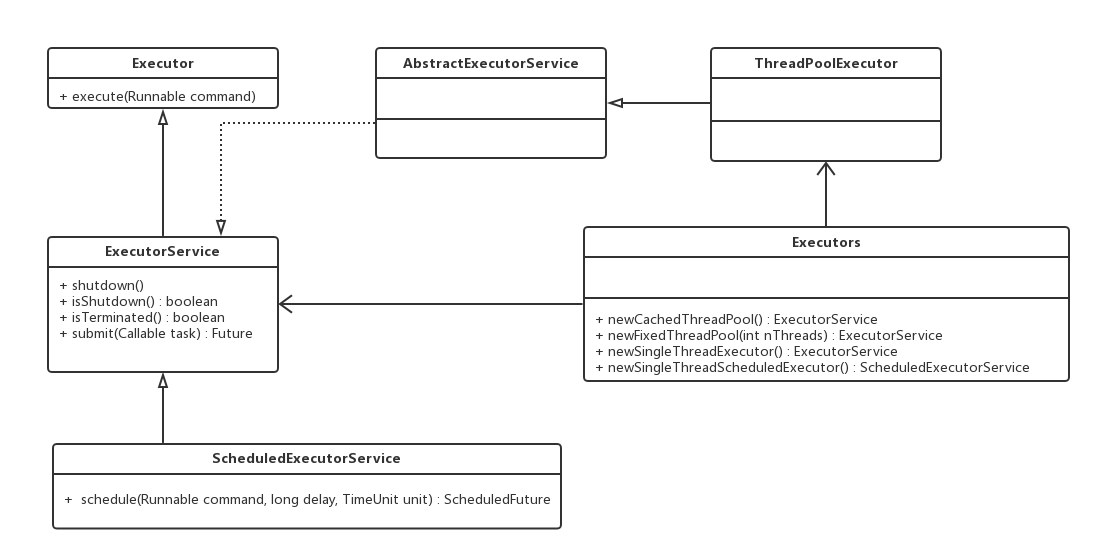
其中ThreadPoolExecutor表示一个线程池。Executors类则扮演着线程池工厂的角色,通过Executors可以取得一个拥有特定功能的线程池。从上图可知,ThreadPoolExecutor类实现了Executor接口,因此,通过这个接口,任何Runnable对象都可以被ThreadPoolExecutor线程池调度。
Executor框架提供了各种类型的线程池,主要有以下工厂方法:
public static ExecutorService newFixedThreadPool(int nThreads)
public static ExecutorService newSingleThreadExecutor()
public static ExecutorService newCachedThreadPool()
public static ScheduledExecutorService newSingleThreadScheduledExecutor()
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
以上工厂方法分别返回具有不同工作特性的线程池。这些线程池工厂方法的具体说明如下:
newFixedThreadPool: 该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂时存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务newSingleThreadExecutor: 该方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务newCachedThreadPool: 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用newSingleThreadScheduledExecutor: 该方法返回一个ScheduledExecutorService对象,线程池大小为1。ScheduledExecutorService接口在ExecutorService接口之上扩展了在给定时间执行某任务的功能,如在某个固定的延时之后执行,或者周期性执行某个任务。newScheduledThreadPool: 该方法也返回一个ScheduledExecutorService对象,但该线程池可以指定线程数量
计划任务
一个值得注意的方法是newScheduledThreadPool()。它返回一个ScheduledExecutorService对象,可以根据时间对线程进行调度。它的一些主要方法如下:
public ScheduledFuture<?> schedule(Runnable command,long delay,TimeUnit unit)
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit)
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit)
ScheduledExecutorService起到了计划任务的作用,它会在指定的时间,对任务进行调度。
方法schedule()会在给定时间,对任务进行一次调度。方法scheduleAtFixedRate()和scheduleWithFixedDelay()会对任务进行周期性的调度,但是两者有一点区别:
对于FixedRate方式来说,任务调度的频率是一定的。它是以上一个任务开始执行时间为起点,之后的period时间,调度下一次任务;而FixDelay则是在上一个任务结束后,再经过delay时间进行任务调度。
ScheduledExecutorService ses = Executors.newScheduledThreadPool(10);
//如果前面的任务没有完成,则调度也不会启动
ses.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
TimeUnit.SECONDS.sleep(1);
System.out.println(new Date().toLocaleString());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},0,2,TimeUnit.SECONDS);
output:
2017-8-28 21:46:49
2017-8-28 21:46:51
2017-8-28 21:46:53
2017-8-28 21:46:55
2017-8-28 21:46:57
2017-8-28 21:46:59
上述输出的单位是秒,可以看到,时间间隔是2秒。
如果任务的执行时间改为8秒,会有怎么样的打印
2017-8-28 21:48:54
2017-8-28 21:49:02
2017-8-28 21:49:10
2017-8-28 21:49:18
2017-8-28 21:49:26
2017-8-28 21:49:34
可以发现,周期不再是2秒,而是变成了8秒。
可知,如果周期太短,那么任务就会在上一个任务结束后,立即被调用。
如果改成scheduleWithFixedDelay,并且周期为2秒,任务耗时8秒,那么任务的时间间隔为10秒。
2017-8-28 21:52:20
2017-8-28 21:52:30
2017-8-28 21:52:40
2017-8-28 21:52:50
如果任务本身抛出了异常,那么后续的所有执行都会被中断,因此,做好异常处理就非常重要。
ScheduledFuture的使用
ScheduledFuture很简单,它就是在Future基础上还集成了Comparable和Delayed的接口。
它用于表示ScheduledExecutorService中提交了任务的返回结果。我们通过Delayed的接口getDelay()方法知道该任务还有多久才被执行。
= Executors.newScheduledThreadPool(10);
ScheduledFuture sf = service.schedule(new Callable() {
public Object call() throws Exception {
System.out.println("job start");
return "ok";
}
},5, TimeUnit.SECONDS);
TimeUnit.SECONDS.sleep(2);
System.out.println("delay:"+sf.getDelay(TimeUnit.SECONDS));
if(Math.random()>0.5){
System.out.println("and then cancel the job");
sf.cancel(false);//mayInterruptIfRunning : false
}else{
System.out.println("do not cancel,wait for result:");
System.out.println(sf.get());
service.shutdown();
}
可以通过cancel来取消一个任务,或者通过get()方法来返回任务的结果(Callable支持,Runnable返回null)
A delayed result-bearing action that can be cancelled. Usually a scheduled future is the result of scheduling a task with a ScheduledExecutorService.
核心线程池的内部实现
对于上面锁列出的线程池,虽然看起来有着完全不同的功能特点,但其内部实现均使用了ThreadPoolExecutor实现,下面给出了这三个线程池的实现方式:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
由以上线程池的实现代码可以看到,它们都只是ThreadPoolExecutor类的封装,看一下ThreadPoolExecutor最重要的构造函数:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
参数含义如下:
corePoolSize指定了线程池中的最小工作线程数量maximumPoolSize指定了线程池中的最大线程数量keepAliveTime当线程池线程数量超过corePoolSize时,多余的空闲线程的存活时间unitkeepAliveTime的单位workQueue任务队列,被提交但尚未被执行的任务threadFactory线程工厂,用于创建线程handler拒绝策略。当任务太多来不及处理,如何拒绝任务
corePoolSize和maximumPoolSize:
线程创建策略如下,通过下面这个流程图可以很好的理解corePoolSize和maximumPoolSize的关系:
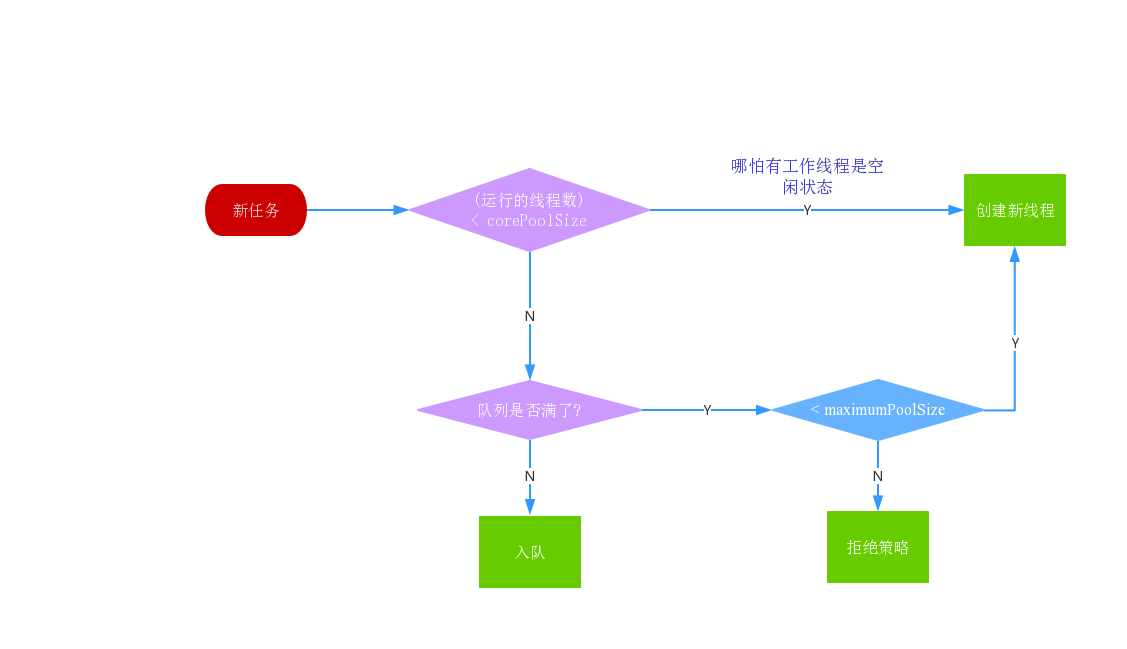
来分析一下这个流程图,当一个任务被提交进来后,首先会比较该线程池运行的线程数量与corePoolSize,如果小于(哪怕池中有空闲线程)则实例化一个新线程(来处理这个任务);
否则尝试入队,若入队失败(offer方法返回false),说明队满,则判断是否小于maximumPoolSize,若小于则新建临时线程;否则执行拒绝策略。
我们可以通过一个实例来验证下这个过程:
import java.util.concurrent.*;
public class ThreadPoolTest {
private static class MyTask implements Runnable {
private String name;
public MyTask(String name) {
this.name = name;
}
@Override
public String toString() {
return name;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " start handle " + this);
try {
Thread.sleep(10000);
System.out.println(Thread.currentThread().getName() + " finished " + this);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
//传入了有限队列,大小为5 默认的拒绝策略为抛弃
ExecutorService pool = new ThreadPoolExecutor(2, 4,
0L, TimeUnit.MILLISECONDS,
new TaskQueue(5));
//10个任务
for (int i = 1; i <= 10; i++) {
MyTask task = new MyTask("Task-" + i);
try {
pool.execute(task);
} catch (RejectedExecutionException e) {
System.out.println(task + " was rejected.");
}
}
//关闭线程池,它会等待已提交的任务执行完毕
pool.shutdown();
}
/**
* 继承了LinkedBlockingQueue,增加了打印信息
*/
private static class TaskQueue extends LinkedBlockingQueue<Runnable> {
public TaskQueue() {
super();
}
public TaskQueue(int capacity) {
super(capacity);
}
@Override
public boolean offer(Runnable runnable) {
boolean result = super.offer(runnable);
System.out.println(runnable + " enqueue " + (result ? " success" : "failed."));
return result;
}
@Override
public Runnable take() throws InterruptedException {
Runnable task = super.take();
System.out.println(task + " was finishd and removed.");
return task;
}
}
}
输出如下:
Task-3 enqueue success
Task-4 enqueue success
Task-5 enqueue success
Task-6 enqueue success
Task-7 enqueue success
Task-8 enqueue failed.
Task-9 enqueue failed.
Task-10 enqueue failed.
Task-10 was rejected. //被拒接
pool-1-thread-1 start handle Task-1
pool-1-thread-2 start handle Task-2
pool-1-thread-3 start handle Task-8
pool-1-thread-4 start handle Task-9
pool-1-thread-1 finished Task-1
pool-1-thread-1 start handle Task-3
pool-1-thread-2 finished Task-2
pool-1-thread-2 start handle Task-4
pool-1-thread-3 finished Task-8
pool-1-thread-3 start handle Task-5
pool-1-thread-4 finished Task-9
pool-1-thread-4 start handle Task-6
pool-1-thread-1 finished Task-3
pool-1-thread-1 start handle Task-7
pool-1-thread-2 finished Task-4
pool-1-thread-3 finished Task-5
pool-1-thread-4 finished Task-6
pool-1-thread-1 finished Task-7
我们自己实现了一个有界队列,增加了一些打印信息便于理解。构造了一个核心线程数为2,最大线程数为4的线程池。
同时,它的有界队列大小为5。也就是说最多能同时运行4个线程,有5个任务在队列中保存,若此时再有任务进来,转而执行拒绝策略。
从上面的输出可以看出,Task-1、Task-2直接被处理,接着Task-3、Task-4、Task-5、Task-6、Task-7入队,然后Task-8、Task-9入队失败,但是此时运行的线程数为2,小于最大的值4,因此这两个任务被新建的临时线程处理;接着Task-10入队失败,同时运行的线程数达到最大值,执行拒绝策略。
workQueue:
指被提交但未执行的任务队列,它是一个BlockingQueue接口的对象,仅用于存放Runnable对象,根据队列功能分类,在ThreadPoolExecutor的构造函数中可使用以下几种BlockingQueue:
- 直接提交的队列:该功能由
SynchronousQueue对象提供。SynchronousQueue是一个特殊的阻塞队列,它没有容量,每一个插入操作都要等待一个相应的删除操作,反之,每一个删除操作都要等待对应的插入操作。如果使用这个队列,提交的任务不会被真实的保存,而总是将新任务提交给线程执行,如果没有空闲的线程,则尝试创建新的工作线程,如果线程数量已经达到最大值(maximumPoolSize),则执行拒绝策略。因此,使用SynchronousQueue队列,通常要设置很大的maximumPoolSize值,否则很容易执行拒绝策略。 - 有界的任务队列:有界的任务队列可以使用带有队列最大容量的
ArrayBlockingQueue实现。有界队列仅在任务队列装满时,才可能将线程数提升到corePoolSize以上,换言之,除非系统非常繁忙,否则确保核心线程数维持在corePoolSize以内。 - 无界的任务队列:无界的任务队列可以通过
LinkedBlockingQueue类实现,与有界队列相比,除非系统资源耗尽,否则无界的任务队列不存在任务入队失败的情况。若任务创建速度远远大于处理速度,无界队列会快速增长,直到耗尽系统内存。 - 优先任务队列: 优先任务队列是带有执行优先级的队列。它通过
PriorityBlockingQueue实现,可以控制任务的执行先后顺序。它是以特殊的无界队列。它可以根据任务自身的优先级顺序来执行任务,在确保系统性能的同时,也能有很好的质量保证(总是确保高优先级的任务先执行)
回顾newFixedThreadPool()方法的实现。它返回了一个corePoolSize和maximumPoolSize大小一样的,使用了LinkedBlockingQueue任务队列的线程池。因为固定大小的线程池不会有线程数量的动态变化。由于它使用无界队列存放无法立即执行的任务,当任务提交非常频繁时,该队列会迅速膨胀,从而耗尽系统资源。
newSingleThreadExecutor()返回的是单线程线程池,是newFixedThreadPool()方法的一种退化,只是简单的将线程池数量设为1。
newCachedThreadPool()方法返回corePoolSize是0,maximumPoolSize无穷大的线程池,这意味着在没有任务时,该线程池内无线程,而当任务被提交时,该线程池会使用空闲的线程执行任务;若无空闲线程,则将任务加入SynchronousQueue队列,而这个队列是一个直接提交的队列,它总会迫使线程池增加新的线程执行任务。当任务执行完毕后,由于corePoolSize是0,因此空闲线程又会在指定时间(60秒)被回收。
对于newCachedThreadPool(),如果同时有大量任务被提交,而任务的执行又不那么快时,那么系统便会开启等量的线程处理,这样做可能会很快耗尽系统的资源。。
这里给出ThreadPoolExecutor线程池的核心调度代码:
/*
* 先看一下addWorker这个方法
* @param core true 使用 corePoolSize 作为上限, 否则使用maximumPoolSize
* @return 成功返回true
*/
private boolean addWorker(Runnable firstTask, boolean core);
/**
* 在未来某时运行给定的任务,任务可能在新线程中运行,也可能在线程池中的线程中运行。
*
* 如果一个任务不能被提交(submit),不是因为executor已经被关闭,就是已经达到了executor的maximumPoolSize,
* 这个任务就会被当前的RejectedExecutionHandler来处理
*
*/
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//当工作线程总数小于corePoolSizes时
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
//添加新线程失败,重新获取ctl的值
c = ctl.get();
}
//进入等待队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//进入等待队列失败(有界队列达到上限或者使用了SynchronousQueue)
//直接提交给线程池,如果线程数量达到maximumPoolSize,执行拒绝策略
else if (!addWorker(command, false))
reject(command);
}
拒绝策略
ThreadPoolExecutor的最后一个参数指定了拒绝策略。当任务数量超过系统实际承载能力时的处理策略。内置了四种拒绝策略:
- AbortPolicy:该策略会直接抛出异常,阻止系统正常工作
- CallerRunsPolicy:只要线程池未关闭,该策略直接在调用者线程中,运行当前被丢弃的任务。
- DiscardOledestPolicy策略:该策略将丢弃最老的一个请求,也就是即将被执行的一个任务,并尝试再次提交当前任务
- DiscardPolicy策略:该策略默默地丢弃无法处理的任务,不予任何处理。
以上内置的策略均实现了RejectedExecutionHandler接口,若以上策略仍无法满足实际应用需要,可以自己扩展RejectedExecutionHandler接口。
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
下面的代码简单地演示了自定义线程池和拒绝策略的使用:
public class RejectedThreadPoolDemo {
private static class MyTask implements Runnable {
@Override
public void run() {
System.out.println(System.currentTimeMillis() + ":Thread ID:"
+ Thread.currentThread().getId());
try{
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
MyTask task = new MyTask();
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(10), Executors.defaultThreadFactory(),
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println(r.toString() + " is discard");
}
});
for (int i = 0; i < Integer.MAX_VALUE; i++) {
es.submit(task);
Thread.sleep(10);
}
}
}
上述的代码定义了一个线程池。该线程池有5个常驻线程,并且最大线程数量也是5个。但它有一个只有10个容量的等待队列。因此使用无界队列很可能并不是最佳解决方案,如果任务量极大,很可能会把内存撑爆。给出一个合理的队列大小,也是合理的选择。同时,这里自定义了拒绝策略,我们不抛出异常,因为万一在任务提交端没有进行异常处理,则有可能使得整个系统都崩溃瓶,这不是我们希望遇到的,但作为必要的信息记录,我将任务丢弃的信息进行打印。
自定义线程创建:ThreadFactory
用来创建线程池需要的线程:
public interface ThreadFactory {
Thread newThread(Runnable r);
}
当线程池需要新建线程时,就会调用这个方法。
自定义线程池可以跟踪何时创建了多少线程,也可以自定义线程的名称、组以及优先级等信息。
下面的案例使用自定义的ThreadFactory,一方面记录了线程的创建,另一方面将所有的线程都设置为守护线程:
MyTask task = new MyTask();
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new SynchronousQueue<Runnable>(), new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setDaemon(true);
System.out.println("create " + t);
return t;
}
});
for (int i = 0; i < 5; i++) {
es.submit(task);
}
Thread.sleep(2000);
扩展线程池
ThreadPoolExecutor是一个可以扩展的线程池。它提供了beforeExecute()、afterExecute()、terminated()三个接口对线程池进行控制。
在ThreadPoolExecutor.Worker.runTask()方法内部提供了这样的实现:
boolean ran = false;
beforeExecute(thread,task); //运行前
try{
task.run(); //运行任务
ran = true;
afterExecute(task,null); //运行结束后
++completedTasks;
}catch (RuntimeException ex) {
if (!ran)
afterExecute(task,ex); //运行结束
throw ex;
}
下面演示了对线程池的扩展,在这个扩展中,我们记录每一个任务的执行日志》
package com.ha;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ExtThreadPool {
private static class MyTask implements Runnable{
public String name;
public MyTask(String name){
this.name = name;
}
@Override
public void run() {
System.out.println("正在执行" + ":Thread ID:" + Thread.currentThread().getId()
+ ",Task Name=" + name);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
ExecutorService es = new ThreadPoolExecutor(5,5,0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()){
@Override
protected void beforeExecute(Thread t, Runnable r) {
System.out.println("准备执行:"+((MyTask)r).name);
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
System.out.println("执行完成:"+((MyTask)r).name);
}
@Override
protected void terminated() {
System.out.println("线程池退出");
}
};
for (int i = 0; i < 5; i++) {
MyTask task = new MyTask("TASK-"+i);
es.execute(task);
Thread.sleep(10);
}
es.shutdown();
}
}
输出:
准备执行:TASK-0
正在执行:Thread ID:10,Task Name=TASK-0
准备执行:TASK-1
正在执行:Thread ID:11,Task Name=TASK-1
准备执行:TASK-2
正在执行:Thread ID:12,Task Name=TASK-2
准备执行:TASK-3
正在执行:Thread ID:13,Task Name=TASK-3
准备执行:TASK-4
正在执行:Thread ID:14,Task Name=TASK-4
执行完成:TASK-0
执行完成:TASK-1
执行完成:TASK-2
执行完成:TASK-3
执行完成:TASK-4
线程池退出
在线程池中寻找堆栈
首先看一个简单的案例,我们有一个Runnable接口,它用来计算两个数的商:
package com.ha;
import java.util.concurrent.SynchronousQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class DivTask implements Runnable{
int a,b;
public DivTask(int a, int b) {
this.a = a;
this.b = b;
}
@Override
public void run() {
double re = a/b;
System.out.println(re);
}
public static void main(String[] args) {
ThreadPoolExecutor pools = new ThreadPoolExecutor(0,Integer.MAX_VALUE,
0L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
for (int i = 0; i < 5; i++) {
pools.submit(new DivTask(100,i));
}
}
}
输出:
100.0
50.0
33.0
25.0
从这个for循环来看,我们应该会得到5个结果,但是实际上只有4个。也就是说程序漏算了一组数据!但是没有任何日志,没有任何错误提示。在这个简单的案例中,只要仔细一点,就会发现,作为除数的i取到了0,这个缺失的值很可能是由于除以0导致的。但是在复杂的业务场景中,这种错误很难发现。
因此,使用线程池虽然是好事,但是还是得处处留意这些坑。线程池和可能会“吃”掉程序抛出的异常,导致我们对程序的错误一无所知。
那么,如何向线程池讨回异常堆栈呢?
一种最简单的方法及时放弃submit(),改用execute():
pools.execute(new DivTask(100,i)); 或者使用下的方法改造submit():
Future re = pools.submit(new DivTask(100,i));
re.get();
输出
100.0
Exception in thread "pool-1-thread-1" java.lang.ArithmeticException: / by zero50.0
at com.ha.DivTask.run(DivTask.java:18)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:722)
33.0
25.0
注意了,任务的具体提交位置已经被线程池淹没了,顺着堆栈,只能找到线程池中的调度流程,而这对于我们几乎是没有价值的。
我们只好扩展ThreadPoolExecutor线程池,让它在调度任务之前,先保存一下提交任务线程的堆栈信息。如下所示:
package com.ha;
import java.util.concurrent.*;
public class TraceThreadPoolExecutor extends ThreadPoolExecutor {
public TraceThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
private Exception clientTrace(){
return new Exception("Client stack trace");
}
private Runnable wrap(final Runnable task,final Exception clientStack,
String clientThreadName){
return new Runnable() {
@Override
public void run() {
try{
task.run();
}catch (Exception e){
clientStack.printStackTrace();
throw e;
}
}
};
}
@Override
public void execute(Runnable task) {
super.execute(wrap(task,clientTrace(),Thread.currentThread().getName()));
}
@Override
public Future<?> submit(Runnable task) {
return super.submit(wrap(task,clientTrace(),Thread.currentThread().getName()));
}
public static void main(String[] args) {
ThreadPoolExecutor pools = new TraceThreadPoolExecutor(0,Integer.MAX_VALUE,0L,
TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
for (int i = 0; i < 5; i++) {
pools.execute(new DivTask(100,i));
}
}
}
wrap()方法的第2个参数为一个异常,里面保存着提交任务的线程的堆栈信息。该方法将我们传入的Runnable任务进行一层包装,使之能处理异常信息。当任务发生异常时,这个异常会被打印。
输出:
100.0
java.lang.Exception: Client stack trace
50.0
33.0
25.0
at com.ha.TraceThreadPoolExecutor.clientTrace(TraceThreadPoolExecutor.java:11)
at com.ha.TraceThreadPoolExecutor.execute(TraceThreadPoolExecutor.java:31)
at com.ha.TraceThreadPoolExecutor.main(TraceThreadPoolExecutor.java:44)
Exception in thread "pool-1-thread-1" java.lang.ArithmeticException: / by zero
at com.ha.DivTask.run(DivTask.java:18)
at com.ha.TraceThreadPoolExecutor$1.run(TraceThreadPoolExecutor.java:20)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:722)
现在,我们不仅可以得到异常发生的Runnable实现内的信息,我们也知道了这个任务是在哪里提交的。