1.什么虚拟地址
虚拟地址实际上是操作系统为应用程序提供的一个统一的内存访问接口,这样做的好处是——所有的应用程序只需要面向虚拟地址进行编写,而不用考虑实际的物理地址的使用情况。
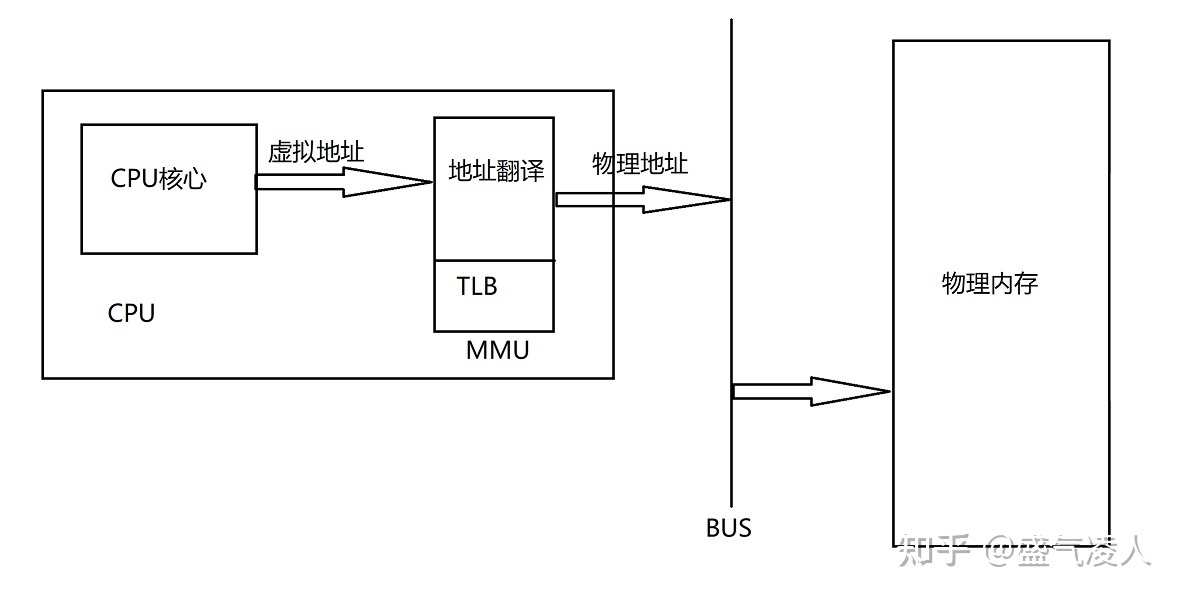
图1-1虚拟地址的翻译过程
如上图所示,CPU核心在执行某一程序时操作的始终是程序中的虚拟地址,虚拟地址经过MMU(内存管理单元)的翻译后才能得到实际要操作的物理地址。
2.虚拟地址的翻译过程
常见的翻译机制主要有两种:分别是分段机制和分页机制。
2.1分段机制(已基本被淘汰)
分段机制的核心是通过查询段表的的方式实现地址的映射。在分段机制下,操作系统会将虚拟内存和物理内存分割为若干大小不同的段,在段表中仅记录每个段对应的起始地址,和本段的长度。
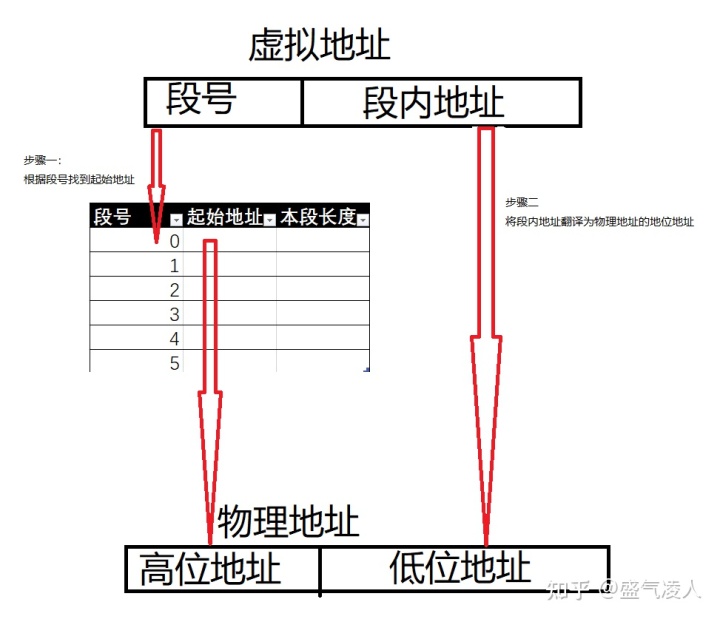
图1-2段表的翻译过程
首先MMU得到一个虚拟地址会将其分为段号和段内地址两部分,翻译的第一步是通过段号找到该段实际的物理地址的高位地址,配合段内偏移就可以计算出实际的内存地址位置。分段机制的优点在于,通过不同的虚拟地址的段号与物理地址建立的联系,可以将不连续的物理内存通过段号连接起来。但同时也容易在释放内存时产生**外部碎片。**例如将一块6GB的内存分为三个段分别为0~2GB,2~3GB,3~5GB,5~6GB,当我们释放掉第二和第四两个1GB的段空间,再像内存申请一块2GB的段时,由于这2GB的空间并不连续,无法合并为同一个段,因而会导致分配失败。分段机制曾经应用在Intel的80286中,但在后期的处理器上特别是X86-64出现后基本已经被淘汰。
2.2分页机制
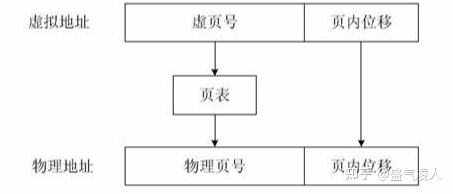
通过页表实现地址翻译
分页机制的核心是:
- 将实际的物理页分割成若干个4KB大小的存储空间
- 虚拟地址被分割为由若干虚拟页号(VPN)和实际页空间内偏移地址(VPO)两个部分
- 实际的页空间偏移地址在虚拟地址向物理地址转化过程中不变,我们只需根据虚拟地址的页号(VPN)找到最终实际页号(PPN)就可以实现地址转化
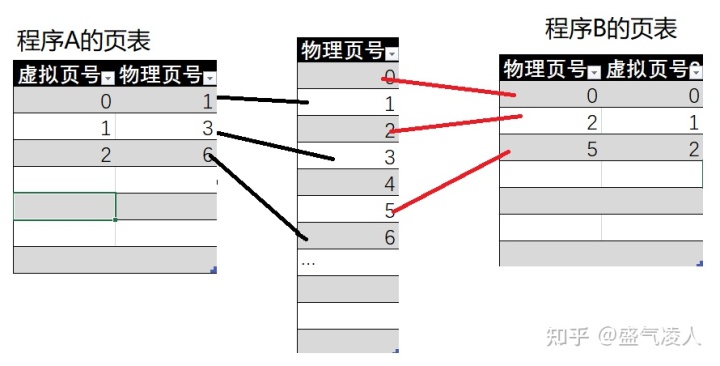
图1-3分页机制的翻译规则
分页机制的核心是页表,现代操作系统普遍使用分页机制。
3.基于分页机制的内存管理
采用分页机制带来的第一个问题就是页表的分配,每一个程序运行都需要一个页表作为翻译,如何科学的设计页表的结构变得尤为重要,目前多采用多级页表的方式。
多级页表
再讲多级页表之前先简单讲一下单级页表,如上图1-3所示,单级页表即将所有的虚拟地址一一映射的物理地址。单级页表可以快速的随机访问虚拟地址的页号找到对应的实际物理页号,但他带来的致命问题是页表所需的空间。以一个64位系统虚拟地址空间为例,每个页表项占用的空间为8Byte(64位系统)一般每个页表大小为4KB,从而可以得到 光是一级页表所用的空间需要2^{64}*8Byte/4KB=33 554 432GB ,这还仅是一个程序,显然这是无法实现的。
冷静分析一下,在大多数情况下我们实际上使用不了所有的虚拟地址,并且物理内存的大小也不可能支持所有虚拟地址进行映射,因此没有必要将所有的地址全部进行映射。那么能不能仅将需要的虚拟内存页进行映射呢,由此我们设计了多级页表:
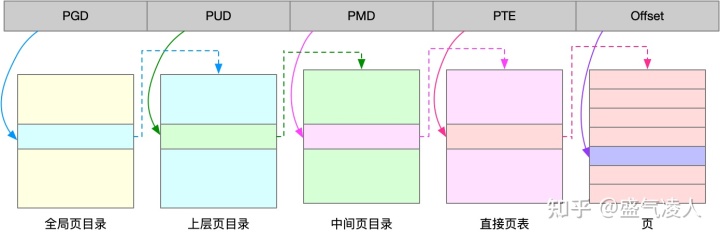
图1-4多级页表的实现过程
如上图所示,以四级页表为例,每个页表大小为4KB指向的是下级页表的起始地址,64位系统下每个地址需要使用8个字节,因此每个页表实际可以管理512个下一级页表(2的9次),从而推出每一级页表需要9位地址表示,四级页表也就需要36位地址,再加上最终的业内偏移地址需要表示4KB中每个字节的地址因此需要12位的偏移地址,所以实际一共用到了48位地址。
翻译过程
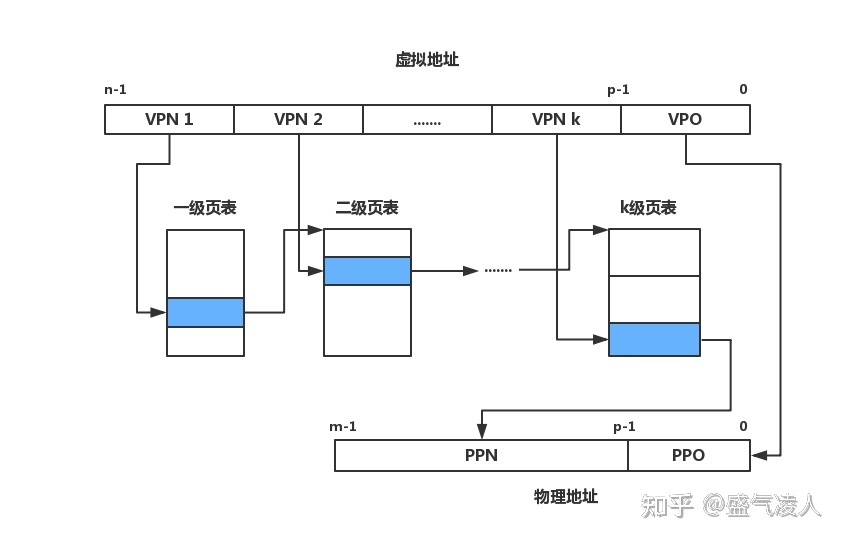
多级页表翻译过程
以及页表的起始地址保存在页表基地址寄存器中,VPN1保存的是9位一级页表中的偏移地址,该地址保存了8个字节的二级页表起始地址,再根据VPN2中保存的二级页表偏移地址找到三级页表的起始地址,以此类推就可以找到最后一级页表中保存的实际物理页表的起始地址。
多级页表的优点
举一个极端的例子,我们当前的程序需要使用第一个物理页和最后一个物理页的存储内容(0x00000000000和0xFFFFFFFFF000 48位36页表号和12位页内偏移)。若采用一级页表,则需要的页表数为 2^{36} ,页表使用的空间为 2^{36} *8Bit=512GB,这显然不可能实现。使用多级页表后我们就不要将所有的虚拟地址和实际物理地址全部进行映射,以四级页表为例如下图所示只需要七个页表就可以实现相同的地址翻译。
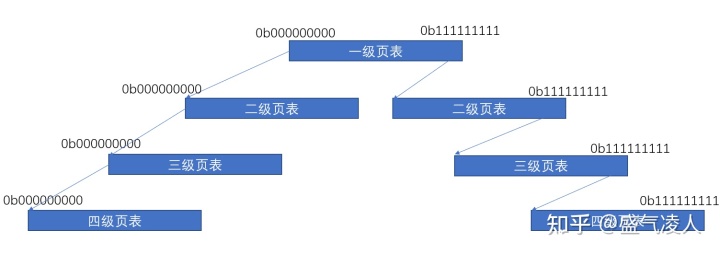
四级页表下的翻译过程
四级页表通过跳过不使用的虚拟地址,从而大大减小了所需的页表数量,但四级页表的翻译过程相对时间过长,对于一些经常访问的地址我们能否直接再一次查询后记录,然后直接调用记录的物理地址呢。答案是可以,这就引出另一个重要的概率TLB(见图1-1)。
4.TLB 转址旁路缓存(Translation Lookaside Buffer)
TLB的作用就是将通过页表查询得到的虚拟地址和物理地址间的映射保存,当需要访问一个地址时,我们可以通过直接进行TLB查询找到目标地址,若TLB未命中则进行页表查询,查询到新的页地址后,再将新的映射加入到TLB中,ruoTLB已满则按照硬件预定的策略替换掉某一项。
TLB刷新
想象一下这种情况,若进程A、B均使用了虚拟地址Va,但他们各自对应不同的实际物理地址Pa1和Pa2。但进程A范围Va后会在TLB中保存Va对应的物理地址Pa1,而当进程B再次访问Va时由于TLB中已经缓存了物理地址Pa1,此时进程B就会出现访问出错。
为了避免这种情况的发生,操作系统在发生进程调度后会主动取刷新一次TLB(清除所有已经缓存的虚拟地址),以防止不同进程间的访问出错。
TLB缓存标签
若每发生一次进程调度,就进行一次TLB全局刷新显然会造成系统整体的性能降低,为了减小这种损失,设计了TLB缓存标签,以区分不同进程的相同虚拟地址。在AArch64体系的架构中使用率ASID(address space Identifier)技术,操作系统会将不同进程分配不同的ASID作为其身份标签,同时在TLB的缓存项中也会加上该标签,使得不同进程的相同虚拟地址得以区分。