1. 简介
1.1 什么是循环依赖
循环依赖,举一个简单的例子,在类A中依赖的类B,然后再类B中,依赖类A。这就是循环依赖。
Class A{
private B b;
...
}
Class B{
private A a;
...
}
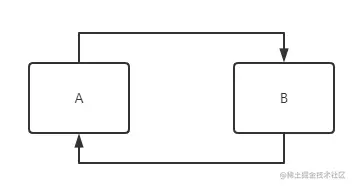
然而在实际项目中,类的依赖情况可能更加复杂,并不能直观的可以看出是循环依赖。在开发中,往往很容易忽视所用类的依赖情况,基本上就是需要实现某个业务功能,需要编辑某个类,发现需要用到别的实现类,然后将它注入,调用方法。很多情况不会关注是否会造成循环依赖等等。
1.2 循环依赖会带来什么问题
那么,循环依赖会带来什么问题?
1)对象直接互相引用,即使这些对象没有被使用了,也不会被垃圾回收,会一直占用系统资源。
2)在创建对象的时候,会不断地递归创建对象。以上述为例,在创建对象A之后,会去进行属性赋值,会去创建对象B,创建对象B之后,发现B依赖类A的对象,于是又会去创建一个对象A。递归...不断地创建对象,不断地调用构造方法,会导致堆栈内存溢出。
2. Spring的应对策略
2.1 Spring三种注入方式
Field属性注入
@Controller
public class HelloController {
@Autowired
private AlphaService alphaService;
@Autowired
private BetaService betaService;
}
Field属性注入是目前比较常用的一种方式,因为用起来很简单便捷。直接声明好需要使用哪个Bean。IOC容器会自动进行Bean的注入。但是这种方式不被推荐。因为使用这种方式,开发者很容易会忽视使用类的依赖注入的情况。我们在代码涉及的时候通常要考虑“ 单一职责原则 ”,即一个类应该只负责一项职责。这个类所提供的所有服务都应该只为它负责的职责服务。
并不是说使用Field属性注入有没什么不对,只是这种方式很容易把“问题”隐藏起来。开发者一味地追求书写方便,简洁。但最后发现,一个类中,什么样的功能都有,什么样的依赖都注入。一个类所提供的服务就不单纯。会增加后续地代码维护成本。
回到循环依赖这个问题上,在单例Bean作用域下, 通过Field属性注入造成的循环依赖,Spring是有自己的解决方案的,就是说,即使你不小心写了循环依赖的代码了,没关系,系统不会报错,Spring帮你处理好了。具体如何处理的,还请往下看。
setter方法注入
@Controller
public class HelloController {
private AlphaService alphaService;
private BetaService betaService;
@Autowired
public void setAlphaService(AlphaService alphaService) {
this.alphaService = alphaService;
}
@Autowired
public void setBetaService(BetaService betaService) {
this.betaService = betaService;
}
}
在Spring3.x的版本中,官方在对比构造器注入和setter方法注入的时候,推荐使用setter方法注入。
原因在于,如果使用构造器注入的时候,需要注入的依赖很多,构造器会显得很臃肿。
还有就是,使用构造器注入的依赖,依赖都要有这些依赖,些依赖不能为null。在面对一些可选依赖的时候就显得不太灵活。有一些依赖,即使不进行依赖注入也不会影响整个类的服务的提供。
在单例Bean作用域下,对于setter方法注入引起的循环依赖问题,Spring也提供了解决方案,无需开发者关系解决细节,可以放心开发业务功能。
构造器注入
@Controller
public class HelloController {
private AlphaService alphaService;
private BetaService betaService;
@Autowired
public void setAlphaService(AlphaService alphaService) {
this.alphaService = alphaService;
}
@Autowired
public void setBetaService(BetaService betaService) {
this.betaService = betaService;
}
}
在Spring4.x的时候,官方对比构造器注入和setter方法注入,推荐使用构造器注入。因为使用构造器注入可以保证依赖不为null。相比setter方法注入,构造器注入因为构造方法只会调用一次。
对于循环依赖这个问题来说,在单例Bean作用域下,如果Spring识别到了构造器注入引起的循环依赖,会直接报错。并不能直接去处理。
2.2 制胜关键-Spring三级缓存
Spring提供了三级缓存来解决 单例Bean 循环依赖问题。
代码位置:DefaultSingletonBeanRegistry.class
// 一级缓存
private final Map<String, Object> singletonObjects = new ConcurrentHashMap(256);
// 三级缓存
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap(16);
// 二级缓存
private final Map<String, Object> earlySingletonObjects = new HashMap(16);
在了解三级缓存之前,必须明白Spring Bean大致的生命周期。Bean的生命周期主要分为几个大的步骤:Bean的实例化 (创建)、属性赋值、初始化、销毁。
每一级缓存都会存储不同类型的数据。
一级缓存:存储已经实例化,属性赋值,初始化好的Bean
二级缓存:存储已经实例化,但是没有属性赋值,没有初始化的Bean
三级缓存:存储Bean的工厂,主要用于生产Bean。
解决循环依赖示例分析 :
代码:
public class A {
@Autowired
private B b;
}
public class B {
@Autowired
private A a;
}
步骤:
1.首先创建对象A,完成对象A的实例化,然后将对象A的工厂对象放到三级缓存中,提前把对象A暴露给IOC容器。
2.实例化对象A之后,接下来就是对A的属性进行赋值或者属性注入。会尝试去获取对象B。
3.发现对象B没有被创建,继而开始对象B的创建过程(实例化、属性赋值、初始化)。
4.在创建对象B的过程中,发现对象B依赖于对象A,然后在三级缓存中尝试查找对象A。
5.在第一步的时候我们知道,对象A的工厂对象被存入到第三级缓存中,对象B根据从第三级缓存获取到的对象A的工厂对象创建对象A。继而将对象A放到二级缓存中,删除第三级缓存中响应的对象A的工厂对象。
6.对象B在获取了对象A之后,继续进行属性赋值和初始化操作。操作完成之后,对象B创建成功,将对象B放入一级缓存中。
7.在对象B完成创建之后,会回到原来对象A的创建过程中,对象A能够在一级缓存找到对象B。进而继续完成创建工作。当继续完成属性赋值,初始化工作之后。会将对象A放入到一级缓存,并删除第二级缓存和第三级缓存中与对象A有关的数据。
所以Spring是通过一系列步骤操作 三级缓存 来解决循环依赖问题的。
2.3 为什么不能解决构造器注入引起的循环依赖
2.3.1 Field注入和setter注入使用三级缓存的情况
在使用Field属性输入和setter注入的时候,创建Bean的逻辑和上述一致。所以可以通过三级缓存来解决循环依赖的问题。
2.3.2 构造器注入使用三级缓存的情况
在之前的了解我们知道,在创建对象过程中,会调用构造方法进行对象的实例化,然后将实例化之后的对象对应的工厂类对象存入第三级缓存。然后才能通过三级缓存的机制去解决循环依赖的问题。但是构造器注入,是指调用构造器的时候进行依赖注入。 调用构造器的时候,对象还没完成实例化完成 。所以还不能存入第三级缓存。也就是说,构造器注入的时候,不能够从三级缓存中获取到相应的对象,所以也就无法通过 三级缓存 解决循环依赖问题。
例子:
Class A{
B b;
@Autowired
public A(B b){
this.b = b;
}
}
Class B{
A a;
@Autowired
public B(A a){
this.a = a;
}
}
在上面这个构造器注入的循环依赖的例子中,类A和类B在调用构造器的时候,对象a和对象b都没有完成实例化,所以都没有存入第三级缓存中。所以注入所需的依赖获取不到。
2.4 为什么不能解决prototype作用域下的循环依赖
prototype作用域下,一个类是可以有多个Bean实例的。Spring对于prototype作用域的Bean,不会进行缓存。所以自然而然,无法利用三级缓存解决循环依赖。