声明:本文使用JDK1.8
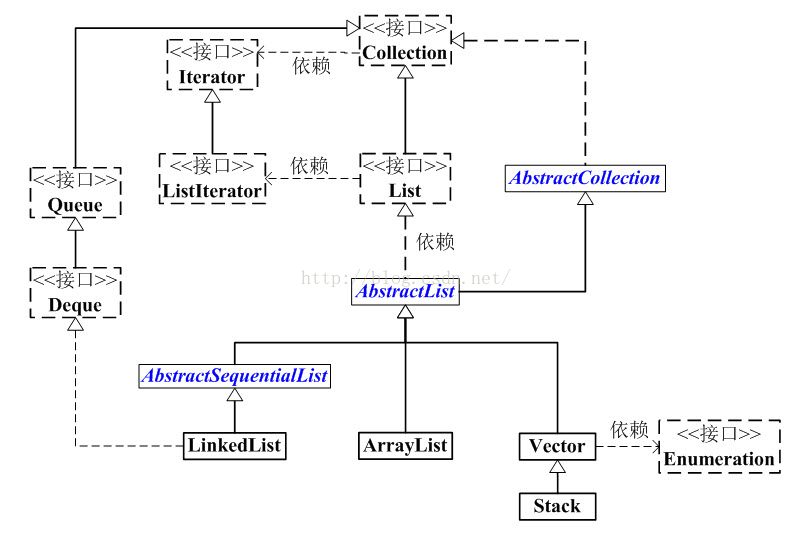
先看下List在Collection中的框架图:
ArrayList源码分析
大家基本都知道ArrayList的底层是数组的数据结构,下面来看下它的随机访问、删除等的源码:
private static final int DEFAULT_CAPACITY = 10;//初始容量为10
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;
private int size;
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
//ArrayList扩容函数方法
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// 计算当前ArrayList大小
int oldCapacity = elementData.length;
//这里我们可以看出,ArrayList每次扩容是增加50%,oldCapacity >> 1是指往左移一位,也就是除以2
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
//根据下标index获取元素值
public E get(int index) {
rangeCheck(index);//检查小标是否越界
return elementData(index);
}
//将index位置的值设为element,并返回原来的值
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
//向数组中末尾增加一个元素
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
//向指定位置index处增加element
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
//将index以及index之后的数据复制到index+1的位置往后,即从index开始向后挪了一位
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
//根据指定的index,删除元素
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
LinkedList源码分析
来看下LinkedList的部分源码,底层是基于双向链表的数据结构。
定义:
package java.util;public class LinkedList<E> extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
}
方法:
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {//如果index<(size/2),则从前找
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {//否则从末尾往前找
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
//直接删除某个元素
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
//根据下标查询某个元素
public E get(int index) {
checkElementIndex(index);//检查下标是否越界
return node(index).item;//可以看第一个node的方法,其中有查询
}
//设置index位置处的值为element
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
//在下标index位置处新增element
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)//index是末尾,则在末尾新增一个
linkLast(element);
else //这里的插入需要先去查询相应的位置,这会导致性能降低
linkBefore(element, node(index));
}
ArrayList和LinkedList区别
平时在看博客的时候,网上很多博客都说,ArrayList基于数组的数据机构,LinkedList是基于链表的数据结构,所以有以下几种特性:
1、对于随机查询,ArrayList比LinkedList快
2、对于插入或者删除,LinkedList由于是链表,所以是比ArrayList性能更好。
通过两者的源码比较,我们发现对于随机查找,ArrayList直接根据下标index查询相对于的值,而LinkedList虽然源码对其做了部分优化,index小于(size/2),从前往后找,否则从后往前找,即使这样,还是ArrayList比LinkedList快。
下面通过实际代码来看下插入的性能比较。
public static void main(String[] args) {
List<Integer> array = new ArrayList<>();
LinkedList<Integer> linked = new LinkedList<>();
//首先分别给两者插入10000条数据
for (int i = 0; i < 100000; i++) {
array.add(i);
linked.add(i);
}
//获得两者随机访问的时间
System.out.println("array get cost time:" + getTime(array));
System.out.println("linked get cost time:" + getTime(linked));
//获得在中间插入数据的时间
System.out.println("array insert in first cost time:" + insertArrayListAtFirstTime(array));
System.out.println("linked insert cost in first time:" + insertLinkedListAtFirstTime(linked));
//获得在中间插入数据的时间
System.out.println("array insert in middle cost time:" + insertInMiddleTime(array));
System.out.println("linked insert cost in middle time:" + insertInMiddleTime(linked));
//获得尾部插入数据的时间
System.out.println("array insert at last cost time:" + insertAtLastTime(array));
System.out.println("linked insert cost at last time:" + insertAtLastTime(linked));
}
//头插
public static long insertArrayListAtFirstTime(List<Integer> list) {
int num = 100000;
long time = System.currentTimeMillis();
for (int i = 1; i < num; i++) {
list.add(0, i);
}
return System.currentTimeMillis() - time;
}
//头插
public static long insertLinkedListAtFirstTime(LinkedList<Integer> list) {
int num = 100000;
long time = System.currentTimeMillis();
for (int i = 1; i < num; i++) {
list.addFirst(i);
}
return System.currentTimeMillis() - time;
}
//中间插入数据
public static long insertInMiddleTime(List<Integer> list) {
int num = 10000000; //表示要插入的数据量
long time = System.currentTimeMillis();
for (int i = 1; i < num; i++) {
list.add(list.size() >> 1, i);
}
return System.currentTimeMillis() - time;
}
//尾插
public static long insertAtLastTime(List<Integer> list) {
int num = 1000000; //表示要插入的数据量
long time = System.currentTimeMillis();
for (int i = 1; i < num; i++) {
list.add(i);
}
return System.currentTimeMillis() - time;
}
public static long getTime(List<Integer> list) {
long time = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
int index = Collections.binarySearch(list, list.get(i));
if (index != i) {
System.out.println("ERROR!");
}
}
return System.currentTimeMillis() - time;
}
这个是运行时间:
array get cost time:6
linked get cost time:4170
array insert in first cost time:2927
linked insert cost in first time:4
array insert in middle cost time:1887
linked insert cost in middle time:124
array insert at last cost time:23
linked insert cost at last time:92
这里我们可以看出,对于大数据的随机查询,ArrayList比较快。对于插入,需要区分头插、中间插入和尾插的区别:
- 头插:ArrayList 需要做大量的位移和复制操作,而LinkedList的优势就体现出来了,耗时只是实例化一个对象,相对来说,LinkedList 在大量插入的情况下,相对较快。
- 中间插入:ArrayList 中间插入,首先我们知道他的定位时间复杂度是O(1),比较耗时的点在于数据迁移和容量不足的时候扩容。LinkedList 中间插入,链表的数据实际插入时候并不会怎么耗时,但是它定位的元素的时间复杂度是O(n),所以这部分以及元素的实例化比较耗时。
- 尾插:ArrayList 不需要做位移拷贝也就不那么耗时了,而 LinkedList 则需要创建大量的对象。所以这里ArrayList尾插的效果更好一些。
不过我们从源码比较知道LinkedList性能比较差的原因是因为在中间插入的时候,性能耗在了查询相应的位置上面了,如果只是直接在首插入的话,性能还是ArrayList快。