前言
Java并发编程系列开坑了,Java并发编程可以说是中高级研发工程师的必备素养,也是中高级岗位面试必问的问题,本系列就是为了带读者们系统的一步一步击破Java并发编程各个难点,打破屏障,在面试中所向披靡,拿到心仪的offer,Java并发编程系列文章依然采用图文并茂的风格,让小白也能秒懂。
Java内存模型(Java Memory Model)简称J M M,作为Java并发编程系列的开篇,它是Java并发编程的基础知识, 理解它能让你更好的明白线程安全到底是怎么一回事 。
内容大纲
硬件内存模型
程序是指令与数据的集合,计算机执行程序时,是C P U在执行每条指令,因为C P U要从内存读指令,又要根据指令指示去内存读写数据做运算,所以执行指令就免不了与内存打交道,早期内存读写速度与C P U处理速度差距不大,倒没什么问题。
C P U缓存
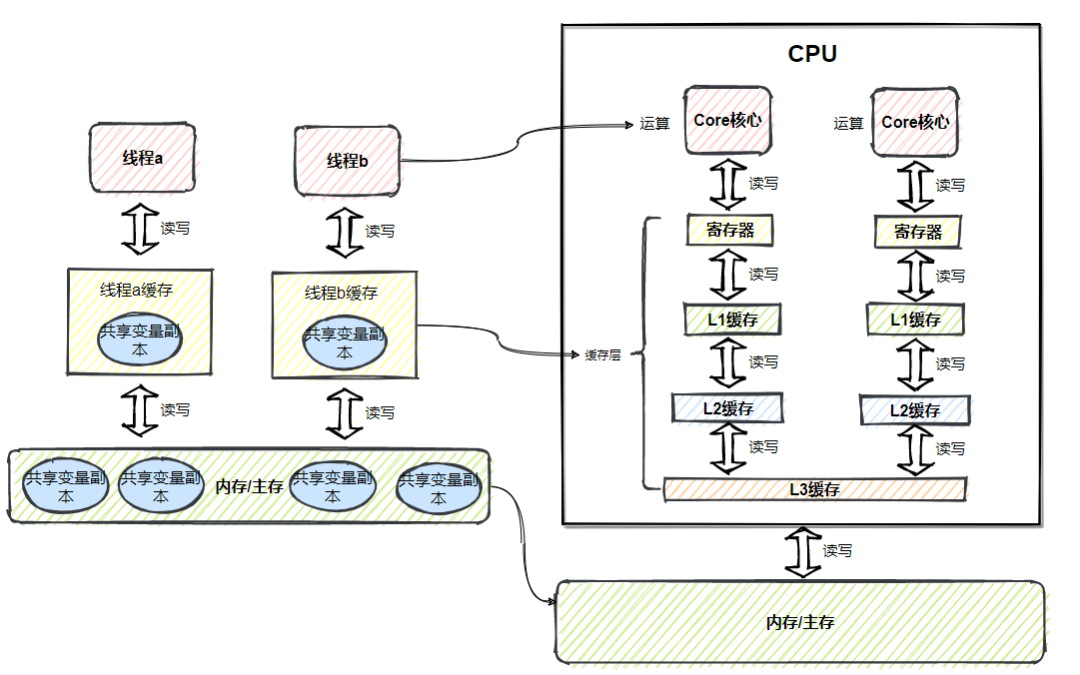
随着C P U技术快速发展,C P U的速度越来越快, 内存却没有太大的变化 ,导致内存的读写(IO)速度与C P U的处理速度差距越来越大,为了解决这个问题,引入了缓存(Cache)的设计,在C P U与内存之间加上 缓存层 ,这里的缓存层就是指C P U内的 寄存器与高速缓存 (L1,L2,L3)
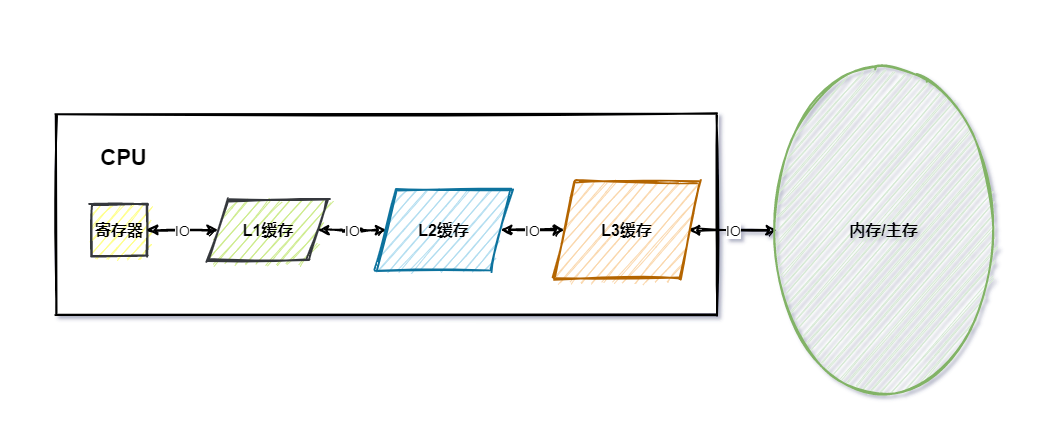
从上图中可以看出,寄存器最快,主内最慢,越快的存储空间越小,离C P U越近,相反存储空间越大速度越慢,离C P U越远。
C P U如何与内存交互
C P U运行时,会将指令与数据从主存复制到缓存层,后续的读写与运算都是基于缓存层的指令与数据,运算结束后,再将结果从缓存层写回主存。
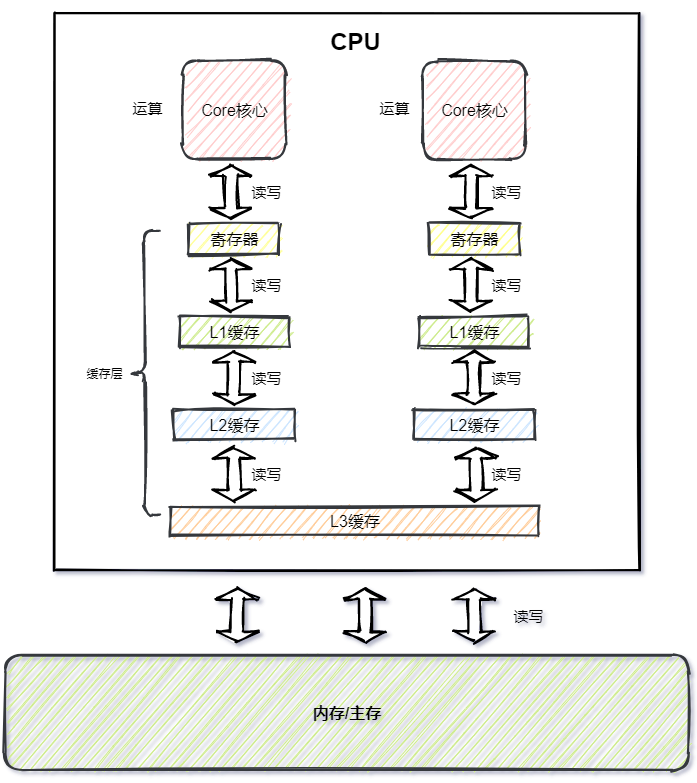
上图可以看出,C P U基本都是在和 缓存层 打交道,采用 缓存设计 弥补主存与C P U处理速度的差距,这种设计不仅仅体现在硬件层面,在日常开发中,那些并发量高的业务场景都能看到,但是凡事都有利弊,缓存虽然加快了速度,同样也带来了在多线程场景存在的 缓存一致性问题 ,关于 缓存一致性问题 后面会说,这里大家留个印象。
Java内存模型
Java内存模型(Java Memory Model,J M M),后续都以J M M简称,J M M 是建立在 硬件内存模型基础上的抽象模型 ,并不是物理上的内存划分,简单说,为了 使 Java虚拟机(Java Virtual Machine,J V M)在各平台下达到一致的内存交互效果, 需要屏蔽下游不同硬件模型的交互差异,统一规范,为上游提供统一的使用接口。
J M M是保证J V M在各平台下对计算机内存的交互都能保证效果一致的机制及规范 。
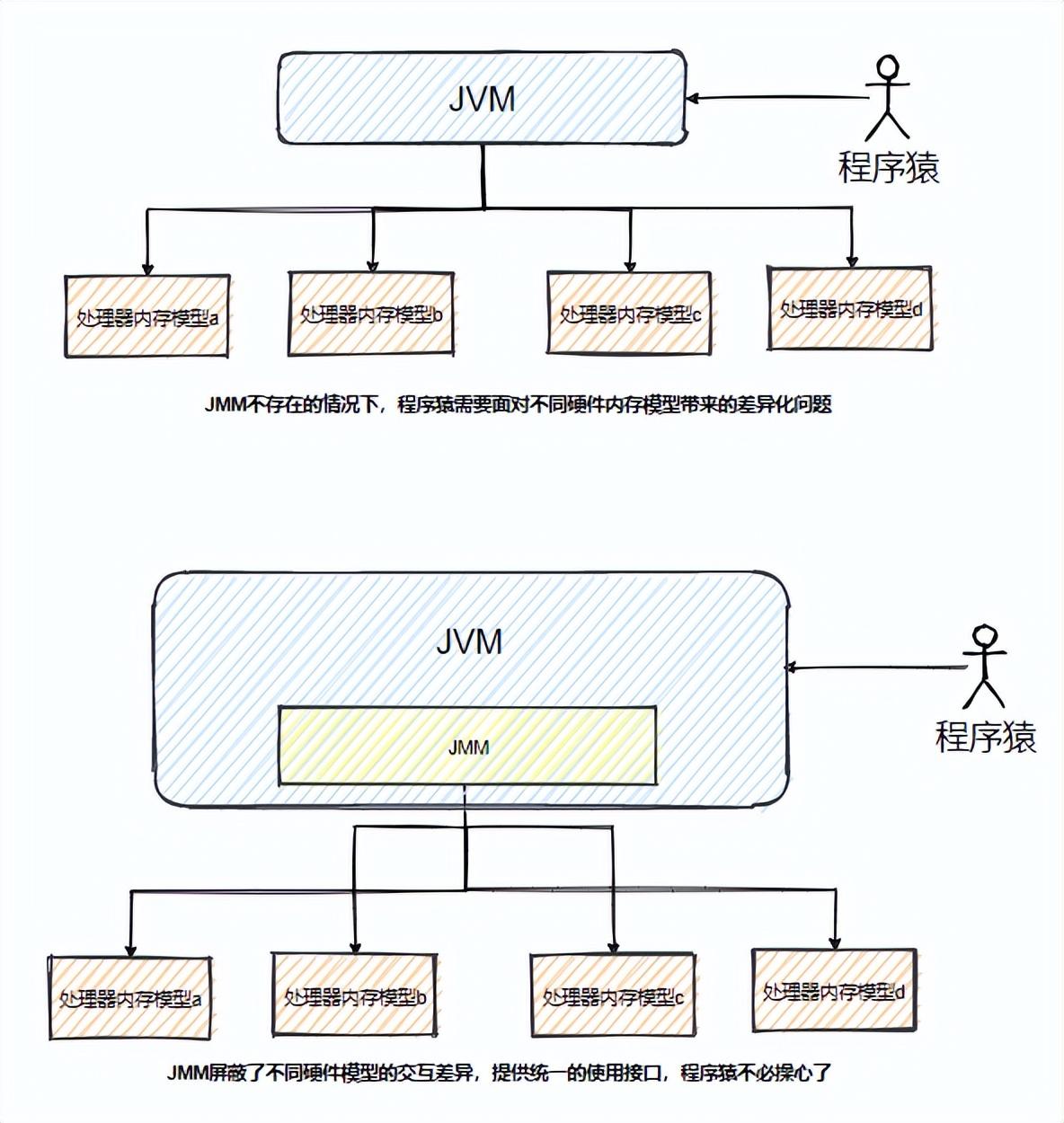
抽象结构
J M M抽象结构划分为线程本地缓存与主存,每个线程均有自己的本地缓存,本地缓存是线程 私有 的,主存则是计算机内存,它是 共享 的。
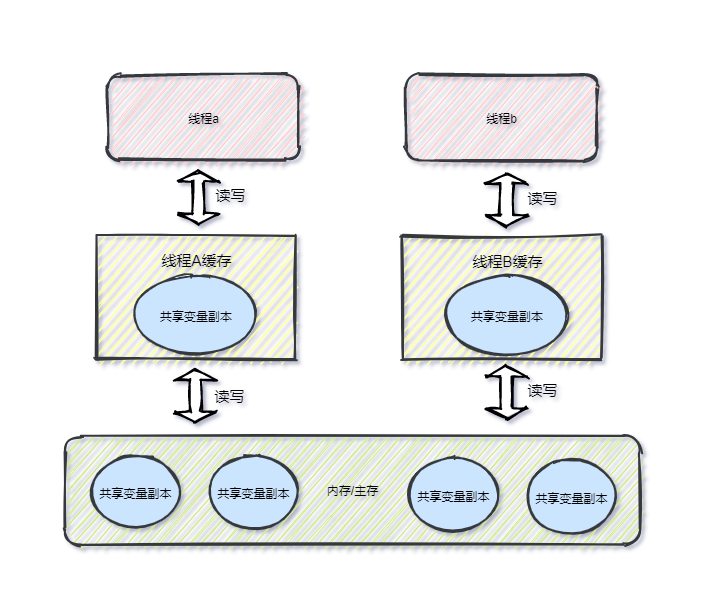
不难发现J M M与硬件内存模型差别不大,可以简单的把 线程 类比成 Core核心 , 线程本地缓存 类比成 缓存层 ,如下图所示
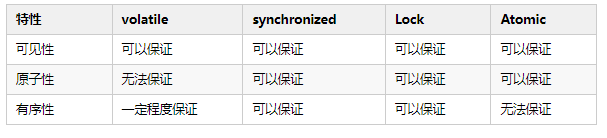
虽然内存交互规范好了,但是多线程场景必然存在线程安全问题( 竞争共享资源 ),为了使多线程能正确的同步执行,就需要保证并发的三大特性 可见性、原子性、有序性 。
可见性
当一个线程修改了共享变量的值,其他线程能够立即得知这个修改,这就是 可见性 ,如果无法保证,就会出现 缓存一致性的问题 ,J M M规定,所有的变量都放在主存中,当线程使用变量时,先从缓存中获取,缓存未命中,再从主存复制到缓存,最终导致线程操作的都是自己缓存中的变量。
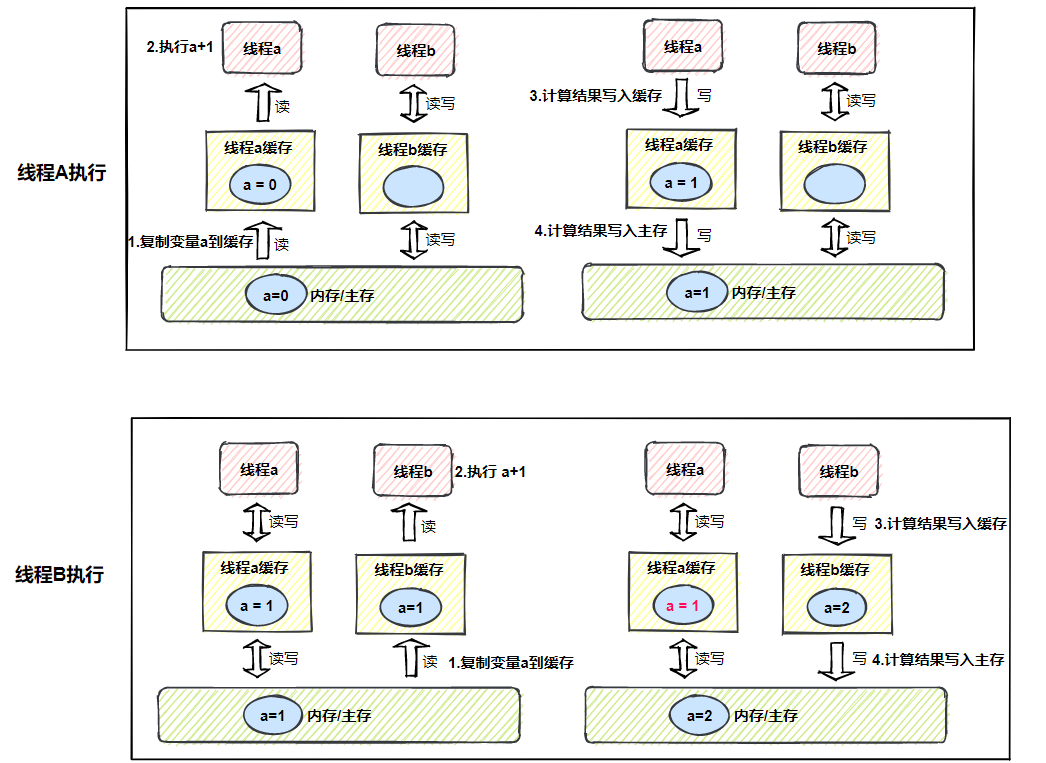
线程A执行流程
- 线程A从缓存获取变量a
- 缓存未命中,从主存复制到缓存,此时a是0
- 线程A获取变量a,执行计算
- 计算结果1,写入缓存
- 计算结果1,写入主存
线程B执行流程
- 线程B从缓存获取变量a
- 缓存未命中,从主存复制到缓存,此时a是1
- 线程B获取变量a,执行计算
- 计算结果2,写入缓存
- 计算结果2,写入主存
A、B两个线程执行完后,线程A与线程B缓存数据不一致,这就是 缓存一致性问题 ,一个是1,另一个是2,如果线程A再进行一次+1操作,写入主存的还是2,也就是说两个线程对a共进行了3次+1,期望的结果是3,最终得到的结果却是2。
解决 缓存一致性问题 ,就要保证 可见性 ,思路也很简单,变量写入主存后,把其他线程缓存的该变量清空,这样其他线程缓存未命中,就会去主存加载。
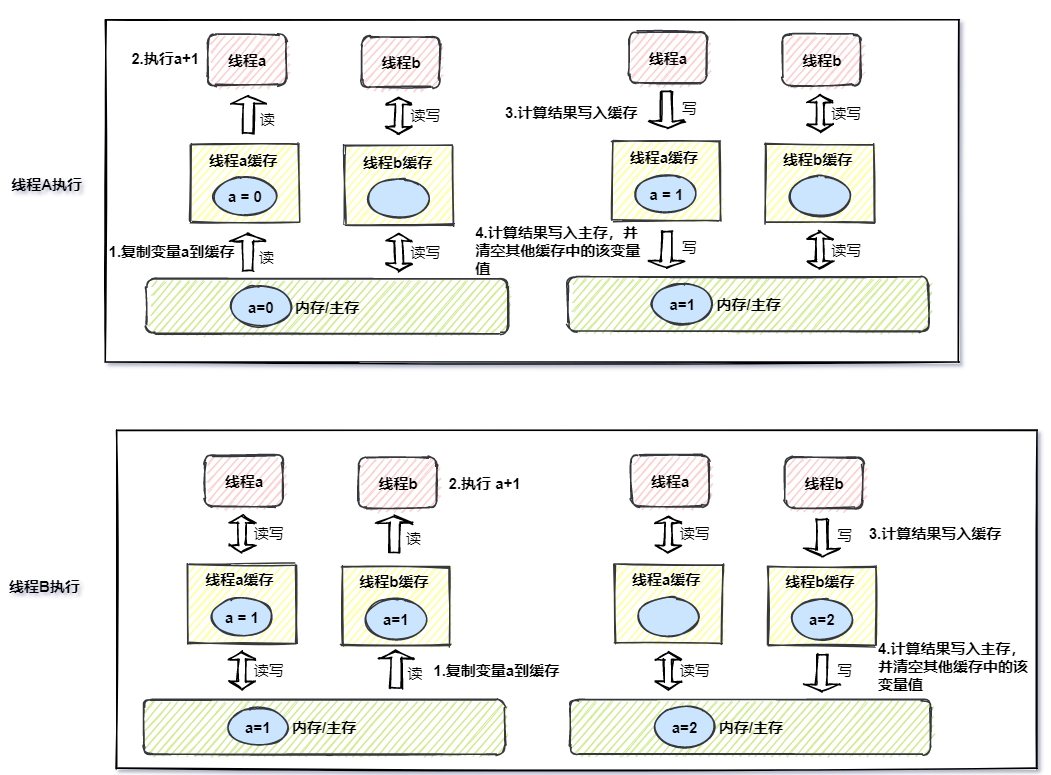
线程A执行流程
- 线程A从缓存获取变量a
- 缓存未命中,从主存复制到缓存,此时a是0
- 线程A获取变量a,执行计算
- 计算结果1,写入缓存
- 计算结果1,写入主存,并清空线程B缓存a变量
线程B执行流程
- 线程B从缓存获取变量a
- 缓存未命中,从主存复制到缓存,此时a是1
- 线程B获取变量a,执行计算
- 计算结果2,写入缓存
- 计算结果2,写入主存,并清空线程A缓存a变量
A、B两个线程执行完后,线程A缓存是空的,此时线程A再进行一次+1操作,会从主存加载(先从缓存中获取,缓存未命中,再从主存复制到缓存)得到2,最后写入主存的是3,Java中提供了volatile修饰变量保证 可见性 (本文重点是J M M,所以不会对volatile做过多的解读)。
看似问题都解决了,然而上面描述的场景是建立在理想情况( 线程有序的执行 ),实际中线程可能是并发( 交替执行 ),也可能是并行,只保证 可见性 仍然会有问题,所以还需要保证 原子性 。
原子性
原子性 是指一个或者多个操作在C P U执行的过程中不被中断的特性,要么执行,要不执行,不能执行到一半,为了直观的了解什么是 原子性 ,看看下面这段代码
int a=0;
a++;
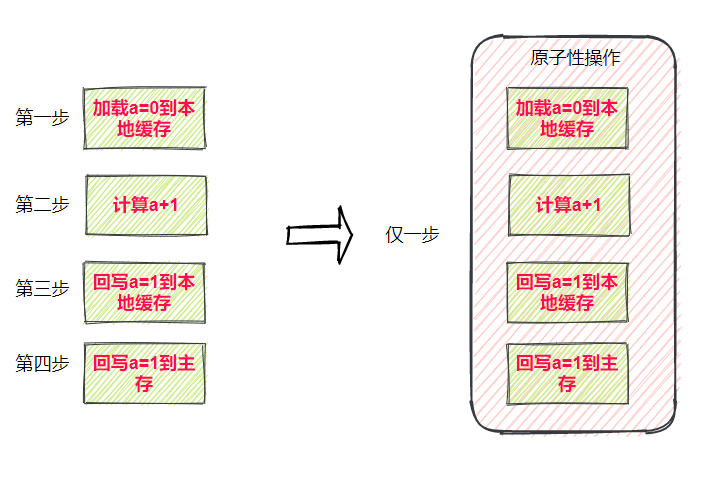
- 原子性操作:int a=0只有一步操作,就是赋值
- 非原子操作:a++有三步操作,读取值、计算、赋值
如果多线程场景进行a++操作,仅保证 可见性 ,没有保证 原子性 ,同样会出现问题。
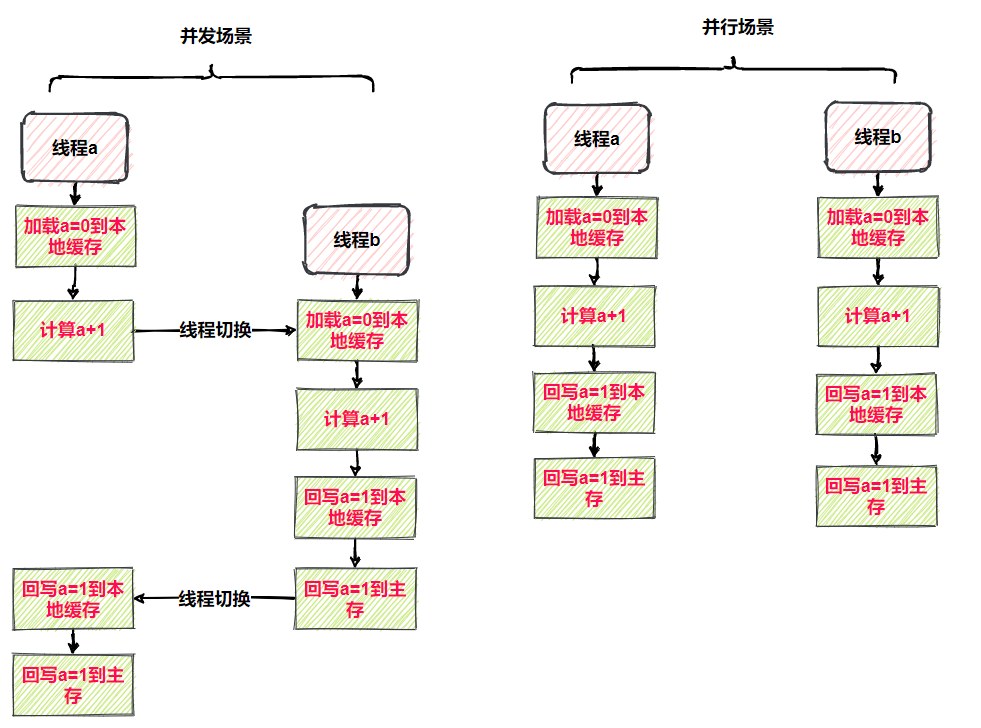
并发场景(线程交替执行)
- 线程A读取变量a到缓存,a是0
- 进行+1运算得到结果1
- 切换到B线程
- B线程执行完整个流程,a=1写入主存
- 线程A恢复执行,把结果a=1写入缓存与主存
- 最终结果错误
并行场(线程同时执行)
- 线程A与线程B同时执行,可能线程A执行运算+1的时候,线程B就已经全部执行完成,也可能两个线程同时计算完,同时写入,不管是那种,结果都是错误的。
为了解决此问题,只要把多个操作变成一步操作,即保证 原子性 。
Java中提供了synchronized( 同时满足有序性、原子性、可见性 )可以保证结果的原子性( 注意这里的描述 ),synchronized保证原子性的原理很简单,因为synchronized可以对代码片段上锁,防止多个线程并发执行同一段代码(本文重点是J M M,所以不会对synchronized做过多的解读)。
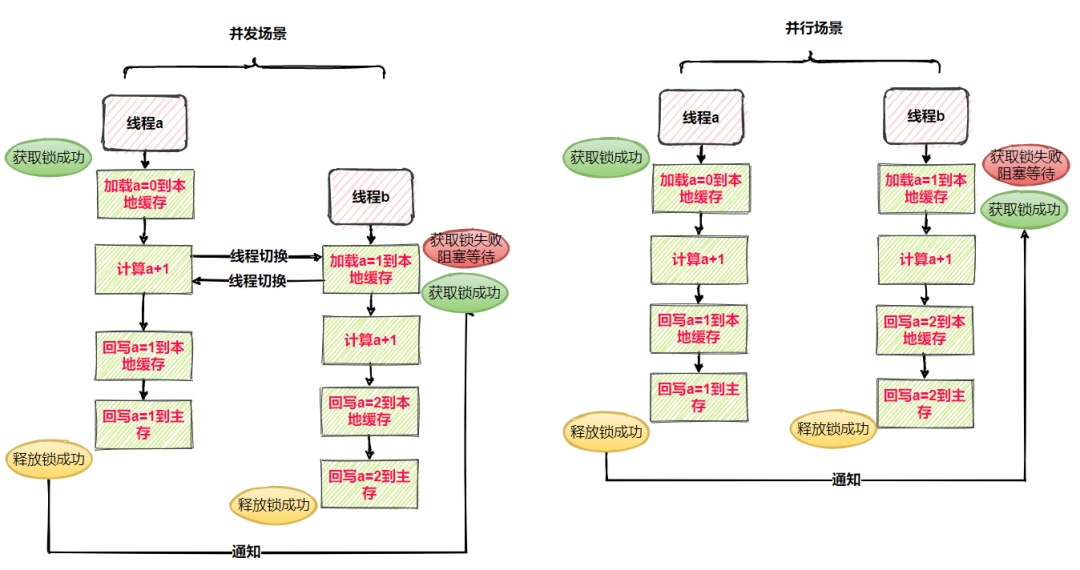
并发场景(线程A与线程B交替执行)
- 线程A获取锁成功
- 线程A读取变量a到缓存,进行+1运算得到结果1
- 此时切换到了B线程
- 线程B获取锁失败,阻塞等待
- 切换回线程A
- 线程A执行完所有流程,主存a=1
- 线程A释放锁成功,通知线程B获取锁
- 线程B获取锁成功,读取变量a到缓存,此时a=1
- 线程B执行完所有流程,主存a=2
- 线程B释放锁成功
并行场景
- 线程A获取锁成功
- 线程B获取锁失败,阻塞等待
- 线程A读取变量a到缓存,进行+1运算得到结果1
- 线程A执行完所有流程,主存a=1
- 线程A释放锁成功,通知线程B获取锁
- 线程B获取锁成功,读取变量a到缓存,此时a=1
- 线程B执行完所有流程,主存a=2
- 线程B释放锁成功
synchronized对共享资源代码段上锁,达到互斥效果,天然的解决了无法保证 原子性、可见性、有序性 带来的问题。
虽然在并行场A线程还是被中断了,切换到了B线程,但它依然需要等待A线程执行完毕,才能继续,所以结果的原子性得到了保证。
有序性
在日常搬砖写代码时,可能大家都以为,程序运行时就是按照编写顺序执行的,但实际上不是这样,编译器和处理器为了优化性能,会对代码做重排,所以语句实际执行的先后顺序与输入的代码顺序可能一致,这就是 指令重排序 。
可能读者们会有疑问“指令重排为什么能优化性能?”,其实C P U会对重排后的指令做并行执行,达到优化性能的效果。
重排序前的指令
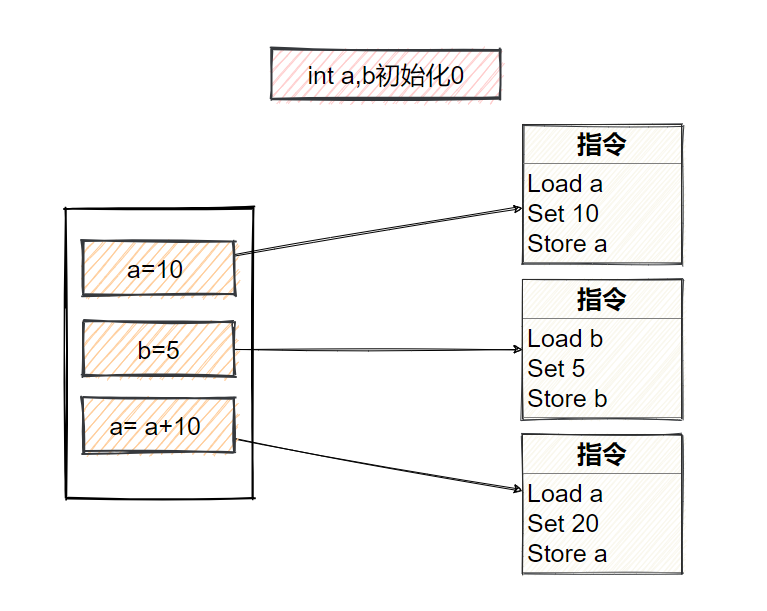
重排序后的指令
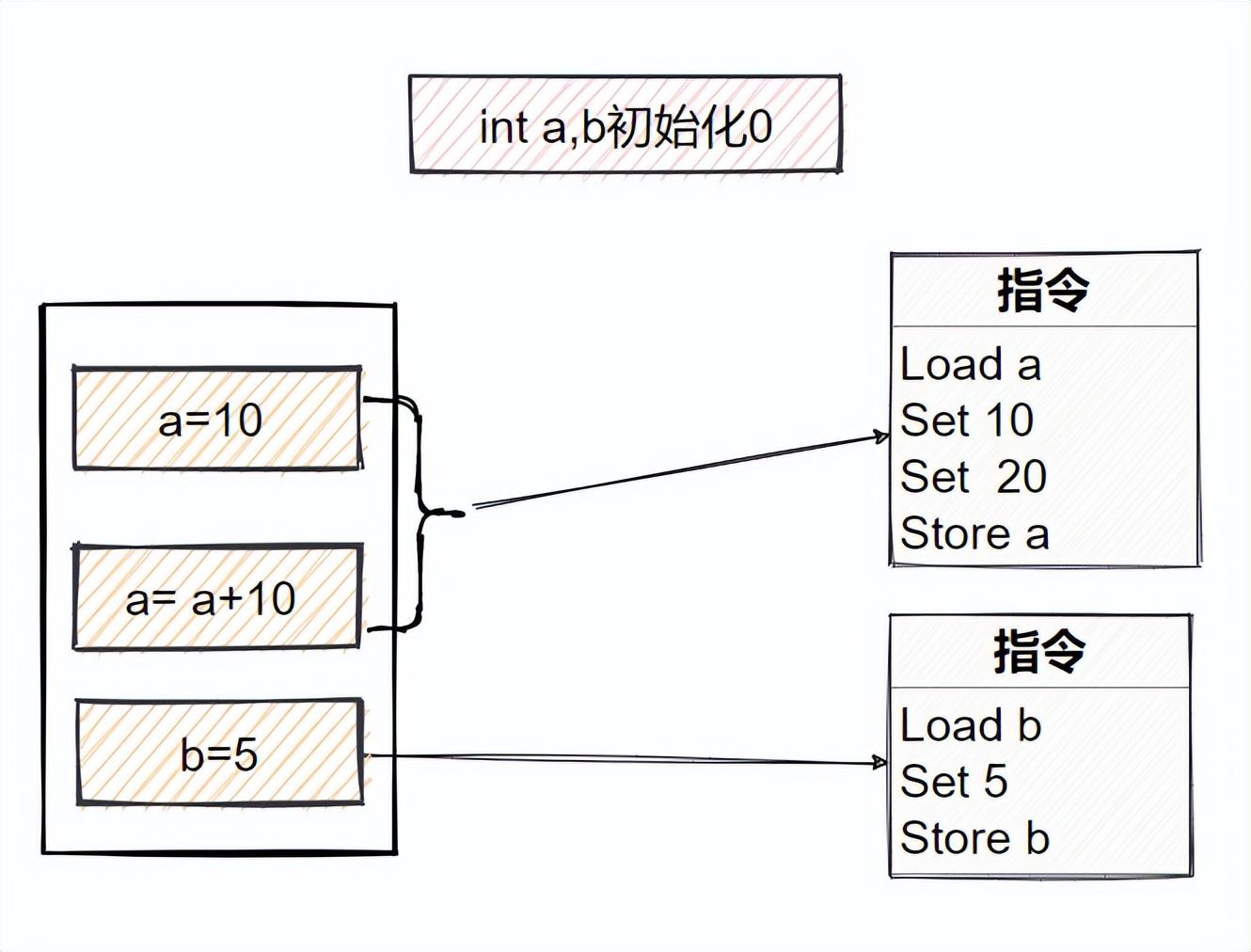
重排序后,对a操作的指令发生了改变,节省了一次Load a和Store a,达到性能优化效果,这就是重排序带来的好处。
重排遵循as-if-serial原则,编译器和处理器不会对 存在数据依赖关系 的操作做重排序,因为这种重排序会改变执行结果( 即不管怎么重排序,单线程程序的执行结果不能被改变 ),下面这种情况,就属于数据依赖。
int i = 10
int j = 10
//这就是数据依赖,int i 与 int j 不能排到 int c下面去
int c = i + j
但也仅仅只是针对单线程,多线程场景可没这种保证,假设A、B两个线程,线程A代码段无数据依赖,线程B依赖线程A的结果,如下图( 假设保证了可见性 )
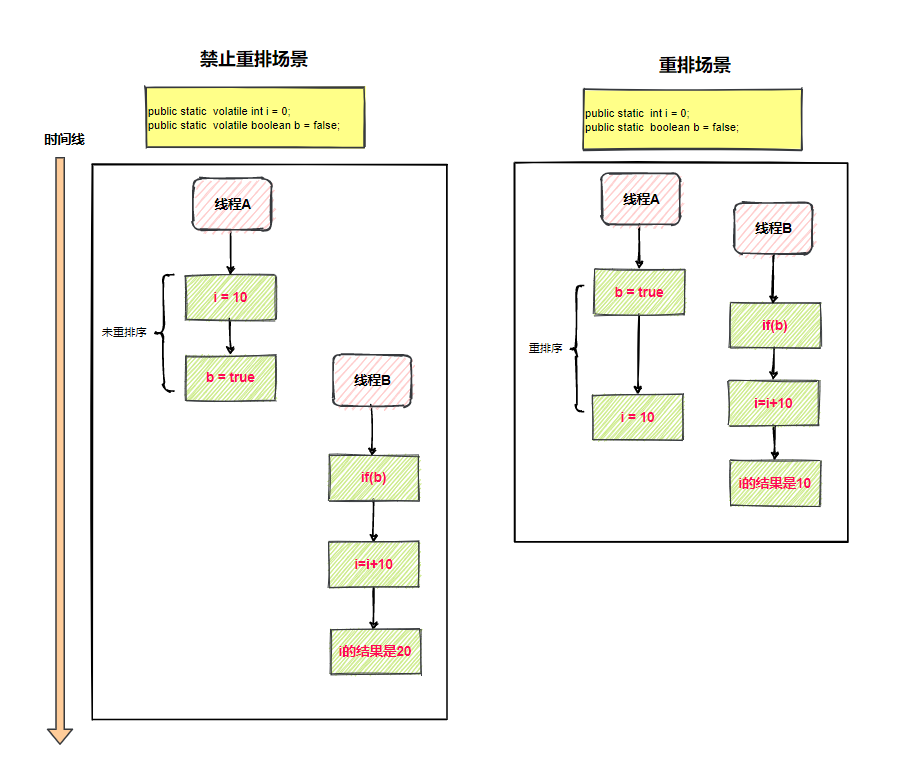
禁止重排场景(i默认0)
- 线程A执行i = 10
- 线程A执行b = true
- 线程B执行if( b )通过验证
- 线程B执行i = i + 10
- 最终结果i是20
重排场景(i默认0)
- 线程A执行b = true
- 线程B执行if( b )通过验证
- 线程B执行i = i + 10
- 线程A执行i = 10
- 最终结果i是10
为解决重排序,使用Java提供的volatile修饰变量同时保证 可见性、有序性 ,被volatile修饰的变量会加上 内存屏障禁止排序 (本文重点是J M M,所以不会对volatile做过多的解读)。
三大特性的保证