本文为《深入学习 JVM 系列》第十六篇文章
我们在前文学习 Java 是如何执行的这篇文章中有提及即时编译器,这是一项用来提升应用程序运行效率的技术。通常而言,代码会先被 Java 虚拟机解释执行,之后反复执行的热点代码则会被即时编译成为机器码,直接运行在底层硬件之上。
那么问题来了,既然在 HotSpot 中即时编译可以提升程序运行效率,为什么还需要解释器呢?
解释器与编译器
首先需要了解的是,并不是所有的 Java 虚拟机都采用解释器与编译器并存的运行架构, 但是主流的 Java 虚拟机,比如说 HotSpot 内部就同时包含解释器和编译器。注意此处的编译器指的是后端编译器,而 Javac 编译器属于前端编译器(前文有详细介绍),下文如无特殊介绍,都指的是后端编译器。
至于为何解释器和编译器共存,是因为两者各有优势。
1、当程序需要迅速启动和执行的时候,解释器可以首先发挥作用,省去编译的时间,立即运行。
2、当程序启动后,随着时间的推移,编译器逐渐发挥作用, 把越来越多的代码编译成本地代码,这样可以减少解释器的中间损耗,获得更高的执行效率。
HotSpot 为了提升程序执行效率而选用即时编译的方法,同时,解释器还可以作为编译器激进优化时后备的“逃生门”。激进优化指的是让编译器根据概率选择一些不能保证所有情况都正确,但大多数时候都能提升运行速度的优化手段。当激进优化的假设不成立,比如加载了新类以后,类型继承结构出现变化、 出现“罕见陷阱”(Uncommon Trap)时可以通过 逆优化 (Deoptimization) 退回到解释状态继续执行。
因此在整个 Java 虚拟机执行架构里,解释器与编译器经常是相辅相成地配合工作,如下图所示:
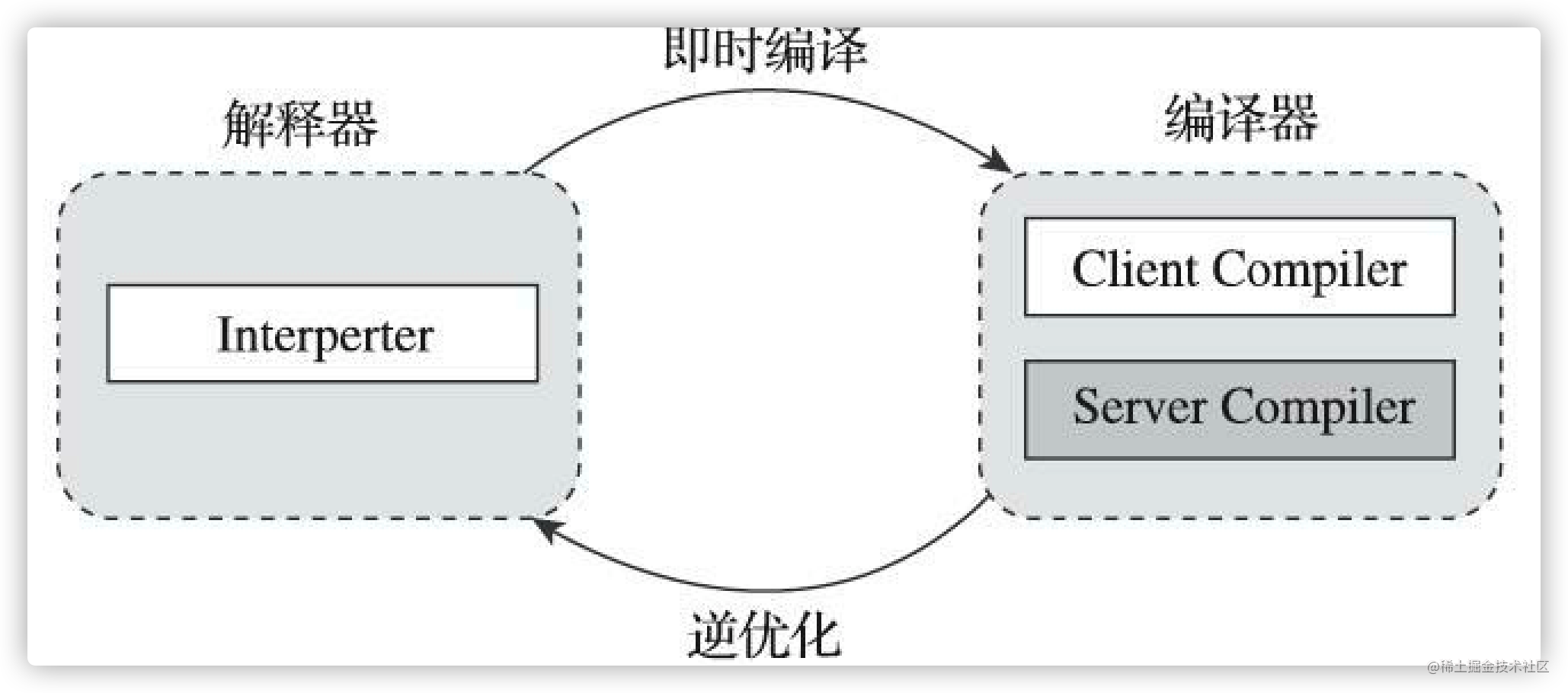
HotSpot 虚拟机中内置了两个用 C++实现的 JIT compiler(即时编译器),分别被称为“客户端编译器”(Client Compiler) 和“服务端编译器”(Server Compiler) , 或者简称为 C1编译器和 C2编译器(部分资料和JDK源码中C2也叫Opto编译器)。上述两种编译器对应两种编译方式,我们简称为 C1编译和 C2编译,用户也可以使用“-client”或“-server”参数去强制指定虚拟机采用 C1编译或是 C2编译。
关于上述两种编译方式,优势各异, C1的编译速度更快,C2的编译质量更高,相较于C1性能通常高 30%以上。
在 JDK10 时引入了 Graal 编译器,用来代替 C2 编译器,目前还在试验阶段。Graal 是一个以 Java 为主要编程语言,面向 Java bytecode的编译器。与用 C++实现的C1及C2相比,它的模块化更加明显,也更加容易维护。Graal既可以作为动态编译器,在运行时编译热点方法;亦可以作为静态编译器,实现 AOT 编译。
Graal 编译器可以通过 Java 虚拟机参数 -XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler 启用。当启用时,它将替换掉HotSpot 中的 C2 编译器,并响应原本由 C2负责的编译请求。
三种编译模式
编译器是二选一,然后再与解释器搭配进行工作,这种方式在 HotSpot 中被称为“混合模式”(Mixed Mode)。 用户也可以使用参数“-Xint”强制虚拟机运行于“解释模式”(Interpreted Mode),全部代码都使用解释方式执行。相应地,用户也可以使用参数“-Xcomp”强制虚拟机运行于“编译模式”(Compiled Mode),这时候将优先采用编译方式执行程序,但是解释器仍然要在编译无法进行的情况下介入执行过程。
我们测试如下一段代码:
public class HotCodeTest {
public static void main(String[] args) {
nlp();
}
public static void nlp() {
int sum = 0;
long start = System.currentTimeMillis();
for (int i = 0; i < 20000000; i++) {
sum += i;
}
long end = System.currentTimeMillis();
System.out.println("cost:" + (end - start) + " ms");
}
}
先使用 javac 编译器获得 class 文件,接着进行下面的步骤。
1、只进行解释执行:-Xint
// JVM参数为:-XX:+PrintCompilation -Xint
//结果:
cost:160 ms
-Xint 参数会强制 JVM 解释执行所有的字节码,没有编译信息,当然这会降低运行速度,通常低10倍或更多。
2、关闭解释器:-Xcomp
// JVM参数为:-XX:+PrintCompilation -Xcomp
//结果:
cost:1 ms
耗时极小,同时打印出了大量的编译信息,其中就包括 nlp方法的编译信息。JVM在第一次使用时会把所有的字节码编译成本地代码,从而带来最大程度的优化。看起来很不错,但正如文章开头所说的那样,如果程序需要迅速执行,则解释器效率更高。比如将上述代码的循环次数为 100,则可以发现解释执行的耗时小于编译执行。
3、混合模式:-Xmixed
// JVM参数为:-XX:+PrintCompilation
//结果:
cost:9 ms
JDK8 之后 HotSpot 默认采用混合模式,即解释执行+JIT。结果打印出了大量的编译信息,其中就包括 nlp方法的编译信息。
综上,也可以正面印证了解释器与编译器共存的必要性。
分层编译
由于即时编译器编译本地代码需要占用程序运行时间,通常要编译出优化程度越高的代码,所花费的时间便会越长;更有甚者,还需要解释器的帮助,解释器可能还要替编译器收集性能监控信息,这对解释执行阶段的速度也有所影响。因此为了在程序启动响应速度与运行效率之间达到最佳平衡,HotSpot 虚拟机在编译子系统中加入了分层编译(tiered compilation)的功能。
分层编译的概念很早就被提出,但是知道 JDK6 才初步实现,JDK7 作为默认编译策略被开启。
分层编译根据编译器编译、优化的规模与耗时,划分出不同的编译层次,其中包括:
level 0、Interpreter 解释执行,并且解释器不开启性能监控功能(Profiling)。
level 1、C1 编译执行,不开启性能监控功能(Profiling)。
level 2、C1 编译执行,开启方法调用次数以及循环回边执行次数等有限的性能监控功能(Profiling)。
level 3、C1 编译执行,开启全部性能监控功能(Profiling)。除了第2层的统计信息外,还会收集如分支跳转、 虚方法调用版本等全部的统计信息。
level 4、C2 编译执行。
这里解释一下,profiling 是指在程序执行过程中,解释器收集能够反映程序执行状态的数据。这里所收集的数据我们称之为程序的 profile。
以上层次并不是固定不变的, 根据不同的运行参数和版本,虚拟机可以调整分层的数量。各层次编译之间的交互、转换关系如下图所示:
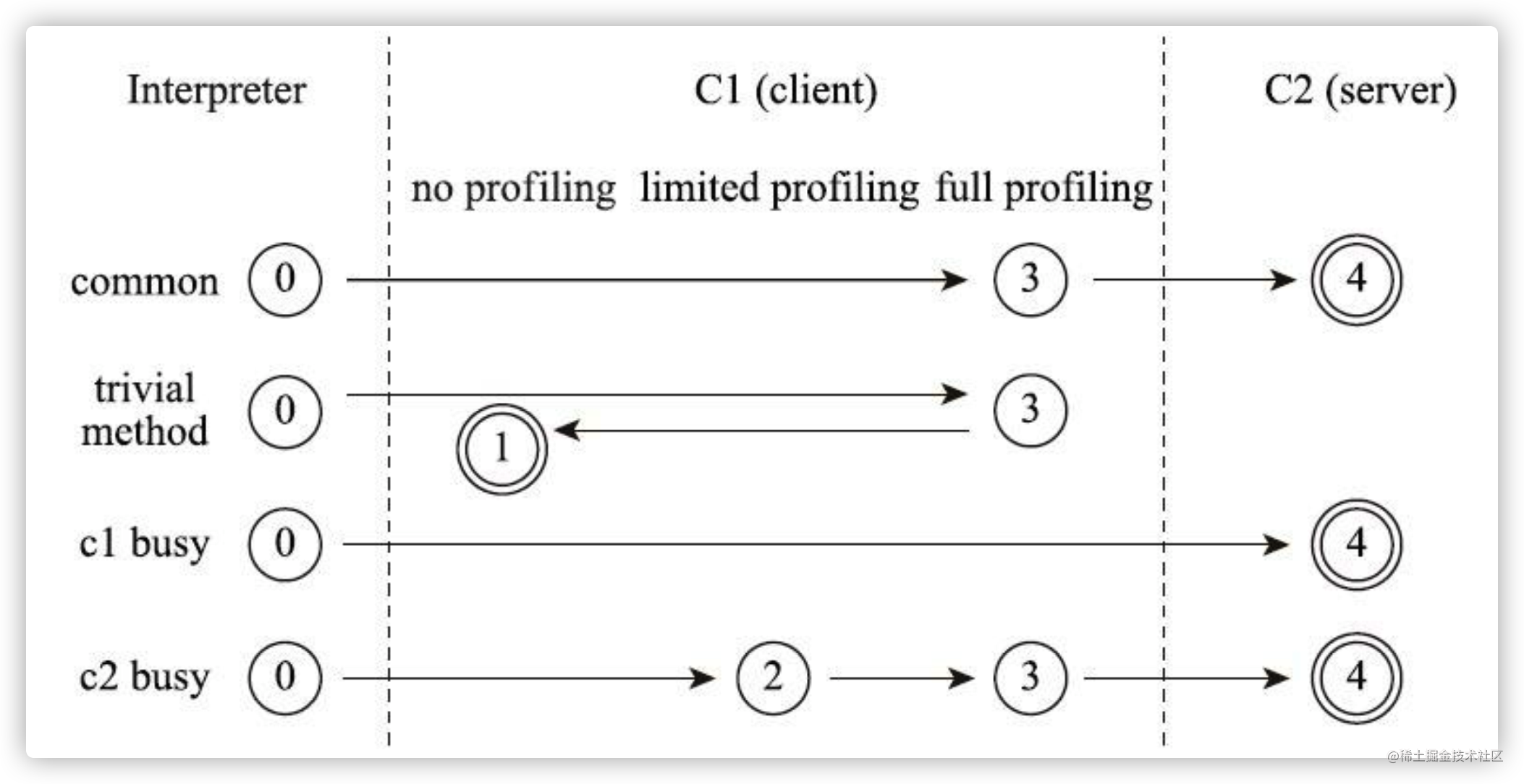
通常情况下,C2 代码的执行效率要比 C1代码的高出30%以上。C1层执行的代码,按执行效率排序从高至低则是1层>2层>3层。在 5 个层次的执行状态中,1 层和 4 层为终止状态。当一个方法被终止状态编译过后,如果编译后的代码并没有失效,那么 Java 虚拟机是不会再次发出该方法的编译请求的。
关于上图介绍的四种编译途径,具体描述为:
- 图中的第一条路径,代表通常情况下,热点方法会被 3 层的 C1 编译,然后再被 4 层的 C2 编译。
- 如果方法的字节码数目比较少(如 getter/setter),而且 3 层的 profiling 没有可收集的数据。那么,Java 虚拟机断定该方法对于 C1 代码和 C2 代码的执行效率相同。在这种情况下,Java 虚拟机会在 3 层编译之后,直接选择用 1 层的 C1 编译。由于这是一个终止状态,因此 Java 虚拟机不会继续用 4 层的 C2 编译。
- 在 C1 忙碌的情况下,Java 虚拟机在解释执行过程中对程序进行 profiling,而后直接由 4 层的 C2 编译。
- 在 C2 忙碌的情况下,基于前文提到 C1中的执行效率是1层>2层>3层,方法会被 2 层的 C1 编译,然后再被 3 层的 C1 编译,以减少方法在 3 层的执行时间。
Java 8 默认开启了分层编译。不管是开启还是关闭分层编译,原本用来选择即时编译器的参数 -client 和 -server 都是无效的。当关闭分层编译的情况下(-XX:-TieredCompilation命令用于关闭分层编译),Java 虚拟机将直接采用 C2。
如果你希望只是用 C1,那么你可以在打开分层编译的情况下使用参数 -XX:TieredStopAtLevel=1。在这种情况下,Java 虚拟机会在解释执行之后直接由 1 层的 C1 进行编译。TieredStopAtLevel =4,则由4层的 C2 进行编译。
即时编译
即时编译建立在程序符合二八定律的假设上,也就是百分之二十的代码占据了百分之八十的计算资源。
对于占据大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成机器码,下次可以重复调用,以达到理想的运行速度。
即时编译的触发
上文可知即时编译器编译的目标是“热点代码”,这里所指的热点代码主要有两类,包括:
- 被多次调用的方法。
- 被多次执行的循环体。
根据“热点代码”的描述,那么到底执行多少次才算是热点代码?还有,虚拟机如何统计一个方法或一段代码被执行过多少次呢?
判断一段代码是不是热点代码,是不是需要触发即时编译,这样的行为称为" 热点探测 ",其实热点探测并不一定要知道方法具体被调用了多少次,目前主要的热点探测判定方式有两种:
- 基于采样的热点探测
- 基于计数器的热点探测
HotSpot 虚拟机中使用的是第二种基于计数器的热点探测方法,它为每个方法准备了两类计数器: 方法调用计数器 和 回边计数器 。在确定虚拟机运行参数的前提下,这两个计数器都有一个确定的阈值,当计数器超过阈值溢出了,就会触发JIT编译。(谁来负责这个事情,还记得分层编译小节中提到的“解释器开启性能监控功能(Profiling)”吗,就是解释器来负责统计计数数据并进行校验)
方法调用计数器
顾名思义,这个计数器就是用于统计方法被调用的次数,它的默认阈值在 Client 模式下是1500次,在 Server 模式下是10000次。这个阈值可以通过参数-XX:CompileThreshold 来人为设定。当一个方法被调用时,会检查方法是否存在被JIT编译过的版本,如果存在,则优先使用编译后的本地代码来执行。如果不存在已被编译过的版本,则将此方法的调用计数器值加1,然后判断方法调用计数器和回边计数器值之和是否超过方法调用计数器的阈值。如果已经超过阈值,那么将会向即时编译器提交一个该方法的代码编译请求。
如果这个参数不做任何设置,那么方法调用计数器统计的并不是方法被调用的绝对次数,而是一个相对的执行频率,即一段时间之内方法被调用的次数。当超过一定的时间限度,如果方法的调用次数仍然不足以让它提交给即时编译器编译,那这个方法的调用计数器就会少一半,这个过程称为方法的调用计数器热度的衰减,而这段时间就称为此方法统计的半衰周期。进行热度衰减的动作是在虚拟机进行垃圾回收时顺便进行的, 可以使用虚拟机参数-XX:-UseCounterDecay 来关闭热度衰减,让方法计数器统计方法调用的绝对次数,这样,只要系统运行时间足够长,绝大部分方法都会被编译成本地代码 。另外,可以使用-XX:CounterHalfLifeTime 参数设置半衰周期的时间,单位是秒。
那如果参数不设置的话,执行引擎并不会同步等待编译请求完成,而是直接进入解释器按照解释方法执行字节码,直到提交的请求被编译器编译完成。当编译工作完成之后,这个方法的调用入口地址就会被系统自动改写成新的,下一次调用该方法时就会使用已编译的版本。
如下代码所示:
// 参数:-XX:+PrintCompilation -XX:-TieredCompilation(关闭分层编译)
private static Random random = new Random();
public static void main(String[] args) {
long sum = 0;
long start = System.nanoTime();
for (int i = 0; i < 12000; i++) {
sum += getRandomNum();
}
long end = System.nanoTime();
System.out.println(end - start);
}
public static int getRandomNum() {
return random.nextInt(10);
}
在输出的编译结果中可以看到 getRandomNum 方法。关闭分层编译后,按照上文描述,编译器默认为 C2编译器,而此时的方法计数器阈值为 10000,虽然方法调用次数并不严格等于方法调用计数器统计的结果,但达到一定次数后,也算是热点代码,最终触发即时编译。
回边计数器
它的作用是统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令称为"回边"(这里的次数指的是回边次数,而不是循环次数,因为并非所有的循环都是回边, 如空循环实际上就可以视为自己跳转到自己的过程,因此并不算作控制流向后跳转,也不会被回边计数器统计)。显然,建立回边技术其统计的目的就是为了触发OSR编译。关于回边计数器的阈值,虽然 HotSpot 也提供了一个类似于方法调用计数器阈值-XX:CompileThreshold 的参数-XX:BackEdgeThreshold 供用户设置,但是当前虚拟机实际上并未使用此参数,因此我们需要设置另外一个参数-XX:OnStackReplacePercentage 来间接调整回边计数器的阈值,其计算公式如下:
(1)Client模式
方法调用计数器阈值 × OSR比率 / 1000,其中OSR比率默认值933,如果都取默认值,Client模式下回边计数器的阈值应该是13995。
(2)Server模式
方法调用计数器阈值 × (OSR比率 - 解释器监控比率) / 100,其中OSR比率默认140,解释器监控比率默认33,如果都取默认值,Server模式下回边计数器阈值应该是10700。
当解释器遇到一条回边指令时,会先查找将要执行的代码片段中是否有已经编译好的版本,如果有,它将会优先执行已编译好的代码,否则就把回边计时器的值加1,然后判断方法调用计数器与回边计数器值之和是否已经超过回边计数器的阈值。当超过阈值之后,将会提交一个OSR编译请求,并且把回边计数器的值降低一些,以便继续在解释器中执行循环,等待编译器输出编译结果。
与方法计数器不同,回边计数器没有热度衰减的过程,因此这个计数器统计的就是该方法循环执行的绝对次数。当计数器溢出的时候,它还会把方法计数器的值也调整到溢出状态,这样下次再进入该方法的时候就会执行标准编译过程。
比如下面这段代码:
// 参数:-XX:+PrintCompilation -XX:-TieredCompilation(关闭分层编译)
private static Random random = new Random();
public static void main(String[] args) {
nlp();
}
public static void nlp() {
long sum = 0;
for (int i = 0; i < 18000; i++) {
sum += random.nextInt(10);
}
}
上述代码的编译结果仍然有 nlp 方法,可见触发了即时编译。顺便来看一下 nlp 方法的字节码内容。
public static void nlp();
descriptor: ()V
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=4, locals=3, args_size=0
0: lconst_0
1: lstore_0
2: iconst_0
3: istore_2
4: iload_2
5: sipush 18000
8: if_icmpge 29
11: lload_0
12: getstatic #3 // Field random:Ljava/util/Random;
15: bipush 10
17: invokevirtual #4 // Method java/util/Random.nextInt:(I)I
20: i2l
21: ladd
22: lstore_0
23: iinc 2, 1
26: goto 4
29: return
可以看到,偏移量为26的字节码将往回跳至偏移量为4的字节码中,则偏移量为 26的指令即为回边指令。解释器遇到该指令时,会先查找将要执行的代码片段中是否有已经编译好的版本,如果没有,则回边计数器加1,直到满足回边计数器的阈值。
小结
针对上述两种计数器,我们得到如下结论:
- 每个方法都有两种计数器:方法调用计数器和回边计数器,每个计数器的阈值不同。
- 方法调用计数器阈值 1500;回边计数器阈值 13995,当计数超过阈值时,则会触发C1编译。
- 方法调用计数器阈值 10000;回边计数器阈值 10700,达到阈值则触发 C2 编译。
另外需要注意的时,与阈值比较的都是 方法调用计数器和回边计数器值之和 ,因为多次被调用的某个方法里可能有一个循环体。比如下面这段代码:
//-XX:+PrintCompilation
private static Random random = new Random();
public static void main(String[] args) {
long sum = 0;
long start = System.nanoTime();
for (int i = 0; i < 6000; i++) {
sum += getRandomNum();
}
long end = System.nanoTime();
System.out.println(end - start);
}
public static int getRandomNum() {
return random.nextInt(10);
}
根据输出结果可知触发了 C1和 C2 编译,虽然循环次数只有 6000 次,但是却能触发 C2 编译,因为两种计数器都在计数,最后累加的和超过阈值即可触发即时编译。
明显可以看出来方法调用计数器的阈值小一些,那么一般情况下只要满足了方法调用计数器的阈值就可以触发编译,为什么还要设置回边计数器的阈值,原因就在于 OSR。OSR 的触发条件更高一些罢了。
OSR
可以看到,决定一个方法是否为热点代码的因素有两个:方法的调用次数、回边的执行次数。即时编译便是根据这两个计数器的和来触发的。为什么 Java 虚拟机需要维护两个不同的计数器呢?
对于这两种情况,编译的目标对象都是整个方法体,而不会是单独的循环体。第一种情况,由于是依靠方法调用触发的编译,那编译器理所当然地会以整个方法作为编译对象,这种编译也是虚拟机中标准的即时编译方式。
而对于后一种情况, 尽管编译动作是由循环体所触发的,热点只是方法的一部分,但编译器依然必须以整个方法作为编译对象,只是执行入口(从方法第几条字节码指令开始执行) 会稍有不同,编译时会传入执行入口点字节码序号(Byte Code Index, BCI)(这点在上文回边计数器一节有解读过相应的字节码文件)。这种编译方式因为编译发生在方法执行的过程中,因此被很形象地称为“栈上替换”(On Stack Replacement, OSR),即方法的栈帧还在栈上, 方法就被替换了。
在不启用分层编译的情况下,触发 OSR 编译的阈值是由参数 -XX:CompileThreshold 指定的阈值的倍数。默认情况下,C1 的 OSR 编译的阈值为 13500,而 C2 的为 10700。
在启用分层编译的情况下,触发 OSR 编译的阈值则是由参数 -XX:TierXBackEdgeThreshold 指定的阈值乘以系数。
Codecache
通过上文的学习,我们也都知道 JVM 在运行时会将热点代码编译为本地机器码,以提高执行效率。那么这些机器码存在什么位置呢?接下来将引入一个术语——Codecache,用来存放本地机器码的内存区域了,它存在于堆外内存。一般情况下我们都接触不到这块区域,可能偶尔遇到线上服务器宕机了,在日志里面看到 java.lang.OutOfMemoryError code cache,就是这块内存发生的问题。
配置
Codecache 内存大小配置:
InitialCodeCacheSize = 2555904 //默认大小
ReservedCodeCacheSize = 251658240 //内存最大值
CodeCacheExpansionSize =65536 //CodeCache每次扩展大小
CodeCache输出参数的相关参数:
-XX:+PrintCodeCache # 在JVM停止的时候打印出codeCache的使用情况,其中max_used就是在整个运行过程中codeCache的最大使用量
-XX:+PrintCodeCacheOnCompilation # 用于在方法每次被编译时输出CodeCache的使用情况
查看 CodeCache 使用情况,执行如下命令:
-XX:+PrintCodeCache
//结果如下:
CodeCache: size=245760Kb used=1123Kb max_used=1132Kb free=244636Kb
bounds [0x0000000118979000, 0x0000000118be9000, 0x0000000127979000]
total_blobs=285 nmethods=33 adapters=166
compilation: enabled
如果想要修改 Codecache 内存最大值,可以这样设置:
-XX:ReservedCodeCacheSize=2496K -XX:+PrintCodeCache
//输出结果:
CodeCache: size=2496Kb used=1109Kb max_used=1120Kb free=1386Kb
bounds [0x000000010ae06000, 0x000000010b076000, 0x000000010b076000]
total_blobs=274 nmethods=28 adapters=160
compilation: enabled
Codecache 刷新选项
- UseCodeCacheFlushing,默认为 true,是否在关闭JIT编译前清除 CodeCache。
CodeCache编译限制相关参数:
-XX:MaxInlineLevel # 针对嵌套调用的最大内联深度,默认为9
-XX:MaxInlineSize # 方法可以被内联的最大bytecode大小,默认为35
-XX:MinInliningThreshold # 方法可以被内联的最小调用次数,默认为250
-XX:+InlineSynchronizedMethods # 是否允许内联synchronized methods,默认为true
Codecache 满了会怎么样
Codecache 占用的内存有固定大小,JVM 将不会编译任何额外的代码,因为 JIT 编译器现在已关闭。此外,我们会收到*“CodeCache is full... The compiler has been disabled* ”的警告信息。JIT 编译器被停止了,并且不会被重新启动,此时会回归到解释执行,被编译过的代码仍然以编译方式执行,但是尚未被编译的代码就只能以解释方式执行了。
增加 ReservedCodeCacheSize 可能是一种解决方案,但这通常只是一种临时解决方法。
如果程序无法走编译执行,那么就会影响到程序的执行效率。JVM 提供了一个 UseCodeCacheFlushing 选项来控制代码缓存区域的刷新,该项配置默认为 true,会在满足以下条件时释放占用的区域:
- code cache用满; 如果该区域的大小超过某个阈值,则会清除 Codecache。
- 自上次清理后经过了一定的时间间隔。
- 预编译的代码不够热。 对于每个JIT编译的方法,JVM都会有一个热度跟踪计数器。 如果计数器的值小于动态阈值,则JVM会释放这段预编译的代码。
知道了何时会清除 Codecache,那么 JVM 接下来如何做?
-XX:+PrintCompilation 命令用来输出程序编译信息,其中输出内容中包括这样两个标识:made non entrant 和 made zombie。
made not entrant 表示被编译的方法不能再被进入,即无法再复用 Codecache 中的机器码,同时 JVM 会借助**去优化(Deoptimization)**机制,从执行即时编译器生成的机器码切换回解释执行,关于去优化,后续章节会详细介绍。
当满足 Codecache 的清除条件时, Java 虚拟机检测到所有的线程都退出该编译后的“made not entrant”时,会将该方法标记为“made zombie”,此时可以回收这块代码所占据的空间了。
扩展
PrintCompilation 参数
-XX:+PrintCompilation
PrintCompilation 将会输出被编译方法的统计信息,因此使用 PrintCompilation 可以很方便的看出哪些是热点代码。热点代码也就意味着存在着被优化的可能性。默认情况下,禁用此选项并且不打印诊断输出。
//添加参数-XX:+PrintCompilation
public static void main(String[] args) {
long start = System.nanoTime();
for (int i = 0; i < 200; i++) {
nlp();
}
long end = System.nanoTime();
System.out.println(end - start);
}
public static void nlp() {
int sum = 0;
for (int i = 0; i < 2000; i++) {
sum += i;
}
}
截取部分日志输出为:
185 24 4 sun.nio.cs.UTF_8$Encoder::encode (359 bytes)
185 26 3 java.lang.StringBuilder::append (8 bytes)
185 27 1 java.net.URL::getAuthority (5 bytes)
186 28 3 java.lang.String::isEmpty (14 bytes)
187 29 % 3 HotCodeTest::nlp @ 4 (22 bytes)
187 30 3 HotCodeTest::nlp (22 bytes)
187 31 % 4 HotCodeTest::nlp @ 4 (22 bytes)
187 33 3 java.lang.System::getSecurityManager (4 bytes)
187 32 3 java.lang.StringBuilder::toString (17 bytes)
187 29 % 3 HotCodeTest::nlp @ -2 (22 bytes) made not entrant
187 34 4 HotCodeTest::nlp (22 bytes)
188 35 3 java.util.Arrays::copyOfRange (63 bytes)
188 30 3 HotCodeTest::nlp (22 bytes) made not entrant
188 36 4 java.lang.String::hashCode (55 bytes)
简要介绍一下日志含义:
- 第一列:方法开始编译时的时间(毫秒)
- 第二列:Java 虚拟机维护的编译 ID
- 第三列:一些 flag 标识
b Blocking compiler (always set for client) //阻塞应用线程
* Generating a native wrapper
% On stack replacement (where the compiled code is running) //由回边计数器触发的栈上替换编译
! Method has exception handlers //包含异常处理器的方法
s Method declared as synchronized //同步方法
n Method declared as native //本地方法
made non entrant compilation was wrong/incomplete, no future callers will use this version //表示方法不能再被进入
made zombie code is not in use and ready for GC //表示这块代码可以被回收空间了
- 第四列:编译的层次,0-4层,对应分层编译章节中的那张图片
- 第五列:编译的方法名
CITime参数
-XX:+CITime
打印消耗在JIT编译的时间