内存管理
内存是计算机中重要部件之一,是与CPU进行沟通的桥梁。用于暂存CPU中的运算数据、以及与硬盘等外部存储器交换的数据。
利用和管理计算机内存资源。
内存管理演变史
早期,程序直接运行在物理内存上,直接操作物理内存,这种方式存在几个问题:
- 地址空间不隔离:程序操作相同地址空间会造成互相影响甚至崩溃,而且安全性也得不到保证;
- 使用效率低:没有特别好的策略保证多个进程对超过物理内存大小的内存需求的满足;
- 程序运行地址不确定:程序运行时,都需要分配空闲区域,而空闲位置不确定,会带来一些重定位问题;
内存管理主要就是想办法解决上面三个问题;
虚拟内存
计算机系统里任何问题都可以靠引入一个中间层来解决,内存管理就在程序和物理内存之间引入了虚拟内存的概念;对进程地址和物理地址进行隔离;
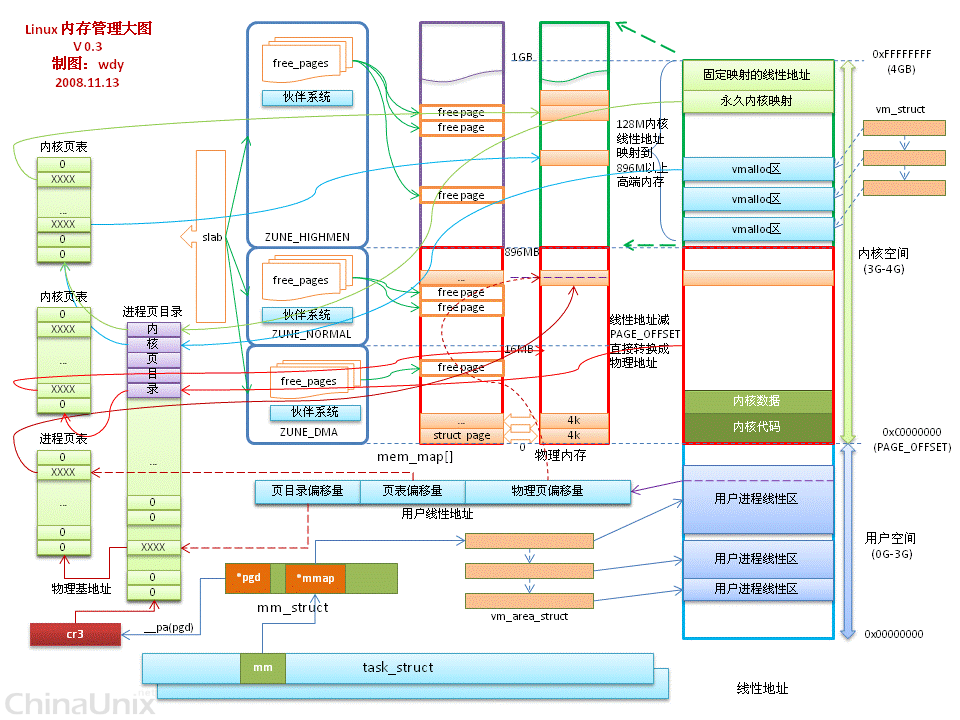
内存分区(ZONE)
Linux 对内存节点进行分区;将节点分为DMA、Normal、High Memory 内存区;
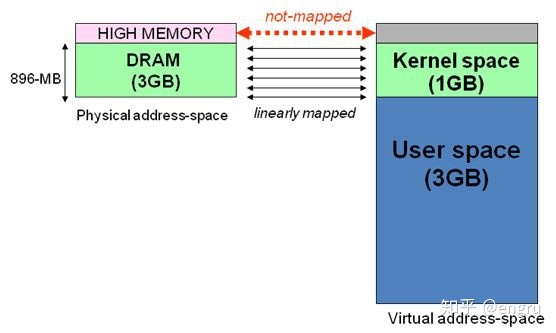
- DMA内存区:直接内存访问区,通常为物理内存的起始16M;主要供I/O外设使用,无需CPU参与的外设和内存DMA;
- Normal内存区:从16M到896M内存区;内核可以直接使用
- Hight Memory内存区:896M以后的内存区;高端内存,内核不能直接使用
内核空间和用户空间
Linux 操作系统,将虚拟内存划分为内核空间和用户空间;
用户进程只能访问用户空间的虚拟地址,只有通过系统调用、外设中断或异常才能访问内核空间;
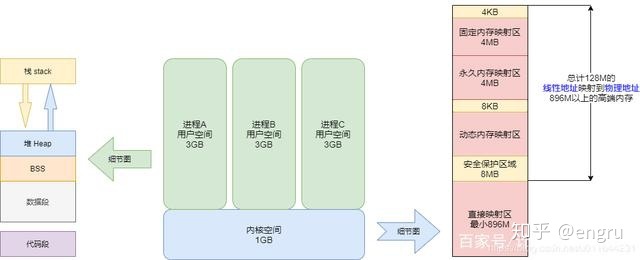
内核空间:
Linux内核空间 1G容量,包括:内核镜像、物理页面表、驱动程序等;
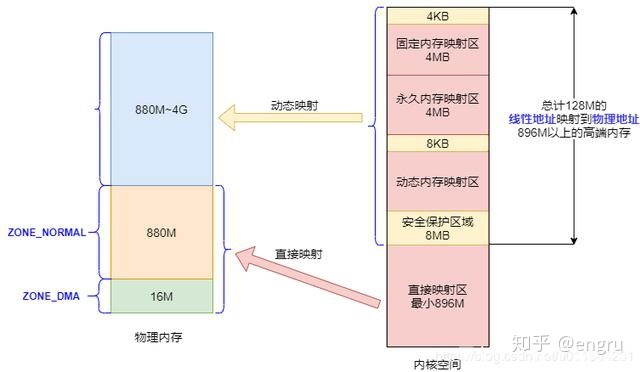
- 直接映射区:最大896M
- 高端内存线性地址空间:共128MB
- 动态内存映射区(vmalloc region):由内核函数vmalloc 分配;
- 永久内存映射区:alloc_page、 kmap
- 固定映射区:特定用途,如 ACPI_BASE 等
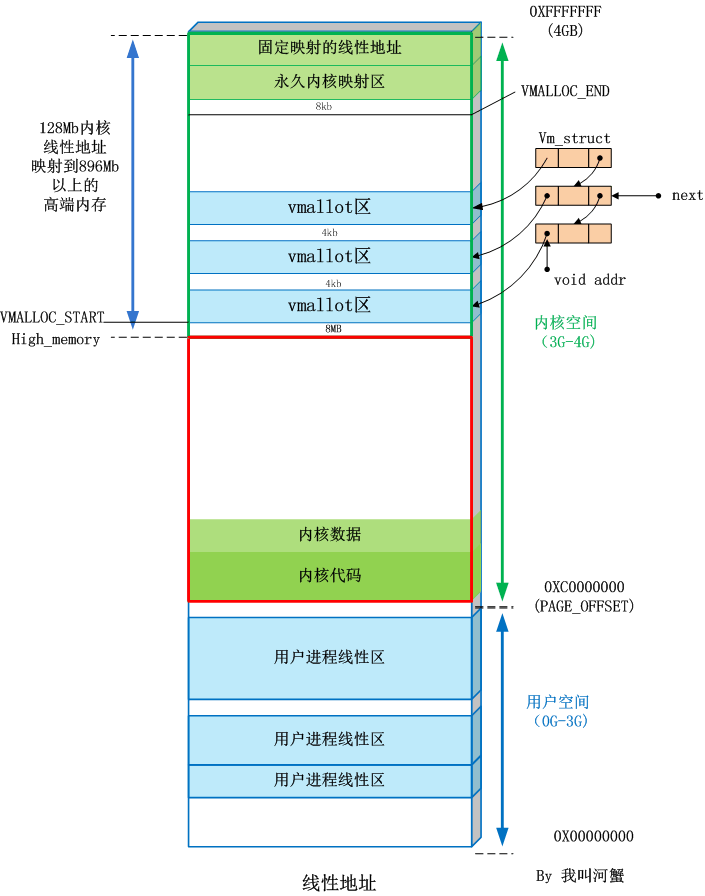
用户空间:分为5个不同内存区域:
- 代码段:只读,存放可执行文件的操作指令;镜像;
- 数据段:存放可执行文件中已初始化全局变量;存放静态变量和全局变量;
- BSS段:未初始化全局变量
- 堆:存放被动态分配的内存段;
- 栈:存放临时创建的局部变量;
内存地址映射
CPU生成的地址是逻辑地址,而内存单元中的地址为物理地址;
执行时地址绑定方案会生成不同的逻辑地址和物理地址,这时,逻辑地址通常被称为虚拟地址
虚拟地址空间
物理地址空间是有限的,虚拟地址空间可以是任意大小;
程序可以通过操作虚拟地址,把虚拟地址空间映射到物理地址空间; Linux通过缺页中断和swap机制,实现虚拟地址映射;
虚拟地址优点:
- 避免直接访问物理内存地址,保护操作系统
- 每个进程都被分配4GB虚拟内存;可使用比实际物理内存更大的地址空间。
分页和分段
虚拟地址和物理地址,主要通过分段和分页技术,进行映射;
程序地址:段号+页号+页内偏移;
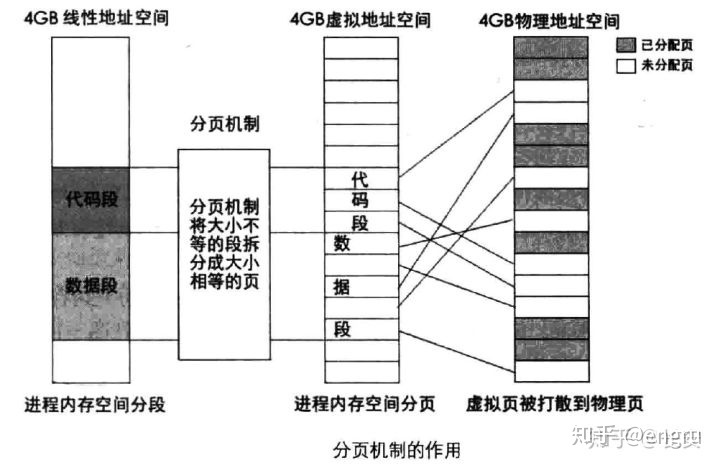
段和页的区别:
- 段是信息的逻辑单位,根据用户的需要划分,段对用户是可见的; 页时信息的物理单位,为管理内存方便和划分的,对用户透明的。
- 段的大小不固定,根据功能觉得;页的大小固定,由系统觉得;
- 段向用户提供二维地址空间;页向用户提供一维地址空间;
- 段便于存储保护和信息共享;页的保护和共享受到限制;
- 分段和分页:分页的粒度更小;
分段:将程序分为代码段、数据段、堆栈段等; 分页:将段分成均匀的小块,通过页表映射物理内存;
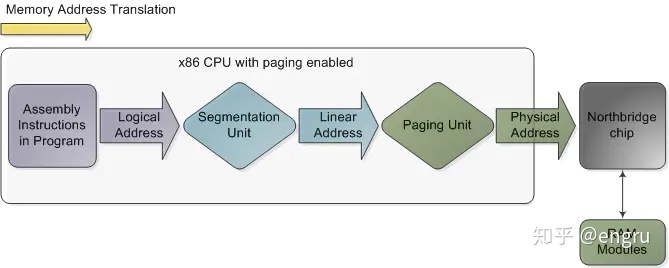
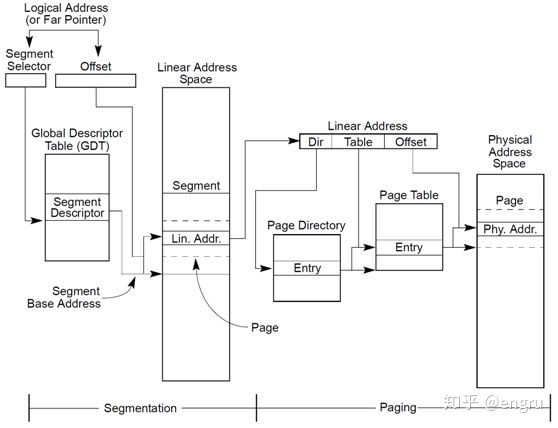
GDT:全局描述表,也就是段表,提供段氏存储机制;存储分段基址信息; CPU访问使用逻辑地址; 分段机制,将逻辑地址转换成线性地址,也就是分页系统中的虚拟地址; 分页机制,将虚拟地址转换为物理地址;
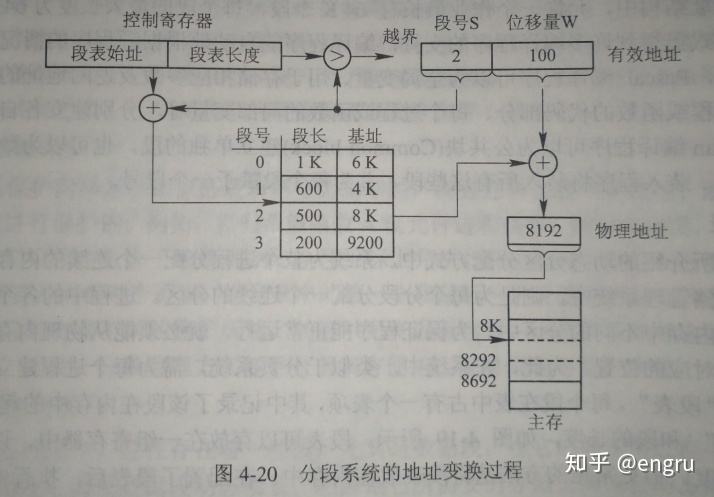
分段(Segmentation)
分段地址通过段表,转换成线性地址; 分段地址包括段号和段内地址; 段表,包括短号、段长、基址;
分页(Page)
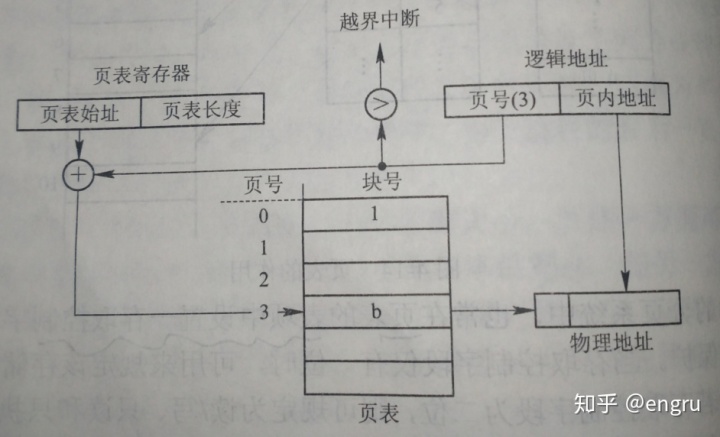
分页机制就是将虚拟地址空间分为大小相等的页;物理地址空间也分为若干个物理块(页框);页和页框大小相等。实现离散分配; 分页机制的实现需要 MMU 硬件实现;负责分页地址转换; 页大小(粒度)太大浪费;太小,影响分配效率
线性地址通过页表转换成物理地址; 分页地址包括页号P和位偏移量W; 页表,包括页号、物理块号、存取控制; 页表作用就是实现页号到物理块号的地址映射;
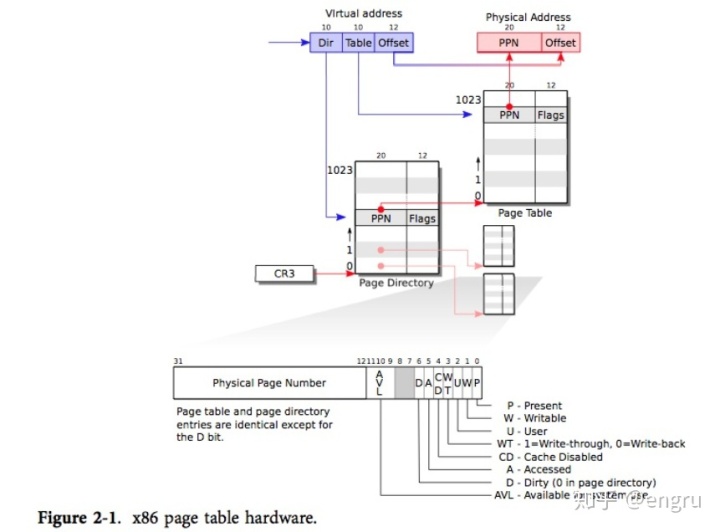
多级页表
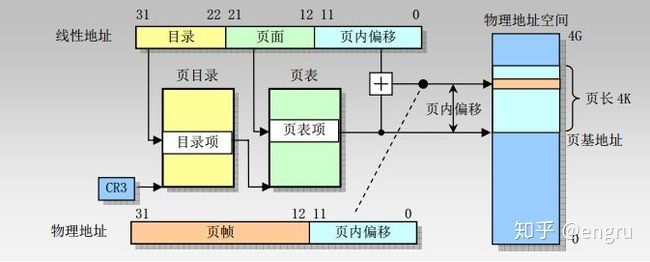
内存分配
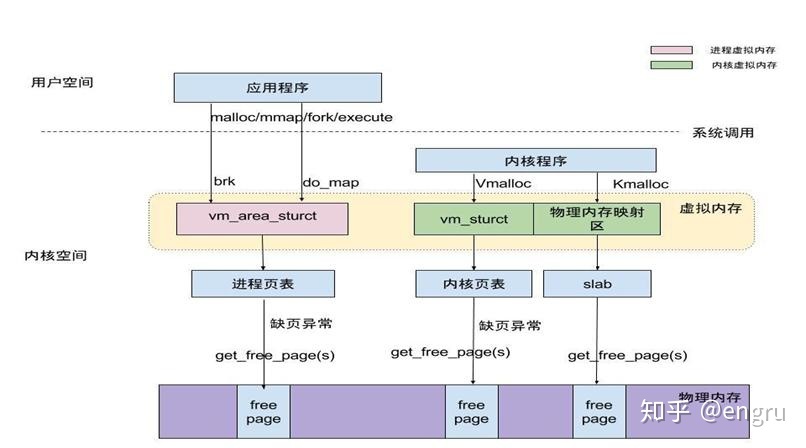
用户进程通常只能访问用户空间的虚拟地址,不能访问内核空间的虚拟地址;
内存管理问题: 内存碎片太小和管理内存碎片的效率问题
内存碎片
内存碎片:回收内存时,将内存块放入空闲链表中; 因内存越分越小,内存块小而多;当需要一块大内存时,尽管此时空闲内存综合可能满足需求,但过于零散,没有一个合适的内存块
内存碎片产生原因:分配内存时,不能将相邻内存合并;
解决内存碎片的方法:
- 小内存单独分配(内存池)、大内存由操作系统分配
- 伙伴系统算法
- slab 算法
如何避免内存碎片:
- 少用动态内存分配函数(尽量使用栈空间)
- 分配内存和释放的内存尽量在同一个函数中
- 尽量一次性申请较大的内存,而不要反复申请小内存
- 尽可能申请大块的2的指数幂大小的内存空间
- 外部碎片避免:伙伴系统(Buddy)算法
- 内部碎片避免:slab算法
- 自己进行内存管理工作,设计内存池
外部碎片
外部碎片,是指还没有被分配出去,但由于太小无法分配的内存空闲区域;
伙伴系统算法(Buddy System)
为内核提供了一种用于分配一组连续的页而建立的一种高效的分配策略,并有效解决了外碎片问题; 分配的内存区以页框为基本单位;
Linux 内核使用伙伴系统算法,把所有的空闲页框分组为11个块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续页框的页框块。最大可申请1024个连续页框,对应4MB大小的连续内存。每个页框块的第一个页框的物理地址是该块大小的整数倍;
SLAB分配器
伙伴系统是以页为单位管理和分配内存。但显式需求却以字节为单位,使用伙伴系统就会严重浪费内存(产生内部碎片)。
slab分配器专为小内存分配而生(解决内部碎片); slab分配器分配内存以Byte为单位; 基于伙伴系统分配的大内存,进一步细分成小内存分配;
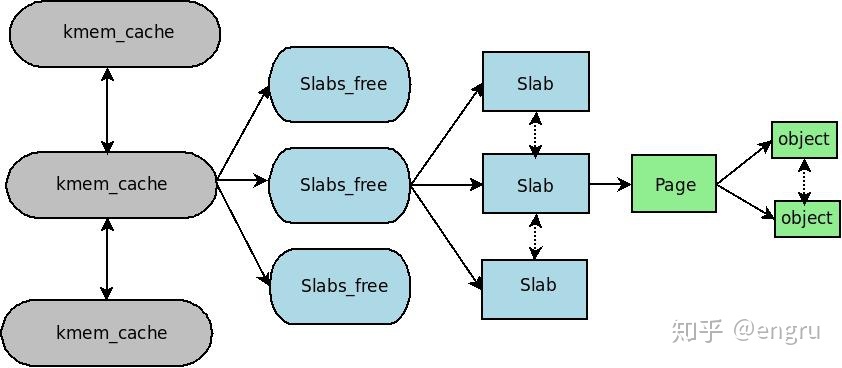
高速缓存/TLB控制
slab 高速缓存分为两大类:普通高速缓存和专用高速缓存;
内存分配函数
https://www.jianshu.com/p/e42f4977fb7e
kmalloc/ vmalloc / malloc
- malloc :负责分配用户空间内存。标准c库提供了 malloc/free 函数分配释放内存,底层由 sark、brk、mmap、munmap系统调用实现。
- kmalloc:负责分配内核空间内存。用于申请较小、连续的物理内存。以字节为单位进行分配, slab;
- vmalloc:负责分配内核空间内存。用于申请较大的内存空间,虚拟内存是连续的,以字节为单位进行分配;分配速度要慢;
常用函数总结
用户空间: malloc/calloc/realloc/free alloca mmap/munmap brk/sbrk
内核空间: vmalloc/vfree
内核空间slab: kmalloc/kcalloc/krealloc/kfree kmem_cache_create
内核空间buddy: **get_free_page/**get_free_pages alloc_page/alloc_pages/free_pages
页面置换算法
当发生缺页中断时,操作系统必须在内存中选择一个页面将其换出,以便为即将调入的页面腾出空间;
常见置换算法有以下四种:
最佳置换算法(OPT)(不可能实现)
淘汰以后永不使用或最长时间内不再被访问的页面;保证获得最低的缺页率。 但操作系统无法知道各个页面下一次将在什么时候被访问,因此该算法是无法被实现的;
先进先出(FIFO)置换算法
优先淘汰最早进入内存的页面;实现简单,但性能差;
Belady异常:FIFO算法会产生当所分配的物理块数增大而页故障数不减反增的异常现象;
最近最少使用(LRU)置换算法
置换未使用时间最长的页面; LRU是堆栈类算法,性能较好,但需要寄存器和栈的硬件支持;实现起来困难,且开销大;
时钟(CLOCK)置换算法
环形链表,也叫NRU算法