1 来源
- 来源:《Java虚拟机 JVM故障诊断与性能优化》——葛一鸣
- 章节:第二章
本文是第二章的一些笔记整理。
2 JVM基本参数-Xmx
java命令的一般形式如下:
java [-options] class [args..]
其中-options表示JVM启动参数,class为带有main()的Java类,args表示传递给main()的参数,也就是main(String [] args)中的参数。
一般设置参数在-optinos处设置,先看一段简单的代码:
public class Main {
public static void main(String[] args) {
for(int i=0;i<args.length;++i) {
System.out.println("argument "+(i+1)+" : "+args[i]);
}
System.out.println("-Xmx "+Runtime.getRuntime().maxMemory()/1024/1024+" M");
}
}
设置应用程序参数以及JVM参数:

输出:
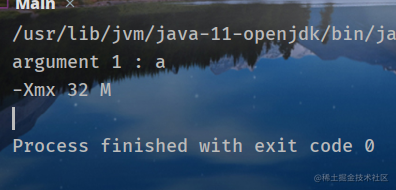
可以看到-Xmx32m传递给JVM,使得最大可用堆空间为32MB,参数a作为应用程序参数,传递给main(),此时args.length的值为1。
3 JVM基本结构
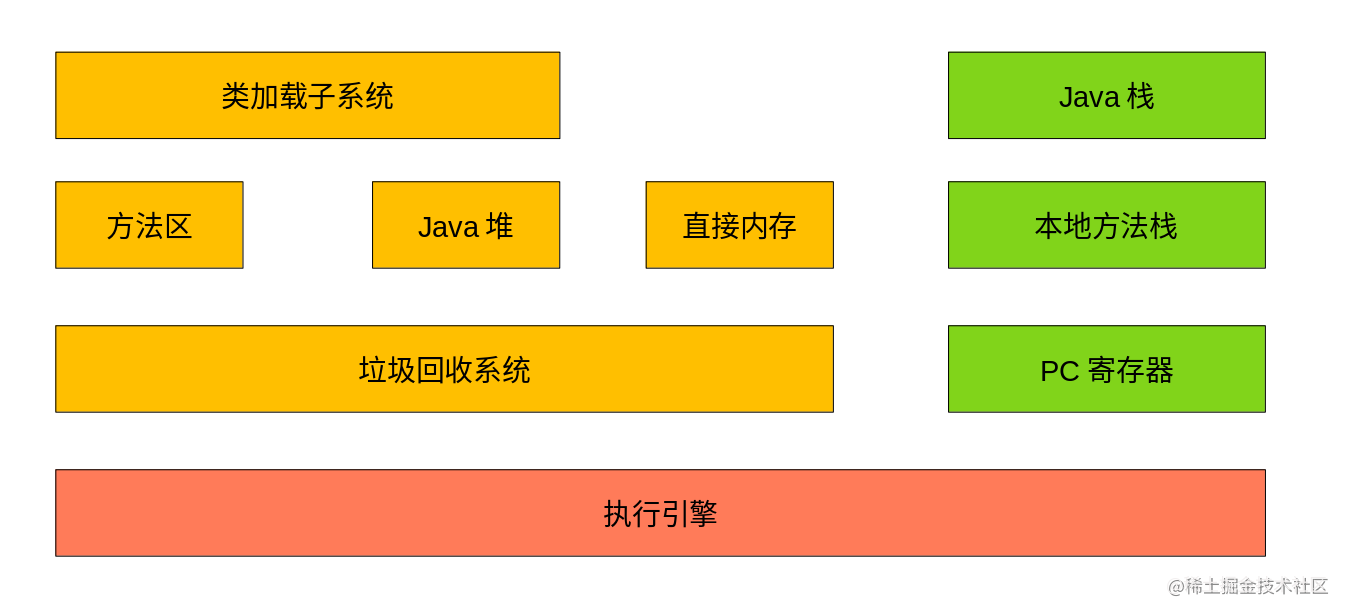
各部分介绍如下:
类加载子系统:负责从文件系统或者网络中加载Class信息,加载的类信息存放在一个叫方法区的内存空间中方法区:除了包含加载的类信息之外,还包含运行时常量池信息,包括字符串字面量以及数字常量Java堆:在虚拟机启动时建立,是最主要的内存工作区域,几乎所有的Java对象实例都存在于Java堆中, 堆空间是所有线程共享的直接内存:是在Java堆外的,直接向系统申请的内存区域。NIO库允许Java程序使用直接内存,通常直接内存的访问速度要优于Java堆。另外由于直接内存在堆外,大小不会受限于-Xmx指定的堆大小,但是会受到操作系统总内存大小的限制垃圾回收系统:可以对方法区、Java堆和直接内存进行回收,Java堆是垃圾收集器的工作重点。对于不再使用的垃圾对象,垃圾回收系统会在后台默默工作、默默查找,标识并释放垃圾对象Java栈:每个JVM线程都有一个私有的Java栈,一个线程的Java栈在线程创建时被创建,保存着帧信息、局部变量、方法参数等本地方法栈:与Java栈类似,不同的是Java栈用于Java方法调用,本地方法栈用于本地方法(native method)调用,JVM允许Java直接调用本地方法PC寄存器:每个线程私有的空间,JVM会为每个线程创建PC寄存器,在任意时刻一个Java线程总是执行一个叫做当前方法的方法,如果当前方法不是本地方法,PC寄存器就会指向当前正在被执行的指令,如果当前方法是本地方法,那么PC寄存器的值就是undefined执行引擎:负责执行JVM的字节码,现代JVM为了提高执行效率,会使用即时编译技术将方法编译成机器码后执行
下面重点说三部分:Java堆、Java栈以及方法区。
4 Java堆
几乎所有的对象都存在Java堆中,根据垃圾回收机制的不同,Java堆可能拥有不同的结构,最常见的一种是将整个Java堆分为新生代和老年代:
新生代:存放新生对象或年龄不大的对象,有可能分为eden、s0、s1,其中s0和s1分别被称为from和to区域,它们是两块大小相等、可以互换角色的内存空间老年代:存放老年对象,绝大多数情况下,对象首先在eden分配,在一次新生代回收后,如果对象还存活,会进入s0或s1,之后每经过一次新生代回收,如果对象存活则年龄加1。当对象年龄到达一定条件后,会被认为是老年对象,就会进入老年代

5 Java栈
5.1 简介
Java栈是一块线程私有的内存空间,如果是Java堆与程序数据密切相关,那么Java栈和线程执行密切相关,线程执行的基本行为是函数调用,每次函数调用都是通过Java栈传递的。
Java栈与数据结构中的栈类似,有FIFO的特点,在Java栈中保存的主要内容为 栈帧 ,每次函数调用都会有一个对应的栈帧入栈,每次调用结束就有一个对应的栈帧出栈。栈顶总是当前的帧(当前执行的函数所对应的帧)。栈帧保存着局部变量表、操作数栈、帧数据等。
这里说一下题外话,相信很多读者对StackOverflowError不陌生,这是因为函数调用过多造成的,因为每次函数调用都会生成对应的栈帧,会占用一定的栈空间,如果栈空间不足,函数调用就无法进行,当请求栈深度大于最大可用栈深度时,就会抛出StackOverflowError。
JVM提供了-Xss来指定线程的最大栈空间。
比如,下面这个递归调用的程序:
public class Main {
private static int count = 0;
public static void recursion(){
++count;
recursion();
}
public static void main(String[] args) {
try{
recursion();
}catch (StackOverflowError e){
System.out.println("Deep of calling = "+count);
}
}
}
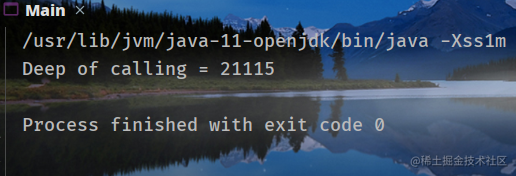
指定-Xss1m,结果:
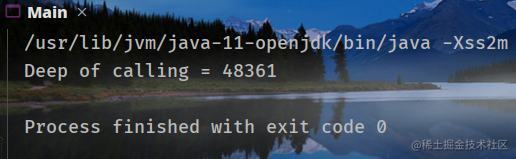
指定-Xss2m:
指定-Xss3m:
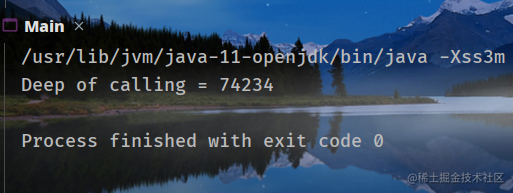
可以看到调用深度随着-Xss的增加而增加。
5.2 局部变量表
局部变量表是栈帧的重要组成部分之一,用于保存函数的参数及局部变量。局部变量表中的变量只在当前函数调用中有效,函数调用结束后,函数栈帧销毁,局部变量表也会随之销毁。
5.2.1 参数数量对局部变量表的影响
由于局部变量表在栈帧中,如果函数的参数和局部变量表较多,会使局部变量表膨胀,导致栈帧会占用更多的栈空间,最终减少了函数嵌套调用次数。
比如:
public class Main {
private static int count = 0;
public static void recursion(long a,long b,long c){
long e=1,f=2,g=3,h=4,i=5,k=6,q=7;
count++;
recursion(a,b,c);
}
public static void recursion(){
++count;
recursion();
}
public static void main(String[] args) {
try{
// recursion();
recursion(0L,1L,2L);
}catch (StackOverflowError e){
System.out.println("Deep of calling = "+count);
count = 0;
}
}
}
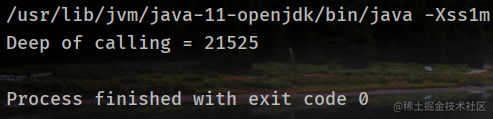
无参数的调用次数(-Xss1m):
带参数的调用次数(-Xss1m):
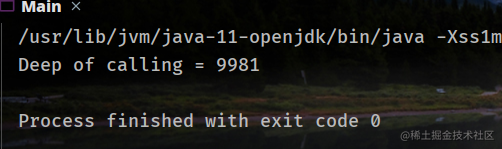
可以看到次数明显减少了,原因正是因为局部变量表变大,导致栈帧变大,从而次数减少。
下面使用jclasslib进一步查看,先在IDEA安装如下插件:
安装后使用插件查看情况:

第一个函数是带参数的,可以看到最大局部变量表的大小为20字(注意不是字节),Long在局部变量表中需要占用2字。而相比之下不带参数的函数最大局部变量表大小为0:
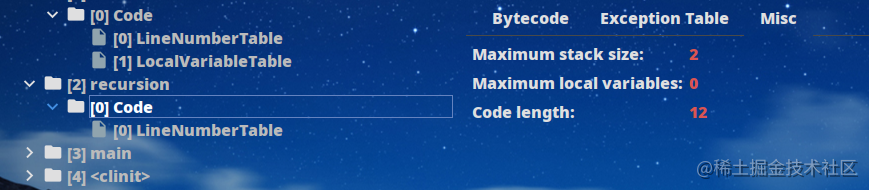
5.2.2 槽位复用
局部变量表中的槽位是可以复用的,如果一个局部变量超过了其作用域,则在其作用域之后的局部变量就有可能复用该变量的槽位,这样能够节省资源,比如:
public static void localVar1(){
int a = 0;
System.out.println(a);
int b = 0;
}
public static void localVar2(){
{
int a = 0;
System.out.println(a);
}
int b = 0;
}
同样使用jclasslib查看:


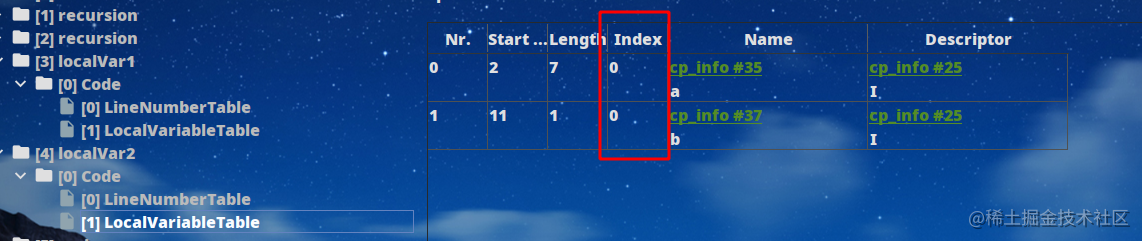
可以看到少了localVar2的最大局部变量大小为1字,相比localVar1少了1字,继续分析,localVar1第0个槽位为变量a,第1个槽位为变量b:

而localVar2中的b复用了a的槽位,因此最大变量大小为1字,节约了空间。
5.2.3 对GC的影响
下面再来看一下局部变量表对垃圾回收的影响,示例:
public class Main {
public static void localGC1(){
byte [] a = new byte[6*1024*1024];
System.gc();
}
public static void localGC2(){
byte [] a = new byte[6*1024*1024];
a = null;
System.gc();
}
public static void localGC3(){
{
byte [] a = new byte[6*1024*1024];
}
System.gc();
}
public static void localGC4(){
{
byte [] a = new byte[6*1024*1024];
}
int c = 10;
System.gc();
}
public static void localGC5(){
localGC1();
System.gc();
}
public static void main(String[] args) {
System.out.println("-------------localGC1------------");
localGC1();
System.out.println();
System.out.println("-------------localGC2------------");
localGC2();
System.out.println();
System.out.println("-------------localGC3------------");
localGC3();
System.out.println();
System.out.println("-------------localGC4------------");
localGC4();
System.out.println();
System.out.println("-------------localGC5------------");
localGC5();
System.out.println();
}
}
输出(请加上-Xlog:gc参数):
[0.004s][info][gc] Using G1
-------------localGC1------------
[0.128s][info][gc] GC(0) Pause Full (System.gc()) 10M->8M(40M) 12.081ms
-------------localGC2------------
[0.128s][info][gc] GC(1) Pause Young (Concurrent Start) (G1 Humongous Allocation) 9M->8M(40M) 0.264ms
[0.128s][info][gc] GC(2) Concurrent Cycle
[0.133s][info][gc] GC(3) Pause Full (System.gc()) 16M->0M(14M) 2.799ms
[0.133s][info][gc] GC(2) Concurrent Cycle 4.701ms
-------------localGC3------------
[0.133s][info][gc] GC(4) Pause Young (Concurrent Start) (G1 Humongous Allocation) 0M->0M(14M) 0.203ms
[0.133s][info][gc] GC(5) Concurrent Cycle
[0.135s][info][gc] GC(5) Pause Remark 8M->8M(22M) 0.499ms
[0.138s][info][gc] GC(6) Pause Full (System.gc()) 8M->8M(22M) 2.510ms
[0.138s][info][gc] GC(5) Concurrent Cycle 4.823ms
-------------localGC4------------
[0.138s][info][gc] GC(7) Pause Young (Concurrent Start) (G1 Humongous Allocation) 8M->8M(22M) 0.202ms
[0.138s][info][gc] GC(8) Concurrent Cycle
[0.142s][info][gc] GC(9) Pause Full (System.gc()) 16M->0M(8M) 2.861ms
[0.142s][info][gc] GC(8) Concurrent Cycle 3.953ms
-------------localGC5------------
[0.143s][info][gc] GC(10) Pause Young (Concurrent Start) (G1 Humongous Allocation) 0M->0M(8M) 0.324ms
[0.143s][info][gc] GC(11) Concurrent Cycle
[0.145s][info][gc] GC(11) Pause Remark 8M->8M(16M) 0.316ms
[0.147s][info][gc] GC(12) Pause Full (System.gc()) 8M->8M(18M) 2.402ms
[0.149s][info][gc] GC(13) Pause Full (System.gc()) 8M->0M(8M) 2.462ms
[0.149s][info][gc] GC(11) Concurrent Cycle 6.843ms
首行输出表示使用G1,下面逐个进行分析:
localGC1:并没有回收内存,因为此时byte数组被变量a引用,因此无法回收localGC2:回收了内存,因为a被设置为了null,byte数组失去强引用localGC3:没有回收内存,虽然此时a变量已经失效,但是仍然存在于局部变量表中,并且指向byte数组,因此无法回收localGC4:回收了内存,因为声明了变量c,复用了a的槽位,导致byte数组失去引用,顺利回收localGC5:回收了内存,虽然localGC1中没有释放内存,但是返回到localGC5后,localGC1的栈帧被销毁,也包括其中的byte数组失去了引用,因此在localGC5中被回收
5.3 操作数栈与帧数据区
操作数栈也是栈帧的重要内容之一,主要用于保存计算过程的中间结果,同时作为计算过程中变量的临时存储空间,也是一个FIFO的数据结构。
而帧数据区则保存着常量池指针,方便程序访问常量池,此外,帧数据区也保存着异常处理表,以便在出现异常后,找到处理异常的代码。
5.4 栈上分配
栈上分配是JVM提供的一项优化技术,基本思想是,将线程私有的对象打散分配到栈上,好处是函数调用结束后可以自动销毁,而不需要垃圾回收器的介入,从而提高系统性能。
栈上分配的一个技术基础是逃逸分析,逃逸分析目的是判断对象的作用域是否会逃逸出函数体,例子如下:
public class Main {
private static int count = 0;
public static class User{
public int id = 0;
public String name = "";
}
public static void alloc(){
User user = new User();
user.id = 5;
user.name = "test";
}
public static void main(String[] args) {
long b = System.currentTimeMillis();
for (int i = 0; i < 1000000000; i++) {
alloc();
}
long e = System.currentTimeMillis();
System.out.println(e-b);
}
}
启动参数:
-server # 开启Server模式,此模式下才能开启逃逸分析
-Xmx10m # 最大堆内存
-Xms10m # 初始化堆内存
-XX:+DoEscapeAnalysis # 开启逃逸分析
-Xlog:gc # GC日志
-XX:-UseTLAB # 关闭TLAB
-XX:+EliminateAllocations # 开启标量替换,默认打开,允许将对象打散分配在栈上
输出如下,没有GC日志:

而如果关闭了标量替换,也就是添加-XX:-EliminateAllocations,就可以看到会频繁触发GC,因为这时候对象存放在堆上而不是栈上,堆只有10m空间,会频繁进行GC:

6 方法区
与Java堆一样,方法区是所有线程共享的内存区域,用于保存系统的类信息,比如类字段、方法、常量池等,方法区的大小决定了系统可以保存多少个类,如果定义了过多的类,会导致方法区溢出,会直接OOM。
在JDK6/7中方法区可以理解成永久区,JDK8后,永久区被移除,取而代之的是元数据区,可以使用-XX:MaxMetaspaceSize指定,这是一块堆外的直接内存,如果不指定大小,默认情况下JVM会耗尽所有可用的系统内存。
如果元数据区发生溢出,JVM会抛出OOM。
7 Java堆、Java栈以及方法区的关系
看完了Java堆、Java栈以及方法区,最后来一段代码来简单分析一下它们的关系:
class SimpleHeap{
private int id;
public SimpleHeap(int id){
this.id = id;
}
public void show(){
System.out.println("id is "+id);
}
public static void main(String[] args) {
SimpleHeap s1 = new SimpleHeap(1);
SimpleHeap s2 = new SimpleHeap(2);
s1.show();
s2.show();
}
}
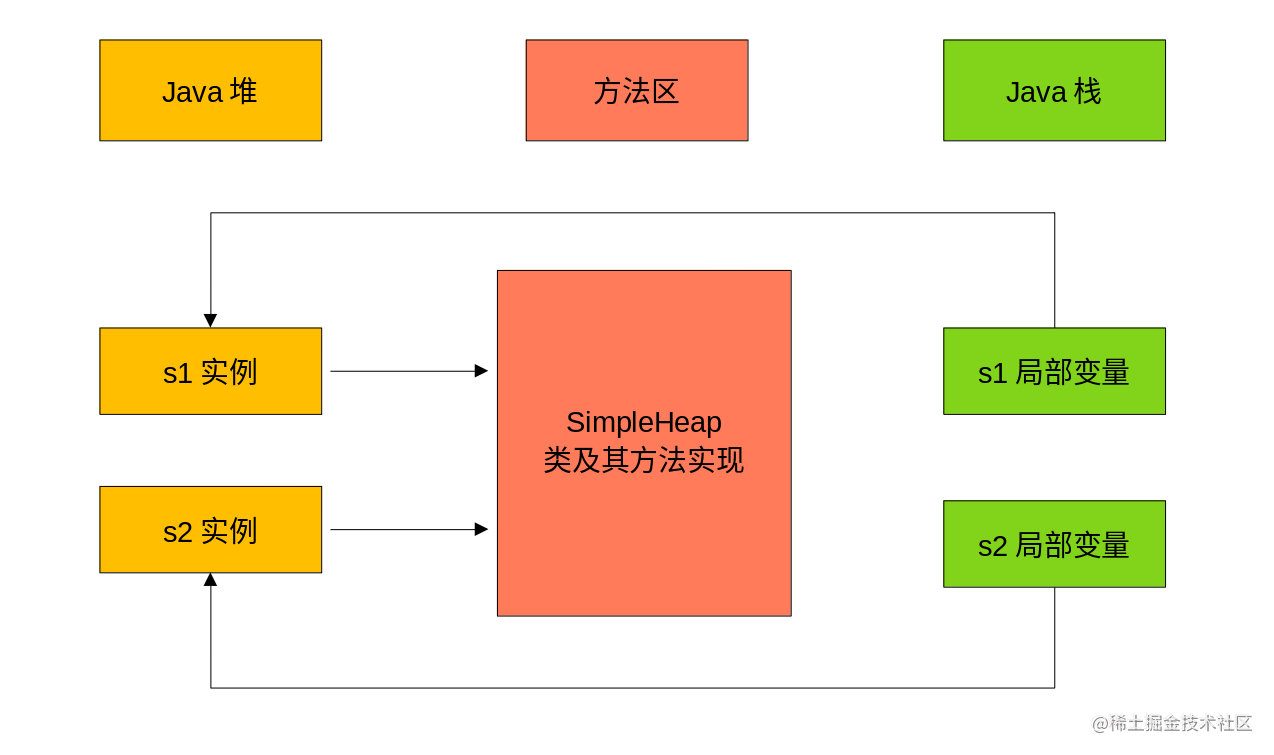
main中创建了两个局部变量s1、s2,则这两个局部变量存放在Java栈中。同时这两个局部变量是SimpleHeap的实例,这两个实例存放在Java堆中,而其中的show方法,则存放在方法区中,图示如下:
8 小结
本文主要讲述了JVM的基本结构以及一些基础参数,基本结构可以分成三部分:
- 第一部分:
类加载子系统、Java堆、方法区、直接内存 - 第二部分:
Java栈、本地方法栈、PC寄存器 - 第三部分:执行引擎
而重点讲了三部分:
Java堆:常见的结构为新生代+老年代结构,其中新生代可分为edsn、s0、s1Java栈:包括局部变量表、操作数栈与帧数据区,还提到了一个JVM优化技术栈上分配,可以通过-XX:+EliminateAllocation开启(默认开启)方法区:所有线程共享区域,用于保存类信息,比如类字段、方法、常量等