哪有什么岁月静好,只是有人在默默负重前行
1. Spring的复杂
如果你是一个Javaer,那么你一定使用过Spring。我们一边在感叹Spring的无比强大,然而一边在叹息Spring强大的外表下隐藏着那如迷失森林搬的迷宫式的复杂。

这还不是最令人绝望的,最为绝望的是当你想看本书或者看篇博客来试图了解Spring为啥这么强大的时候,往往一开始都是这样的画风
或者是这样的画风
然后你就强忍着睡意,眼神迷离地看完了(或者将翻完了)那本 <<Spring xxx内功秘籍>> ,然后假装自己已经练会了Spring的内功。。。

2. 俯视Spring
当然我不是说不需要深入到Spring的源代码,而是说你不要一上来就整这些感觉很高大上然后又让人看得很懵逼的图。
那应该咋整呢? 答:你得循序渐进,从大到小,一步一步慢慢深入,我把这种学习方式叫做
剥洋葱式学习,或者粗俗点来讲叫做扒衣式学习
下面我们就来看一下Spring的全貌:
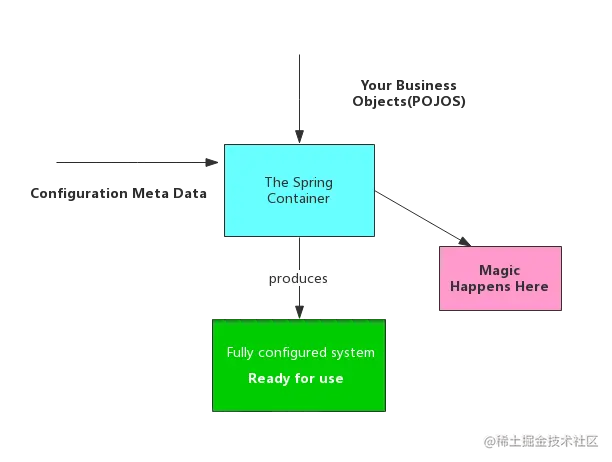
没错,这是Spring-framwork官网上有且仅有的一张描述Spring的图。
是不是感觉很清爽,很舒服,其实这才是我们学习Spring应该要有的姿势:别废话,有图有真相。
从这张图中我们看到普通用户只要准备两样东西就可以使用我们的Spring了
- Pojo
- 配置信息
这也是我们大多数开发者眼中的Spring----强大的Spring,万能的Spring。所有一切Spring的黑魔法都被隐藏在了Spring容器中。
3.剖析Spring
下面我们就来一层层趴开Spring华丽的外衣,来瞅瞅Spring的黑魔法到底是如何生效的 ##Spring的外衣 上面我们远远地俯视了一下Spring,看了个大概,下面我们就再扒一层Spring的衣服来稍微深入瞅一下Spring。
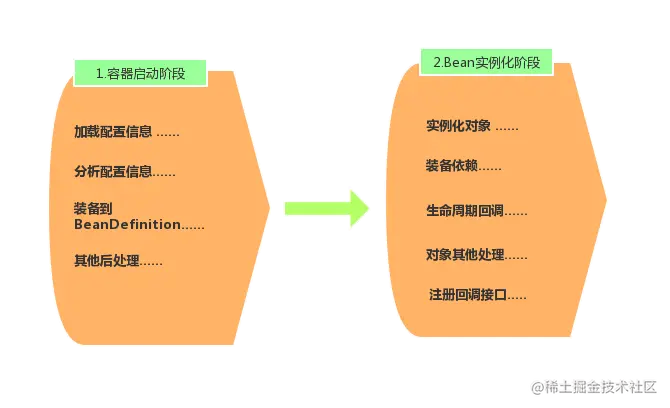 所有的黑魔法,其实不管它有怎么华丽的展现方式,其内部的实现步骤其实也是一步一步来的。如上图,其实Spring的启动过程分为两个阶段:
所有的黑魔法,其实不管它有怎么华丽的展现方式,其内部的实现步骤其实也是一步一步来的。如上图,其实Spring的启动过程分为两个阶段:
- 容器启动阶段(为了得到
BeanDefinition) Bean实例化阶段(为了得到装配好的Bean)
BeanDefinition( 非常非常重要 )插播(插播内容都可以先不看)
BeanDefinition到底是个啥?对比来看,这个就有点像是Class之于Object,是用来描述Bean的元数据的。比如(Bean是否是单例的,是否需要延迟加载,初始化方法名称是啥,依赖哪些Bean)。
- 有人可能会问Spring为啥不直接使用Class对象来生产Bean呢?
有人可能会说单纯使用Class的话,没法完整的描述Spring中的所有概念:比如没法描述Bean的依赖关系,没法调用Bean的初始化方法。在我个人看来,这个论述不完全对。因为其实依赖关系我们是可以通过从Class中的
Field,Method,Constructor中的注解(@Autowired@Resource)来获取到的,当然初始化方法的注解(@PostConstruct等)也可以获取到,所以就这两点来看单纯使用Class对象是可以描述Bean的。但是有3点Class对象是做不到或则会很难做好的。
- Spring早期(XML时代)是没有注解的,Bean的依赖关系只能通过XML的配置来描述
BeanDefinition是一个中间产物,Spring是允许自己活着开发者来修改这个中间产物的,而Class是无法修改的- 在注解时代,如果单纯使用Class中的注解来描述一切Bean的元数据的话,Spring需要大量的反射操作才能拿到这些元数据,这样不仅性能低下而且非常繁琐
- 总的来说,你让Class来描述Bean的话,Class估计只能说:臣妾办不到啊!!!
如果你觉得这个过程有点突兀,或者有点懵逼,下面我们来打个比方:

这就好像你去饭店吃饭一样,你只要坐那等上十几分钟然后你就可以享受到美味。然而只要你真正地在家自己做过一顿饭,你就知道这个过程是多么漫长和繁杂。但是这一切饭店的后厨都帮你搞定了,你要做的就是享受美味。但是漫长繁杂的过程在厨师看来无非就是两步:
- 准备材料(为了得到已经洗好,处理好的的菜的原材料)
- 做菜(为了得到直接可以吃的菜)
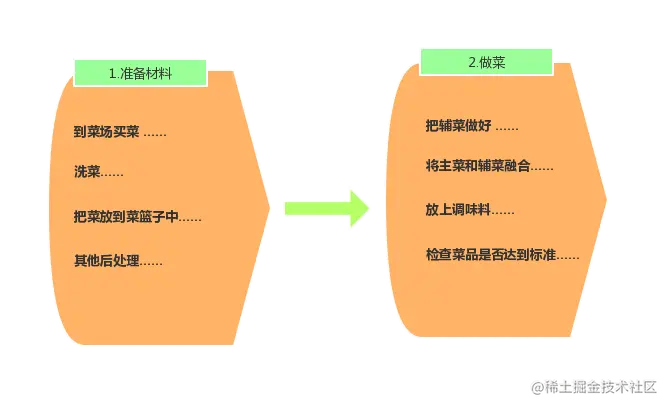
如果你还是不理解这个比喻的话,也没关系,你只需要记得,Spring容器加载在整体上分为两个部分:
- 1.器启动阶段(为了得到BeanDefinition)
- 2.Bean实例化阶段(为了得到装配好的Bean) 大体记得就行,至于每一部分里面具体都干了些啥事,请继续往下看
4.Spring的秋衣,秋裤
上面我们看到了Spring的华丽的外衣(两阶段),下面我们继续,趴开外皮,看一下Spring的秋衣,秋裤,看一下这个两阶段里面到底藏了些啥。
老规矩,先上图
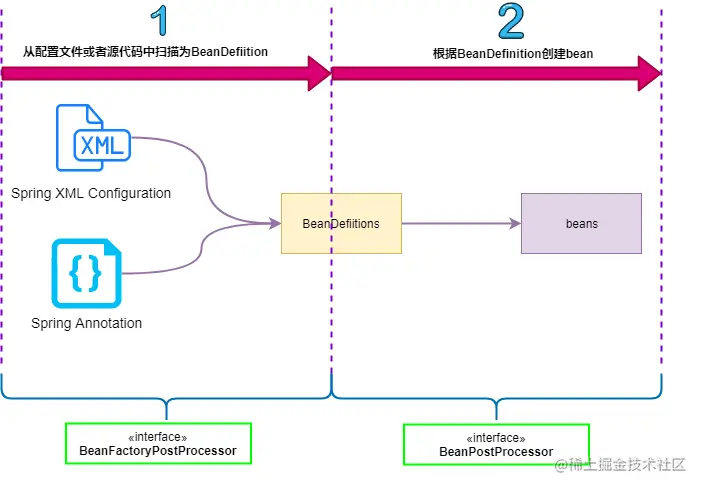 从上图中我们可以看到
从上图中我们可以看到
- 第一阶段(容器启动阶段)主要使用了
BeanFactoryPostProcessor来从XML配置文件或者Java代码中扫描得到生产Bean的原材料:BeanDefinition - 第二阶段(Bean实例化阶段)主要使用了第一步得到的
BeanDefinition以及BeanPostProcessor来生产Bean
OK,至此为止,我们知道了实际干活的就是这两个角色
BeanFactoryPostProcessor(有些中文翻译为:Bean工厂后置处理器)BeanPostProcessor(有些中文翻译为:Bean后置处理器)
那这两位到底是哪路神仙呢?
BeanFactoryPostProcessor( 非常非常重要 )
BeanFactoryPostProcessor在Spring中是一个接口,然后它还有一个非常重要的子接BeanDefinitionRegistryPostProcessor。简单理解其作用:BeanFactoryPostProcessor允许框架或者开发者来 修改 BeanDefinition,而BeanDefinitionRegistryPostProcessor允许框架或者开发者来向容器中动态 添加 更多的BeanDefinition。不理解的话,我们打个比方:BeanFactoryPostProcessor 的作用就相当于菜洗好了之后,你还可以再切成段或者切成片再或者加一点胡椒粉,也就是你可以 修改 原材料的形态。BeanDefinitionRegistryPostProcessor的作用就像是菜洗好了放在菜篮子后,你自己还可以再 添加 自己喜欢的原材料,比如再加点生羊肉,牛肉等。
####BeanPostProcessor( 非常非常重要 ) BeanPostProcessor是一个接口簇,总共有 5个 ,这里我就先不一一列举出来了,但是你得知道我们上图中所画的BeanPostProcessor不仅仅指BeanPostProcessor本身,还代指其下的所有子接口。但是这些接口其实都是用来生产装配好的Bean的。BeanPostProcessor本身的主要作用是在Bean的 初始化前后 来定制自己的逻辑,所以你翻开源代码的时候是看到两个方法,一个是初始化之前调用,一个初始化之后调用。在这里我们暂时不讨论啥叫初始化,后面我们会聊。那不理解的话,我们也打个比方,在鱼出锅之前你是不是可以放点酱油好提鲜上色,出锅后你是不是可以再放点香菜提香。 ###总结( 非常非常重要 ): 上图中的BeanFactoryPostProcessor以及BeanPostProcessor都不仅仅指它两本身,而代指的是接口簇。BeanFactoryPostProcessor干预的是Bean的原材料BeanDefinition的生产过程,而BeanPostProcessor干预的是Bean的生产过程
5.Spring的内衣
上面我们已经趴开了Spring的外套和秋衣,秋裤了,下面我们就要羞羞了,嘿嘿,来瞅一下Spring的内衣。
注意,前方高能,下面要看一点源代码了。当然我们看源代码的目的不是去看细节,而是来证明我们的理解是对的,然后再在看完源代码后得出一些结论。 如果你懒得看源代码,那么你就忽略然后直接看结论吧,一点也不影响你的理解 。
下面的Spring源代码的是基于5.1.9-RELEASE版本,而且只讲基于注解的Spring加载流程
稍微看过Spring的源代码的同学都知道,Spring最为核心的方法就是那个AbstractApplicationContext#refresh()方法。
该方法定义了抽象了Spring容器加载的整个流程。只不过有些方法是空实现,是留给子类Override的。你要是学习过设计模式,其实这就是 模板模式 。其实Spring源代码中有很多模式,我们碰到了就提一下,没碰到就算了
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
prepareRefresh();
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
prepareBeanFactory(beanFactory);
try {
postProcessBeanFactory(beanFactory);
// 第一阶段(容器准备阶段):从上面第一个方法到这个方法为止都算是第一阶段
// 但是最为重要的流程主要就是这个方法
invokeBeanFactoryPostProcessors(beanFactory);
// 过度阶段:注册BeanPostProcessor(包含其所有的子接口)
registerBeanPostProcessors(beanFactory);
// 下面的四个方法先忽略:非IOC容器的主要流程
initMessageSource();
initApplicationEventMulticaster();
onRefresh();
registerListeners();
// 第二阶段(Bean实例化阶段):实例化生效的非延迟加载的Bean
finishBeanFactoryInitialization(beanFactory);
finishRefresh();
}
catch (BeansException ex) {
// 忽略,非主流程
destroyBeans();
cancelRefresh(ex);
throw ex;
}
finally {
resetCommonCaches();// 忽略,非主流程
}
}
}
看不懂?不要紧,你只要大概读一读注释就可以了,主要是为了验证我们之前的Spring的二阶段流程在源代码中的体现。下面我们就尽量通过画图的方式来深入了解一下Spring。
###第一阶段(容器启动阶段)剖析 第一阶段的精华都在这方法里面了,具体的代码这里就不贴了,大家有兴趣可以自己翻看源代码。
AbstractApplicationContext.invokeBeanFactoryPostProcessors(beanFactory);
再升入一层,发现这个过程被委托给了PostProcessorRegistrationDelegate
PostProcessorRegistrationDelegate#
public static void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {
这里要注意一下,正常情况下参数beanFactoryPostProcessors都是空的,因为这个参数只有在开发者手动调用addBeanFactoryPostProcessor这个方法才会有值。而正常我们在使用Spring的时候是不会手动调用这个方法的。
- 这里其实有一个问题:如果有多个
BeanFactoryPostProcessor或者BeanDefinitionRegistryPostProcessor的话,那么谁先被调用谁又后被调用呢? 在内部Spring把对象主要分为3类:
- 实现了
PriorityOrdered(优先级最高)接口的Bean- 实现了
Ordered(一般优先级)接口的Bean- 都没有实现
PriorityOrdered和Ordered的普通Bean(优先级最低)然后在同级别(如都实现了PriorityOrdered的Bean)的Bean中通过实现getOrder()方法来区分谁先谁后
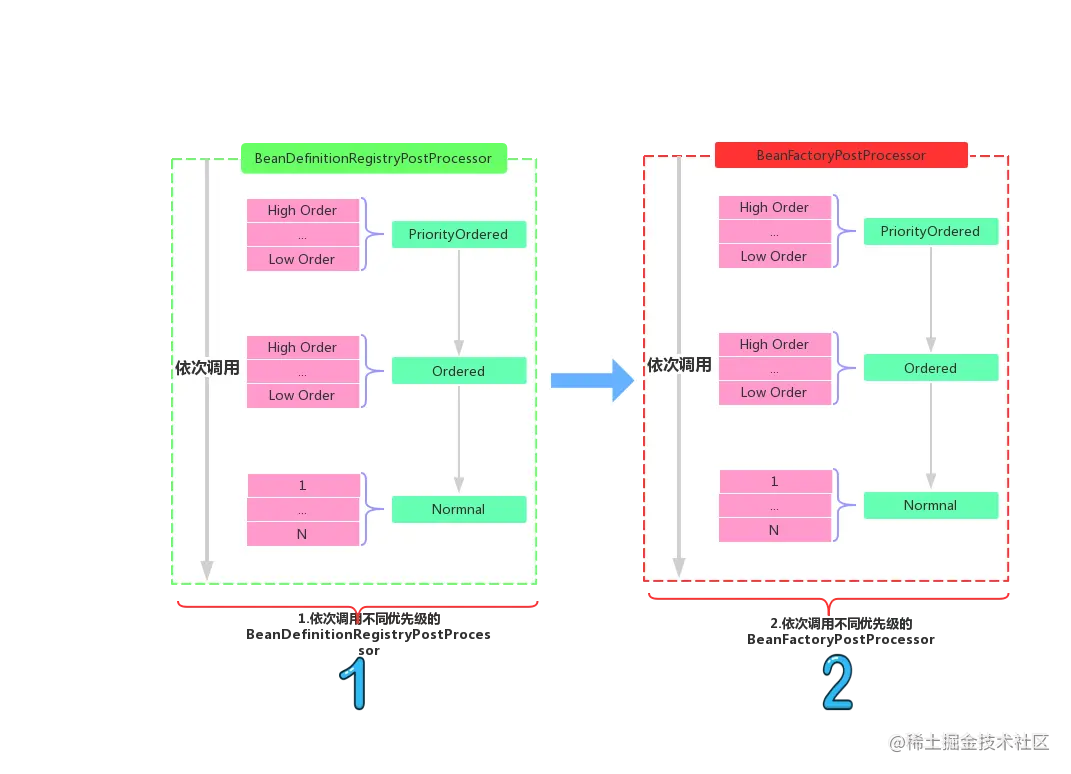
如上图就是整个第一阶段(容器启动阶段)最为核心的一段流程了。 你可能会说,这尼玛也太简单了吧,你是不是在误导我?其实,Spring的主流程就是这么简单,但是Spring之所以这么复杂是因为,在这个过程中Spring加入了它自己实现的BeanDefinitionRegistryPostProcessor以及BeanFactoryPostProcessor。如果你看过Spring的实现,你就知道Spring就是一头隐藏的很深的恶魔。 ####BeanDefinitionRegistryPostProcessor
BeanDefinitionRegistryPostProcessor在容器准备阶段的主要作用就是注册所有需要加载到容器中的Bean的元数据
BeanDefinition。
下面我们就简单介绍一个Spring注解驱动模式下的一个 开天辟地 的BeanDefinitionRegistryPostProcessor接口的实现类--- ConfigurationClassPostProcessor ,这个类是Spring-framwork中 唯一 实现了BeanDefinitionRegistryPostProcessor接口的类

如果非要我形容一下**
ConfigurationClassPostProcessor的重要性的话,那么只能使用女娲娘娘来形容了。对的,ConfigurationClassPostProcessor**之于开发者的Pojo业务类,就想女娲娘娘之于人类。
上帝说,世上还没有人类,于是女娲娘娘来了。Spring说,容器中还没有Bean,于是**
ConfigurationClassPostProcessor**来了。
那这个类**ConfigurationClassPostProcessor 主要是干嘛的呢? 我们来看一下 ConfigurationClassPostProcessor**的文档:
BeanFactoryPostProcessor used for bootstrapping processing of @Configuration classes.
说白点就是处理所有的配置类
其内部的实现,今天就不在这里讨论了。你主要记住它很重要很重要,其作用就是处理配置类。
到这里,你是不是有点迷糊了,我感觉Spring只需要一个**ConfigurationClassPostProcessor**就够了啊,为啥还要搞那么复杂,又是PriorityOrdered又是Ordered的,整这些有啥用呢? 实际上,这里不得不提一下Spring所遵循的设计原则:
开闭原则:对修改关闭,对扩展开放
Spring之所以搞这么复杂,主要是为了方便Spring框架自己以及开发者来扩展Spring。比如Spring不仅仅可以支持注解来配置,还可以支持XML方式,那么Spring是不是可以实现一个BeanDefinitionRegistryPostProcessor来处理XML方式呢?(当然到了Spring4.x的时候,这个功能已经被@ImportResource注解来代替了)。那除了Spring自己可以实现,开发者是不是也可以实现一个 BeanDefinitionRegistryPostProcessor来扩展Spring呢?
不明白吗?那我打个比方:厨师把鱼洗好,切好,处理好之后放到了菜篮子里面了。但是这时候你说你想吃个鸡腿怎么办呢?那简单,只要你自己去菜场买个鸡腿,然后自己洗好,处理好之后也放到菜篮子里面就可以了,这时候厨师就不仅可以把鱼做好,而且可以给你做好鸡腿。

PS:是不是已经留哈喇子了
####BeanFactoryPostProcessor 说完了鸡腿,啊,不,说完了BeanDefinitionRegistryPostProcessor之后,我们来聊一下BeanFactoryPostProcessor
BeanFactoryPostProcessor的主要作用就是来通过 修改 容器中已经存在的BeanDefinition来插手Bean的产生过程。说白点,就是来搞事情的。
所以,你现在是不是可以理解上面那个图中为啥先处理BeanDefinitionRegistryPostProcessor然后再处理BeanFactoryPostProcessor了吧?得先有BeanDefinition才能修改啊,还有一个原因:如果要调用开发者自定义的BeanFactoryPostProcessor,那么在容器初期是需要容器自己来发现BeanFactoryPostProcessor,然后再实例化这些BeanFactoryPostProcessor的,那怎么发现呢?得先经过女娲娘娘**ConfigurationClassPostProcessor**的扫描才能发现开发者自定义的BeanFactoryPostProcessor,然后再调用BeanFactoryPostProcessor。
那具体我们可以对BeanDefinition修改些啥呢?
比如,在Spring中主要的实现类是PropertyPlaceholderConfigurer,主要是为了替换Bean属性中的${}变量为真正的属性值。当然其实在注解驱动的年代,这个类已经没那么重要了。这个类主要在XML时代,处理Bean属性中的${}变量,如下
<bean id="hello" class="com.example.bean.User">
<property name="name" value="${name}"></property>
</bean>
如果你问还有没有其他的应用,目前来看,在注解驱动的年代,我还真没有想出其他的应用场景,欢迎各位有实际应用场景的给我留言。
####第一阶段(容器启动阶段)总结 容器启动阶段,主要是两个巨牛逼的接口在发挥作用。由BeanDefinitionRegistryPostProcessor接口的实现类来实现对所有Bean的扫描从而得到BeanDefinition,然后再由BeanFactoryPostProcessor接口的实现类来对BeanDefinition进行修改完善。至此Bean的原材料就已经准备好了
###过度阶段(注册BeanPostProcessor)
注意:这个阶段在很多资料上都没有,这只是我自己定义的一个阶段,不过这都不重要,你只要知道我说的这个阶段它做了啥事,然后产生啥作用就可以了。
这个阶段的入口方法是
registerBeanPostProcessors(beanFactory);
你会发现直接委托给了这个方法
PostProcessorRegistrationDelegate#registerBeanPostProcessors
好了,这里只是为了记录一下入口,好方便你可以以后查看源代码,我们这里就不直接分析源代码了。
在我们完成第一阶段之后,我们的容器中就已经有了所有Bean的元数据BeanDefinition以及已经实例化好的BeanFactoryPostProcessor。接下来其实我们就要拿着BeanDefinition来实例化Bean了。但是在实例化的时候还缺少及其重要的辅材BeanPostProcessor。
所以这个过度阶段的主要作用就是向容器中注册实例化好并且排好序的
BeanPostProcessor。
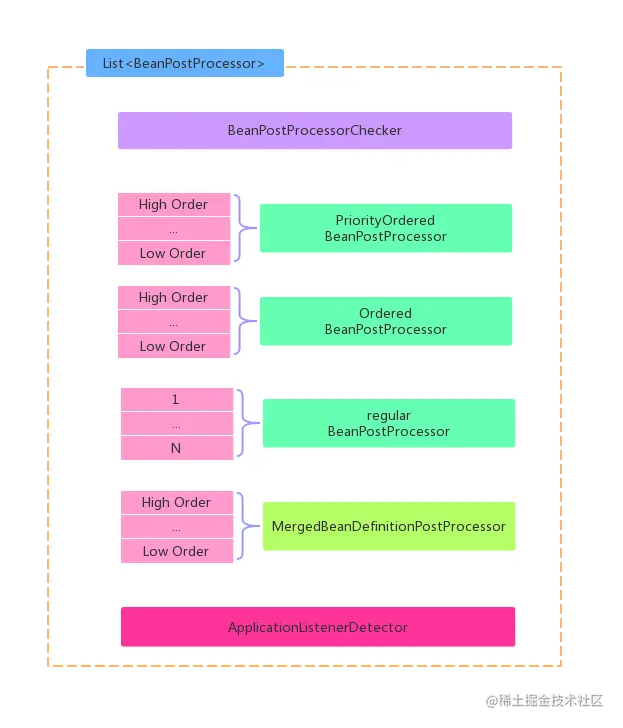
上图就是已经排好序的所有的BeanPostProcessor。你会发现这跟第一阶段BeanFactoryPostProcessor的排序规则很像。但是要注意的是,这里只是把排好序的BeanPostProcessor注册到容器中,正常情况下是不会调用BeanPostProcessor的任何方法的。
注意,这只是正常情况下是不会调用
BeanPostProcessor的任何方法的。但是有一种情况比较特殊,比如BeanPostProcessor依赖了普通Bean,那么就会导致实例化低优先级的BeanPostProcessor的时候,由于BeanPostProcessor依赖了普通Bean,那么就会先去实例化普通Bean后注入到实例化好的BeanPostProcessor中。这种情况会 导致我们的普通Bean提前初始化 ,从而导致普通Bean没有被所有的BeanPostProcessor处理过,有可能缺失一部分功能(如Spring的异步,或者没有被自己定义的BeanPostProcessor处理)。具体可以参考我前面的文章 Spring Bug深度历险记 Spring扩展点(BeanPostProssor)之深度诊断历险记
其实很多Spring的很魔法都要注意这些黑魔法背后的原理是是啥,是用什么组件处理的,处理Spring容器加载的哪一个阶段。如果前面阶段的黑魔法依赖后面阶段的黑魔法就会有问题。这个我们到后面会将具体的场景。
你要说这些BeanPostProcessor有啥用,我们这里暂且不谈。你只要知道这是个过度阶段,为实例化Bean准备了很多有序的BeanPostProcessor。
###第二阶段:实例化Bean
好了,终于到实例化Bean阶段了。前面所有的准备都做好了,下面正式进入主题:生产Bean。也就是最令人激动的后厨开始要炒菜了。
在讲具体的生产Bean的过程之前,我们先要明确生产Bean有两个必不可少的原材料
-
BeanDefinition -
BeanPostProcessor接口簇(BeanPostProcessor及其子接口)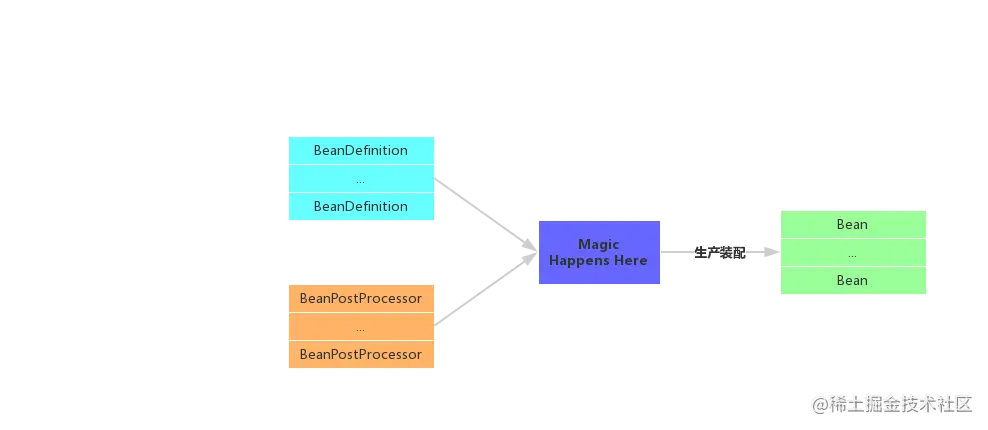
BeanPostProcessor接口簇其实有5个接口总共10个扩展方法,全程参与了Bean的生命周期。Spring各种神奇的黑魔法基本上都是通过扩展实现BeanPostProcessor接口或者其子接口来实现的。比如@Autowired @Value注解是通过AutowiredAnnotationBeanPostProcessor来是实现的。还有大名鼎鼎的Aop功能是通过AbstractAutoProxyCreator来实现的。
所以,其实Spring的一切黑魔法包括Aop其实都是通过扩展实现Spring预留的扩展接口来实现的。因此,Ioc容器才是Spring的根本,而Aop只是Ioc容器扩展点之一。但是,不是说Aop不重要,而是说一切的黑魔法的根本其实就是Spring IOC容器的各种扩展点的花式应用。
下面记录一下源代码的位置
AbstractApplicationContext{
refresh(){
// .....
finishBeanFactoryInitialization()
}
finishBeanFactoryInitialization(){
//...
// Instantiate all remaining (non-lazy-init) singletons.
beanFactory.preInstantiateSingletons();
}
}
DefaultListableBeanFactory{
preInstantiateSingletons(){}
}
AbstractBeanFactory{
getBean()
}
好了,下面我们就来分析一下Spring是如何创建Bean的
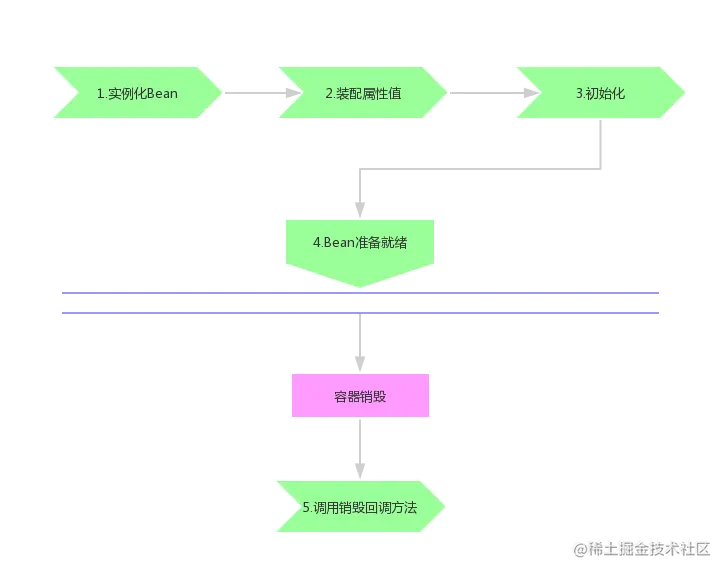
生产bean的流程其实就是这么几步。其中最为核心的也就是前三步:
- 实例化Bean
- 装配属性值
- 初始化
实例化Bean
你可能会说不就new个对象吗,怎么就能整这么多幺蛾子呢?这个吗也好理解,因为它是Spring吗,它做啥都是对的,而且还感觉这么做很牛逼。
鲁迅曾经说过:我家门前有两颗树,一颗是枣树,另外一颗也是枣树。
你品,你细细品。
好了,我们继续扯Spring。其实Spring在实例化Bean阶段是做了很多事的。
- 首先第一步,Spring在实例化具体的对象之前,给了BeanPostProcessor一次机会,来返回代理对象而不是实际的目标对象。
Give BeanPostProcessors a chance to return a proxy instead of the target bean instance.
具体点就是你可以调用**InstantiationAwareBeanPostProcessor 的postProcessBeforeInstantiation方法来返回一个你自己想要的对象,如果返回的不是null,那么只会调用BeanPostProcessor的postProcessAfterInitialization方法。之后该Bean就不会再执行初始化方法,依赖注入等生命周期了。也就是说这是一个 短路回调方法**。那这有个啥作用呢?目前最主要的作用就是在AOP中的应用,AOP的基类AbstractAutoProxyCreator实现了该方法。这里只需要有一个影响就可以了。
- 接下来,要是短路没成功的话,那么就需要真正实例化了。但是实例化又没有那么简单,因为Spring中可以使用构造方法来做依赖注入,那么在实例化对象的时候就要决定使用哪一个构造方法来实例化了。这个过程交给了**
SmartInstantiationAwareBeanPostProcessor**的determineCandidateConstructors方法。 - 然后实例化之后还会再回调**
MergedBeanDefinitionPostProcessor**的postProcessMergedBeanDefinition方法 来进一步有限度地修改BeanDefinition或者预处理一些注解(如预处理class,并缓存加了@Autowired注解的element) - 最后为了处理循环应用,还调用了
SmartInstantiationAwareBeanPostProcessor的getEarlyBeanReference方法来提前暴露引用。
装配属性值
- 首先调用**
InstantiationAwareBeanPostProcessor的postProcessAfterInstantiation**方法来决定是否有必要装备属性值。 - 如果有必要(正常情况下都是有必要的),那么就需要执行**
InstantiationAwareBeanPostProcessor的postProcessProperties或者postProcessPropertyValues**来处理依赖装配。
初始化
- 调用aware接口回调方法 invokeAwareMethods:包括
BeanNameAware,BeanClassLoaderAware,BeanFactoryAware - 调用初始化之前的回调方法:
BeanPostProcessor的postProcessBeforeInitialization - 调用初始化方法(invokeInitMethods)
InitializingBean的afterPropertiesSet自定义初始化方法(initMethod) - 初始化之后的回调方法
BeanPostProcessor的postProcessAfterInitialization
这个时候你也许就明白了,关于初始化的几个方法的先后顺序了
Constructor > @PostConstruct > InitializingBean > init-method
Constructor 首先被调用很容易理解,首先实例化,然后再初始化。而InitializingBean的afterPropertiesSet方法在init-method之前调用也比较容易理解,因为源代码就是这么先后调用的吗。那为啥@PostConstruct会在InitializingBean 的afterPropertiesSet方法之前被调用呢?其实,很简单,因为@PostConstruct的之所以起作用,是通过CommonAnnotationBeanPostProcessor的postProcessBeforeInitialization方法实现的。而前面的生命周期中说得很明白postProcessBeforeInitialization方法是在初始化之前被调用的。所以严格来说@PostConstruct并不是初始化方法,而是初始化之前的方法。不过,不重要,反正初始化和初始化之前也没有其他事情了,所以也可以近似认为@PostConstruct也是一种初始化方法吧。
至此,我们已经把Bean生命周期中最重要的前3部分已经讲清楚了。文章到这已经显得比较长了,但是还是有很多内容没有将清楚。 1.各种BeanPostProcessor的具体实现类有哪些,都有些啥作用 2.Spring的生命周期中的各种扩展点有哪些,怎么运用 3.AOP的实现原理 4.如何从Spring过渡到SpringBoot
后面我会一一讲解这些内容,敬请期待。