概述
C++的内存回收很麻烦,不回收可能会造成内存泄漏,Java中由GC完成内存回收,不用手动回收内存。
程序计数器占据的内存较小,没有必要进行垃圾回收;虚拟机栈、本地方法栈在进行出栈操作后,会自动回收栈帧使用的内存空间,无需gc进行垃圾回收。
垃圾收集主要针对堆和方法区进行,其中方法区存放的对象十分稳定,存活率极高,通常只在类卸载、常量不被使用的情况下才会产生垃圾。在方法区上进行垃圾回收性价比不高。堆内存占用非常大,对象多,是垃圾回收的重点区域。
类的卸载条件很多,需要满足以下三个条件
- 该类所有的实例都已经被回收
- 加载该类的类加载器已经被回收
- 该类对应的 Class 对象没有在任何地方被引用
即使满足了这3个条件也不一定会被卸载。
标记对象是否为垃圾的算法
对象被判定为垃圾的标准:没有被其它对象引用
引用计数算法
堆中每个对象都对应一个引用计数器,当一个变量引用此对象时,计数器+1;当引用此对象的变量生命周期结束或者被赋新值时,计数器-1;计数器为0时该对象成为垃圾,等待gc回收。
优点:简单、高效
缺点:需要存储每个对象对应的引用计数器,有额外的内存开销;没有处理循环引用问题,存在循环引用时,计数器永不为0,可能导致内存泄漏。
eg. a对象中引用了b对象,b对象中引用了a对象,即存在循环引用,使用引用计数法时,这2个对象的计数器永不为0,永远不会被回收。
即使把这2个变量都置为null,只是引用变成了null,堆中的这2个对象不变,依然持有彼此的引用,它们的计数器也不会为0。
因为引用计数法没有解决循环引用问题,所有主流垃圾收集器都不采用引用计数算法,而采用可达性分析算法。
可达性分析算法
又叫做根搜索算法,使用不同的GC Root,从GC Root开始寻找引用链上的对象,没在任何一条引用链中的对象标记为垃圾。
相比于引用计数法,可达性分析算法同样具备简单、高效的优点,且没有存在循环引用时不能被gc回收的问题。
可以作为GC Root的对象
- java虚拟机栈中的局部变量表中引用的对象
- 本地方法栈中 JNI 引用的对象
- 方法区中类的静态成员、常量引用的对象
- 被同步锁synchronized持有的对象
使用可达性分析算法进行分析时,整个分析过程必须在一个一致的堆内存快照中进行,否则不能保证分析结果的正确性,这也是进行gc时必须stop the world的一个重要原因。
即使是以系统最短停顿时间为目标的CMS收集器,枚举GC Root时也是要停顿的。
对象的finalize机制
根类Object提供了一个finalize()方法,默认是空实现,可以被子类重写。
finalize()类似 C++ 的析构函数,可以用于关闭外部资源,但此方法运行代价很高、不确定性大,无法保证各个对象的调用顺序,最好不要使用,关闭资源可以用 try-finally代替。
当一个对象可被回收时,如果需要执行该对象的 finalize() 方法,那么就有可能在该方法中让对象重新被引用,从而实现自救。自救只能进行一次,如果回收的对象之前调用了 finalize() 方法自救,后面回收时不会再调用该方法。
一个没被任何其它对象引用的对象,只是暂时不被使用,并不一定就是垃圾,可能该类重写了finalize()方法,在finalize()方法中复活、重新使用当前对象。
堆中对象可能的三种状态
- 可触及的:在GC Root的引用链上
- 可复活的:不在GC Root的引用链上,但可能调用finalize()方法进行复活
- 不可触及的:调用了对象的finalize()方法,但该方法中并没有复活当前对象
可达性分析算法至少要经过2次标记,才会把对象标记为垃圾
- 第一次使用GC Root的引用链进行筛选,将不在GC Root的引用链上的对象标记为可复活的
- 第二次对可复活的对象进行筛选
如果对象所属的类没有重写finalize()方法,或者之前已经执行过finalize()方法但没有复活对象,则直接标记为不可触及的;
如果对象所属的类重写了finalize()方法,且之前没有执行过finalize()方法,则把对象放入finalize队列中,
由jvm创建的一个低优先级的finalizer线程处理队列中对象,调用对象的finalize()方法,如果没有复活,则把对象标记为不可触及的。
状态为不可触及的对象才会成为垃圾,等待被gc回收。
引用类型
无论引用计数算法,还是可达性分析算法,判定对象是否可被回收都与对象的引用类型有关。java 提供了四种引用类型。
1、 Strong Reference 强引用
被强引用关联的对象不会被gc回收,一般都是以强引用方式进行关联。
与其它引用类型的区别:强引用禁止引用目标被垃圾收集器收集,而其他引用不禁止。
//eg.使用new来创建强引用,变量user强引用new出来的对象
User user = new User();
2、Soft Reference 软引用
被软引用关联的对象只有在内存不够的情况下才会被回收。
可以使用 SoftReference 类来创建软引用。
User user = new User();
SoftReference<User> sf = new SoftReference<>(user);
//置空对象,使对象只被软引用关联
user = null;
3、Weak Reference 弱引用
被弱引用关联的对象在下次进行垃圾收集时一定会被回收,即只能存活到下一次垃圾回收发生之前。
可以使用 WeakReference 类来创建弱引用。
User user = new User();
WeakReference<User> wf = new WeakReference<>(user);
user = null;
4、Phantom Reference 虚引用
又称为幽灵引用、幻影引用,虚引用不会对关联对象的生存时间造成影响,设置虚引用的目的是在关联对象(目标对象)被回收时可以收到系统通知。
可以使用 PhantomReference类来创建虚引用。
User user = new User();
PhantomReference<User> pf = new PhantomReference<>(user, null);
user = null;
垃圾回收算法
标记-清除算法 Mark-Sweep
- 标记需要回收的对象
- 清除要回收的对象
清除并不是置空,只是把要清除的对象的地址保存在空闲地址列表中,后续分配内存时可以使用这些内存,再次分配时才覆盖原有内容。
缺点:容易产生内存碎片,可能导致后续给大对象分配内存空间时没有足够大的连续内存,从而提前触发下一次gc。
标记-整理算法 Mark- Compact
- 标记需要回收的对象
- 将所有存活的对象压缩(Compact)到内存的一端,然后直接清理掉边界以外的部分。
不会产生内存碎片,但效率要低于复制算法。
复制算法 Coping
将内存划分为2块,每次只使用一块,进行垃圾回收时将存活的对象复制到未使用的一块上,清理掉之前使用的那一块。
不会产生内存碎片,适合对象存活率低的场景,常用于新生代的垃圾回收。
新生代对象存活率低,一般使用复制算法;老年代对象存活率高,一般使用标记-整理算法。
分代收集算法
根据对象存活周期(年龄代)将堆内存划分为几块,不同块使用合适的收集算法。
把堆划分为2大块
- 新生代(Young Gen):包括Eden区、2个Survivor区,默认大小比例8:1:1
- 老年代(Old Gen):老年代内存空间比新生代大得多
新生代使用复制算法,老年代使用标记-清除或标记-整理算法。
对象|内存 分配策略
- 对象主要分配在新生代的 Eden 区上
- 如果启用了本地线程分配缓冲TLAB,则优先分配到线程各自的分配缓冲区中
- 少数情况下会直接分配在老年代中,比如大对象
垃圾回收方式
- 新生代使用复制算法进行垃圾回收,回收时把Eden区、Survivor from区中存活的对象复制到Survivor to中,然后清理掉Eden区、Survivor from区。Survivor from、to是相对的,不是固定的某一块内存空间。
- 老年代使用标记-清除或标记-整理算法进行垃圾回收,不同的垃圾收集器,老年代使用的垃圾回收算法可能不同。
gc分类
- Minor GC:新生代 GC,回收新生代。新生代对象存活时间很短,回收率极高,Minor GC 非常频繁,回收执行速度也很快。
- Full GC:又叫做Major GC,主要回收老年代,但通常伴随着Minor GC,所以可以看做老年代、新生代都在回收,收集整个堆。老年代内存大、对象多,对象存活时间长,相比于Minor GC,Full GC执行次数较少、回收速度慢。
minor gc的触发条件
- Eden区空间不足
full gc的触发条件
- 老年代空间不足
- 调用System.gc()。虽然只是建议进行Full GC,但一般都会进行
- 新生代空间不足时使用老年代的内存空间进行分配担保(Handle Promotion),分配担保失败时会触发full gc
分配担保:新生代对象存活率偏高,Survivor to中放不下时,会使用老年代的空间进行分配担保,即把Survivor to中放不下的对象直接放到老年代中。
full gc时间花销大,造成的停顿时间较长,看到jvm频繁进行full gc时要引起注意,应该进行优化。
对象如何晋升到老年代
- 经历指定的Minor GC次数仍然存活,默认15次
- 新生代空间不足时使用老年代的内存空间进行分配担保,Survivor to中放不下的对象直接放到老年代中
- 大对象直接在老年代进行分配
堆外内存(直接内存)的回收
DirectByteBuffer对象本身是直接分配在老年代的,对象本身可在Full GC时被回收,但DirectByteBuffer申请使用的是直接内存,所引用的直接内存不在gc回收范围内,不会被gc回收。
jdk提供了一种机制:可以给堆中的对象注册一个钩子函数(其实就是实现 Runnable的一个子接口),当堆中的对象被GC回收的时候,会回调run()方法。
Unsafe类提供了大量的native方法,可以在run()方法中调用Unsafe类的freeMemory()方法,释放DirectByteBuffer对象引用的直接内存。
垃圾收集器
stop the word:jvm进行垃圾回收时会暂停应用程序的执行(暂停所有用户线程),gc完成才会继续执行应用程序,主流垃圾收集器或多或少都存在这各个情况。
safepoint:安全点,标记阶段对象引用关系不会发生变化的点,比如方法调用、循环跳转处。
JVM的2种运行模式
- client模式:使用轻量级虚拟机,适合对性能要求不高的项目,常用于桌面程序。桌面程序内存占用小,一般就几十兆、两三百兆。
- server模式:使用重量级虚拟机,启动慢,但做了更多的优化,稳定运行后性能更高,适合对性能要求高的项目,常用于java web项目。
使用java -version可以查看jvm的种类、运行模式,HotSpot默认使用server模式。
新生代常见的3种收集器
Serial收集器
- 使用单线程进行垃圾回收
- 使用复制算法
- 性能低,常用于桌面程序,是HotSpot虚拟机client模式下默认的新生代垃圾收集器
ParNew收集器
- 使用多线程进行垃圾回收,相当于Serial的多线程版本
- 使用复制算法
- 是web应用主流使用的新生代垃圾收集器,一个重要原因是ParNew是能与CMS搭配使用少数新生代收集器之一
Par是Parallel的缩写
#使用ParNew收集器,+是启用,-是取消
-XX:+UseParNewGC
#可以指定进行垃圾回收的线程数,默认为cpu核心数
-XX:ParallelGCThreads=8
Parallel Scavenge收集器
- 使用多线程进行垃圾回收
- 使用复制算法
- 吞吐量优先
- 是HotSpot虚拟机在server模式下默认的新生代垃圾收集器
与其它收集器不同,其它收集器关注缩短系统停顿时间,而 Parallel Scavenge关注吞吐量
吞吐量 = 运行用户代码的时间 / (运行用户代码的时间 + 垃圾收集时间)
高吞吐量可以高效利用cpu执行程序代码,适合在不需要太多交互的应用中使用。
Parallel Scavenge可以使用gc自适应调节:jvm根据当前运行状况,动态调整设置最适合的gc停顿时间、吞吐量
#启用gc自适应调节
-XX:UseAdaptiveSizePolicy
#也可以使用以下方式进行手动设置,但一般不手动设置
#设置gc最大暂停时间,在这个时间范围内,至少进行一次gc
-XX:MaxGCPauseMillis=600000
#设置吞吐量,默认99,即吞吐量为99%
-XX:GCTimeRatio=99
老年代常见的3种收集器
Serial Old
- 和Serial 一样使用单线程进行垃圾回收
- 使用标记整理算法
- 用于老年代的垃圾回收,是HotSpot虚拟机 Client模式下默认的老年代垃圾回收器
Parallel Old(默认)
- 使用多线程进行垃圾回收
- 使用标记整理算法
- 吞吐量优先
- 是HotSpot虚拟机在server模式下默认的老年代收集器
#取消默认的Parallel Old收集器
-XX:-UseParallelOldGC
CMS收集器
- 使用标记-清除算法
- 关注系统停顿时间,以系统最短停顿时间为目标,适合与用户交互多的程序。
- 是server模式下主流的老年代垃圾收集器
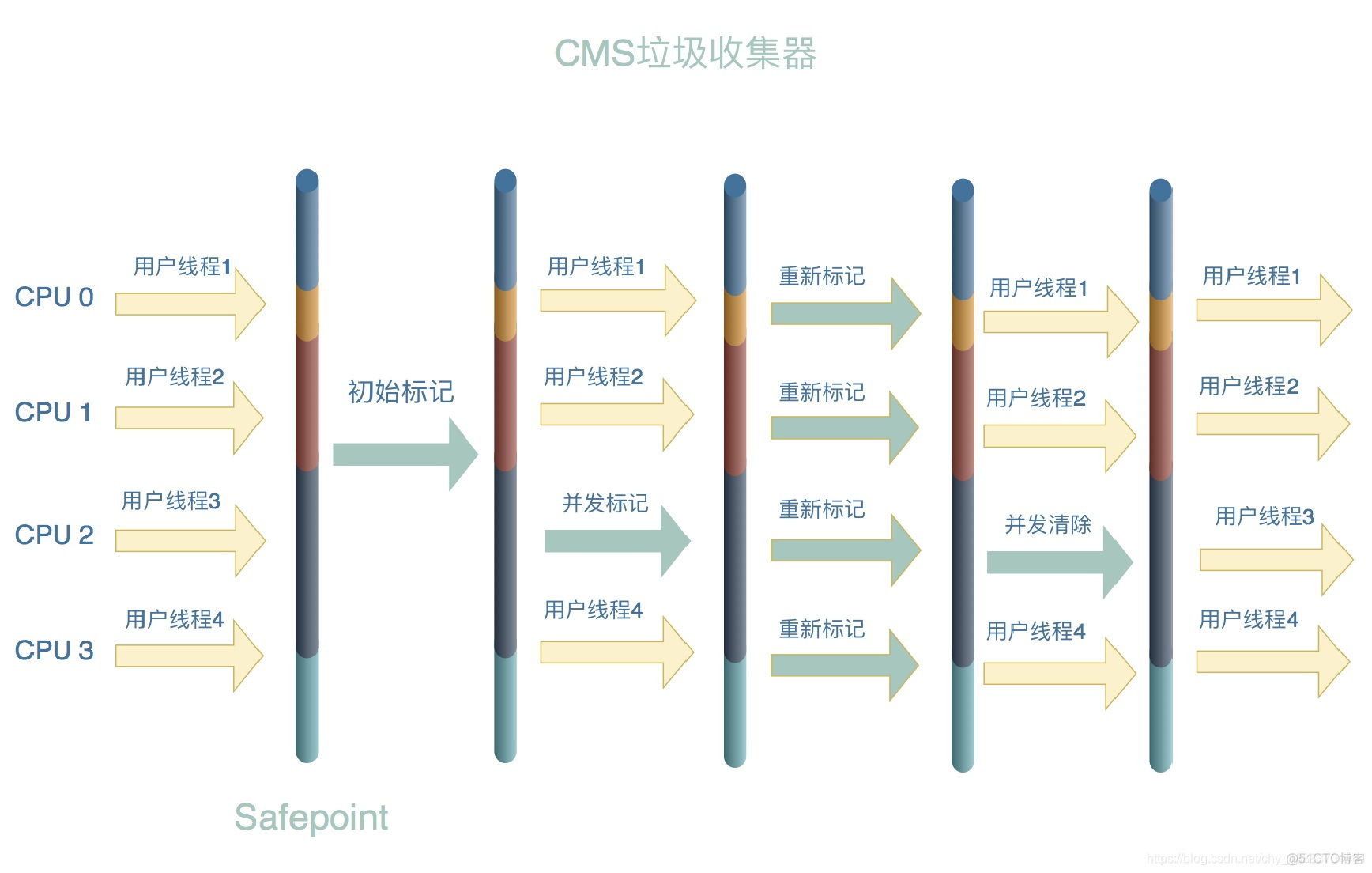
cms进行垃圾回收的主要步骤
- 初始标记 :标记作为GC Root的对象(stop the world)
- 并发标记:根据可达性分析算法找出所有的引用链
- 重新标记:修正并发标记期间因用户程序导致的标记变动(stop the world)
- 并发清除:回收标记对象
只在初始标记、重新标记阶段出现stop the world,其它回收阶段可以和用户线程并发执行,回收垃圾引起的系统停顿时间几乎可以忽略不计。
web服务端重视响应速度,希望gc引起的系统停顿时间尽可能短,以带给用户更好的体验,cms正好符合web应用的需求,是java web应用老年代主流使用的垃圾收集器。
说明
和其它收集器不同,cms在垃圾收集阶(并发清除)段还需要运行应用,需要预留足够的内存空间供应用使用,所以cms不能像其它收集器一样等到老年代快满了才进行垃圾回收。
如果cms预留的内存空间不能满足应用运行的需要,jvm会临时使用Serial Old代替cms收集老年代,引起的停顿时间较长。
cms的优缺点
- 优点:并发收集,系统停顿时间短
- 缺点:本次回收时不能清除并发标记阶段新产生的垃圾;进行并发清除时还要运行应用(运行应用时还需要使用一些线程来并发清除垃圾),对cpu很敏感;使用标记-清除算法,会产生大量的内存碎片。
#启用CMS收集器,CMS是ConcMarkSweep的缩写
-XX:+UseConcMarkSweepGC
整堆收集器 G1
- G1收集器将整个堆划分为多个大小相等的独立区域(Region),可以对整个堆进行垃圾回收
- 使用标记-整理算法,不会产生内存碎片
- 和CMS一样都关注于缩短系统停顿时间,但G1的系统停顿时间是可预测的
- 回收价值大
G1 会跟踪各个 Region 里面垃圾的回收价值,记录回收所获得的空间、所花费的时间,在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的 Region。
这也是 Garbage- Firsti 名称的由来、以及可预测的原因,这种方式保证了 G1 在有限时间内获取尽可能高的回收价值。‘
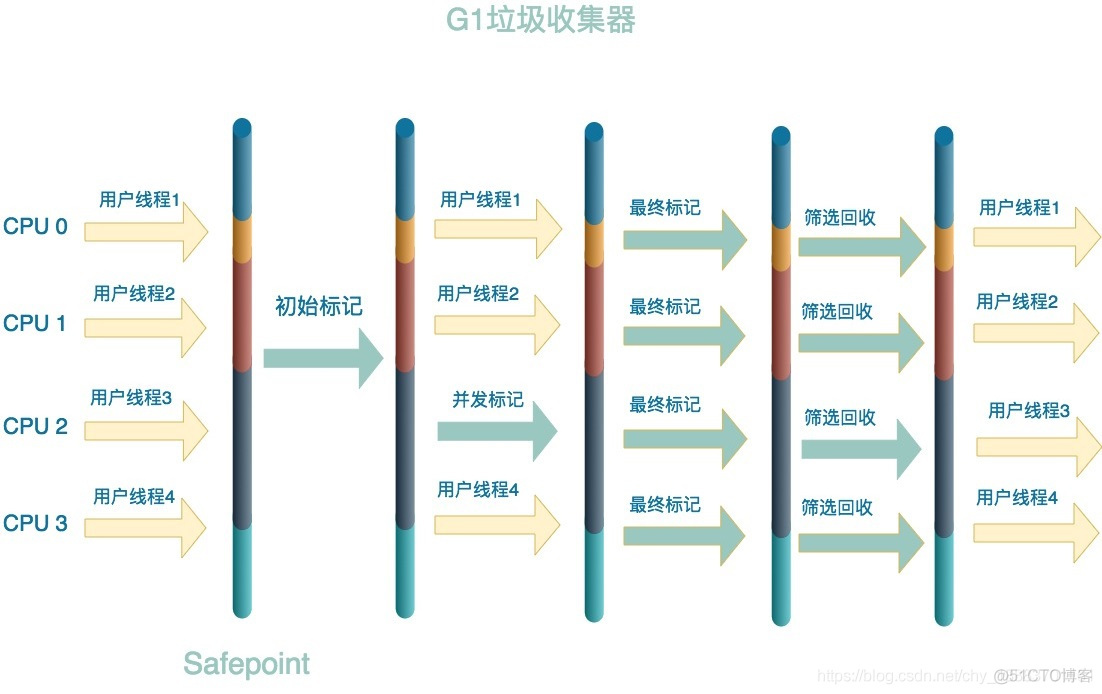
g1进行垃圾回收的主要步骤
-
初始标记(Initial Marking) :标记作为GC Root的对象
-
并发标记(Concurrent Marking):根据可达性分析算法找出各个Region所有的引用链
-
最终标记(Final Marking) :修正并发标记期间因用户程序导致的标记变动
-
筛选回收(Live Data Counting and Evacuation):回收各个Regin中Remembered Set 之外的部分
垃圾收集器总结、选择建议
| 名称 | 收集年代 | 使用的垃圾回收算法 | gc线程 | 关注点 | 地位 |
|---|---|---|---|---|---|
| Serial收集器 | 新生代 | 复制算法 | 单线程 | client模式下默认的新生代收集器 | |
| ParNew收集器 | 新生代 | 复制算法 | 多线程 | 新生代主流使用的收集器 | |
| ParallelScavenge收集器 | 新生代 | 复制算法 | 多线程 | 关注吞吐量 | server模式下默认的新生代收集器 |
| SerialOld收集器 | 老年代 | 标记整理算法 | 单线程 | client模式下默认的老年代收集器 | |
| ParallelOld收集器 | 老年代 | 标记整理算法 | 多线程 | 关注吞吐量 | server模式下默认的老年代收集器 |
| CMS收集器 | 老年代 | 标记清除算法 | 单线程、多线程混合 | 关注缩短系统停顿时间 | 老年代主流使用的收集器 |
| G1收集器 | 所有年代 | 标记整理算法 | 单线程、多线程混合 | 关注缩短系统停顿时间、高价值回收 | 优秀,但低版本jdk中包含的G1版本尚不成熟 |
java web应用的收集器选择
- jdk9及之后版本的jdk:默认收集器是G1,也推荐使用G1
- jdk8及之前版本的jdk:包含的G1版本尚不成熟,推荐使用ParNew收集新生代,使用CMS收集老年代
常用的JVM调优参数
jvm内存不是越大越好,内存太小会频繁GC,内存太大触发GC时停顿时间会较长。根据压测结果不断调整jvm内存大小,合适就好,并非越大越好。
优化指标
- 吞吐量=非GC停顿时间/系统运行总时间,一般要将吞吐量优化到95%甚至98%以上,即GC停顿时间控制在系统运行总时间的2%或5%以内。
- 尽量减少Full GC次数,将单次Full GC造成停顿时间控制在1s以内。
jvm通用调优参数
#启动应用的时候可以设置jvm参数,单位直接用 k、m、g
#在IDEA中同样可以设置jvm参数,参数之间都是用空格分隔
java -Xms512m -Xmx512m -jar xxx.jar
#控制台打印gc信息
-verbose:gc -XX:+PrintGCDetails
#一般将初始堆内存、最大堆内存设置为一样的,防止堆扩容时引起内存抖动、影响程序运行的稳定性
-Xms10g #初始堆内存,默认为物理内存的1/64
-Xmx10g #最大堆内存,默认为物理内存的1/4
-Xss256k #每个线程 java虚拟机栈的大小
-XX:MetaspaceSize=1g #元空间的初始内存
#-XX:MaxMetaspaceSize #元空间的最大内存,默认不限制。jdk的元空间直接使用本地内存,不占用堆内存,不用指定元空间的最大内存。
基于分代收集算法实现的GC的通用调优参数
主流的垃圾回收算法是分代收集算法,以下的jvm调优参数也是针对分代收集算法的
-Xmn512m #新生代大小
-Xx:NewRatio=3 #老年代、新生代的大小比例,默认3
-Xx:SurvivorRatio=8 #Eden区与一个Servivor区的大小比例,默认8。2个servivor区的大小比例默认1:1
-XX:MaxTenuringThreshold=15 #新生代对象晋升到老年代需经历的Minor GC次数,默认15
-XX:PretenureSizeThreshold=3145728 #大对象阈值,单位字节,体积超过这个值就认为是大对象,直接在老年代分配空间
主流收集器各自的调优参数
#ParNew
-XX:+UseParNewGC #启用ParNew收集器
-XX:ParallelGCThreads=n #ParNew回收垃圾使用的线程数。默认为cpu核心数,但使用docker部署应用时,可能取的是物理机的cpu核数,而非分配给容器的cpu核数,最好手动指定,避免踩坑
#CMS
-XX:+UseConcMarkSweepGC #启用CMS收集器,CMS是ConcMarkSweep的缩写
-XX:ParallelCMSThreads=n #CMS回收垃圾使用的线程数,和ParNew的一样,在docker下容易踩坑,应该手动配置
-XX:+UseCMSCompactAtFullCollection #在FullGC后压缩整理内存碎片
-XX:CMSFullGCBeforeCompaction=4 #每隔4次FullGC才整理压缩一次内存碎片
-XX:UseCMSInitiatingOccupancyOnly #使用内存占用阈值触发GC
-XX:CMSInitiatingOccupancyFraction=70 #(老年代)内存占用达到70%就触发GC
#G1
-XX:+UseG1GC #启用G1收集器
-XX:MaxGCPauseMillis=n #GC最大停顿时间,G1会尽可能满足这个参数
-XX:G1HeapReginSize=n #每个Regin的大小
这些jvm调优参数并非1次就确定下来,需要不断调整参数,反复测试查看GC日志,比较效果以找到合适的值。