Spring作为目前最流行的开发框架,逐渐被大家所熟悉,本文主要介绍Spring中对于循环依赖的处理方案,主要从以下几个点中进行介绍:
- 为什么会产生循环依赖
- Spring如何解决循环依赖
- 循环依赖带给我们的反思
第一部分:为什么会产生循环依赖?
以下仅为一个例子,帮助大家理解产生循环依赖的场景。
场景介绍
在平时开发一个功能时,如结算功能时,由于整个的结算的流程异常复杂,但是大致的流程为:订单完成 —> 产生结算明细(SettleDetail) —> 根据结算明细生成结算单(SettleOrder)。
在上述的业务逻辑中,我们的第一印象是将结算明细和结算单分别设计成数据库中的两张表,对应的也就会出现结算明细服务(SettleDetailService)和结算单服务(SettleOrderService),在我们起初设计这段业务时,是很理想的,结算单作为结算明细的上层,SettleOrderService调用SettleDetailService。
但是突然有一天,产品经理说:希望能否对结算明细进行调账,并且调账完成的后的结果需要作用到对应的结算单上,在此时对于不注意循环依赖的小伙伴(好吧,就是我自己)来说,可能就出现了在SettleDetailService中引入SettleOrderService,虽然解决了产品的需求,但是,此时就产生了循环依赖了,使我们的代码看起来不那么优雅了!但是,虽然我们写了一些不优雅的代码,但是在启动的时候似乎也并没有什么问题产生,以致于很多小伙伴认为这样的循环引用并没有什么问题。但事实真的是这样嘛?肯定不是啊,不会就不会出现这边文章啦。且听笔者娓娓道来。
第二部分:Spring如何解决循环依赖?
当我们使用下图的注入方式,注入SettleOrderService到SettleDetailService、注入SettleDetailService到SettleOrderService时,启动项目时,我们并未发现出现错误,对此,一些好奇的小伙伴不免会有些疑惑,我们本着求知到底的精神,一起去深挖下为什么这么写代码不会出现问题。


循环依赖的本质
通过上图中的例子,我们发现settleDetailServiceImpl引入了settleOrderService,而settleOrderServiceImpl引入了settleDetailService,其本质就是两个对象相互引用对方,最终形成闭环。
循环依赖的解决
想要理解循环依赖的解决方式,我们需要了解对象创建的过程,总体概括为两步:对象的实例化和对象属性初始化。我们知道在Spring中的对象创建是由框架所代理的,所以我们无需关心对象的创建的具体过程,但其本质也是前面所说的对象的实例化和初始化两个步骤。对于解决循环依赖,这个概念我们需要了解。为了能够理解Spring解决循环依赖的方法,我们直接源码撸起来。 (由于Spring的Bean加载的流程不作为本文的叙述内容,所以笔者在这里不做赘述,感兴趣的读者可以自行了解。)
第三部分:源码分析
1.AbstractBeanFactory#doGetBean()
笔者以上述的例子作为演示,看看Spring是如何构造出settleDetailServiceImpl和settleOrderServiceImpl这两个对象的。通过了解Spring的Bean加载的流程,我们着重观察AbstractBeanFactory#doGetBean()方法,其代码如下:
/**
* Return an instance, which may be shared or independent, of the specified bean.
* @param name the name of the bean to retrieve
* @param requiredType the required type of the bean to retrieve
* @param args arguments to use when creating a bean instance using explicit arguments
* (only applied when creating a new instance as opposed to retrieving an existing one)
* @param typeCheckOnly whether the instance is obtained for a type check,
* not for actual use
* @return an instance of the bean
* @throws BeansException if the bean could not be created
*/
@SuppressWarnings("unchecked")
protected <T> T doGetBean(final String name, @Nullable final Class<T> requiredType,
@Nullable final Object[] args, boolean typeCheckOnly) throws BeansException {
final String beanName = transformedBeanName(name);
Object bean;
// Eagerly check singleton cache for manually registered singletons.
Object sharedInstance = getSingleton(beanName); **A**
if (sharedInstance != null && args == null) {
...
} else {
// Fail if we're already creating this bean instance:
// We're assumably within a circular reference.
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
// Check if bean definition exists in this factory.
BeanFactory parentBeanFactory = getParentBeanFactory();
if (parentBeanFactory != null && !containsBeanDefinition(beanName)) {
// Not found -> check parent.
String nameToLookup = originalBeanName(name);
if (parentBeanFactory instanceof AbstractBeanFactory) {
return ((AbstractBeanFactory) parentBeanFactory).doGetBean(
nameToLookup, requiredType, args, typeCheckOnly);
}
else if (args != null) {
// Delegation to parent with explicit args.
return (T) parentBeanFactory.getBean(nameToLookup, args);
}
else if (requiredType != null) {
// No args -> delegate to standard getBean method.
return parentBeanFactory.getBean(nameToLookup, requiredType);
}
else {
return (T) parentBeanFactory.getBean(nameToLookup);
}
}
if (!typeCheckOnly) {
markBeanAsCreated(beanName);
}
try {
final RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
checkMergedBeanDefinition(mbd, beanName, args);
// Guarantee initialization of beans that the current bean depends on.
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
for (String dep : dependsOn) {
if (isDependent(beanName, dep)) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Circular depends-on relationship between '" + beanName + "' and '" + dep + "'");
}
registerDependentBean(dep, beanName);
try {
getBean(dep);
}
catch (NoSuchBeanDefinitionException ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"'" + beanName + "' depends on missing bean '" + dep + "'",ex);
}
}
}
// Create bean instance. **B**
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
// Explicitly remove instance from singleton cache: It might have been put there
// eagerly by the creation process, to allow for circular reference resolution.
// Also remove any beans that received a temporary reference to the bean.
destroySingleton(beanName);
throw ex;
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}else if (mbd.isPrototype()) {
...
}else {
...
}
}
catch (BeansException ex) {
cleanupAfterBeanCreationFailure(beanName);
throw ex;
}
}
// Check if required type matches the type of the actual bean instance.
...
return (T) bean;
}
AbstractBeanFactory#doGetBean()
代码相对较长,我们着重关注标注的代码段即可。
代码段A
从缓存中检查是否存在已经注册的单例对象信息。
其调用了getSingleton()方法,这里我们或许会疑问,为啥在创建对象之前需要进行这样一步校验?这个问题的答案也就是Spring解决循环依赖的关键所在了,咱们先带着这个疑问接着往下看。
我们去查看getSingleton()的内部实现,代码如下:
getSingleton方法
/**
* Return the (raw) singleton object registered under the given name.
* <p>Checks already instantiated singletons and also allows for an early
* reference to a currently created singleton (resolving a circular reference).
* @param beanName the name of the bean to look for
* @param allowEarlyReference whether early references should be created or not
* @return the registered singleton object, or {@code null} if none found
*/
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
DefaultSingletonBeanRegistry#getSingleton()
上述代码中,我们发现有三个集合对象,singletonObjects、earlySingletonObjects以及singletonFactories。为了理解上述代码的处理逻辑,我们需要了解这三个对象的所代表的意义,查看其源码中的注释发现:
/** Cache of singleton objects: bean name to bean instance. */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** Cache of singleton factories: bean name to ObjectFactory. */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/** Cache of early singleton objects: bean name to bean instance. */
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
三个Map的作用
- singletonObjects: 存储Bean名称对单例Bean的映射关系
- singletonFactories: 存储Bean名称对ObjectFactory的映射关系
- earlySingletonObjects: 存储Bean名称对预加载Bean的映射关系
这三个Map对象也就是大家耳熟能详的三级缓存了,在理解了这三个Map的作用之后,我们再尝试理解getSingleton()代码的意义,其实不难理解,该方法的意义是先从singletonObjects中获取单例对象,如果不存在已经创建好的单例对象信息,则从earlySingletonObjects中获取预加载的对象信息,如果预加载的对象信息也不存在时,则从singletonFactories中获取对象工厂信息,调用工厂方法来创建预加载对象,并将创建好的预加载的对象信息存入到earlySingletonObjects中,并将当前对象的工厂对象从singletonFactories中移除。通过对该方法含义的解读,我们可以知道一点,该方法最终返回的对象信息,要么是已经创建好的单例对象信息,要么就是预加载的对象信息。
 getSingleton()处理流程
getSingleton()处理流程
可能有些小伙伴对于singletonObjects中存储的对象和earlySingletonObjects中存储的对象信息到底有哪些区别还不清楚,简单来说,singletonObjects中存储的是已经完成实例化和初始化的对象信息,而earlySingletonObjects里存放的已经完成实例化但还未初始化的对象信息。(这就是上面让大家理解对象创建流程的意义所在了)
由于是框架第一次尝试从缓存中获取settleDetailServiceImpl对象,所以singletonObjects、earlySingletonObjects及singletonFactories都不存在对应的对象信息,此时getSingleton()方法返回对象为null,如下图所示:
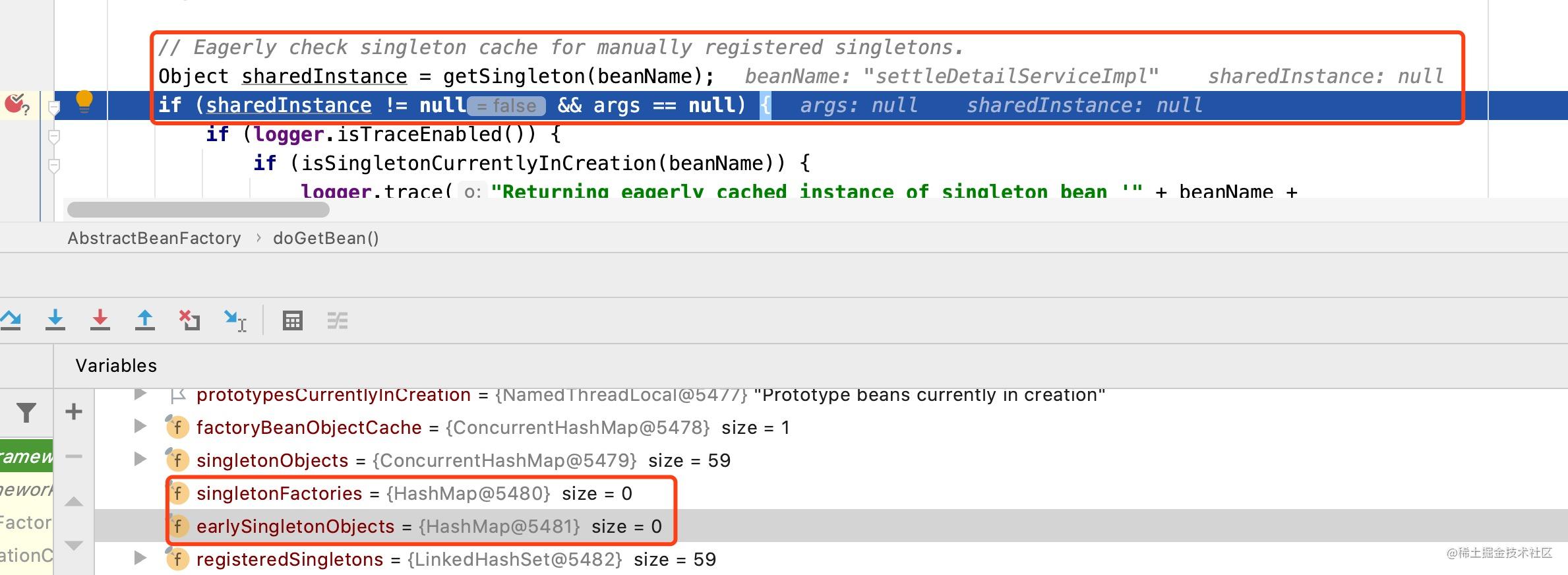
代码段B
当代码段A处无法获取到对象信息时,此时会进入代码段B的处理逻辑中,该段代码的作用是创建一个实例对象,应用到我们这个例子中,就是框架会尝试去创建settleDetailServiceImpl对象。
2.AbstractBeanFactory#createBean()
通过调用AbstractBeanFactory#createBean()方法来进行对象的创建,我们看看createBean()方法的内部具体的代码实现。
/**
* Actually create the specified bean. Pre-creation processing has already happened
* at this point, e.g. checking {@code postProcessBeforeInstantiation} callbacks.
* <p>Differentiates between default bean instantiation, use of a
* factory method, and autowiring a constructor.
* @param beanName the name of the bean
* @param mbd the merged bean definition for the bean
* @param args explicit arguments to use for constructor or factory method invocation
* @return a new instance of the bean
* @throws BeanCreationException if the bean could not be created
* @see #instantiateBean
* @see #instantiateUsingFactoryMethod
* @see #autowireConstructor
*/
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)throws BeanCreationException {
// Instantiate the bean. **C**
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
final Object bean = instanceWrapper.getWrappedInstance();
Class<?> beanType = instanceWrapper.getWrappedClass();
if (beanType != NullBean.class) {
mbd.resolvedTargetType = beanType;
}
// Allow post-processors to modify the merged bean definition.
...
// Eagerly cache singletons to be able to resolve circular references. **D**
// even when triggered by lifecycle interfaces like BeanFactoryAware.
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
// Initialize the bean instance.
Object exposedObject = bean;
try {
populateBean(beanName, mbd, instanceWrapper); **E**
exposedObject = initializeBean(beanName, exposedObject, mbd); **F**
}
catch (Throwable ex) {
...
}
if (earlySingletonExposure) {
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length);
for (String dependentBean : dependentBeans) {
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
}
// Register bean as disposable.
...
return exposedObject;
}
AbstractAutowireCapableBeanFactory#doCreateBean
上述代码依然进行了部分删除,我们着重关注标注的那部分代码即可。
代码段C
实例化对象信息 (对象实例化的具体过程不做详细讲解,有兴趣的小伙伴可以自行查看哈),经历了对象的实例化之后,此时我们已经获得了一个settleDetailServiceImpl对象信息,虽然此时还未进行属性的初始化,属性值settleOrderService依然为null。
如下图所示:
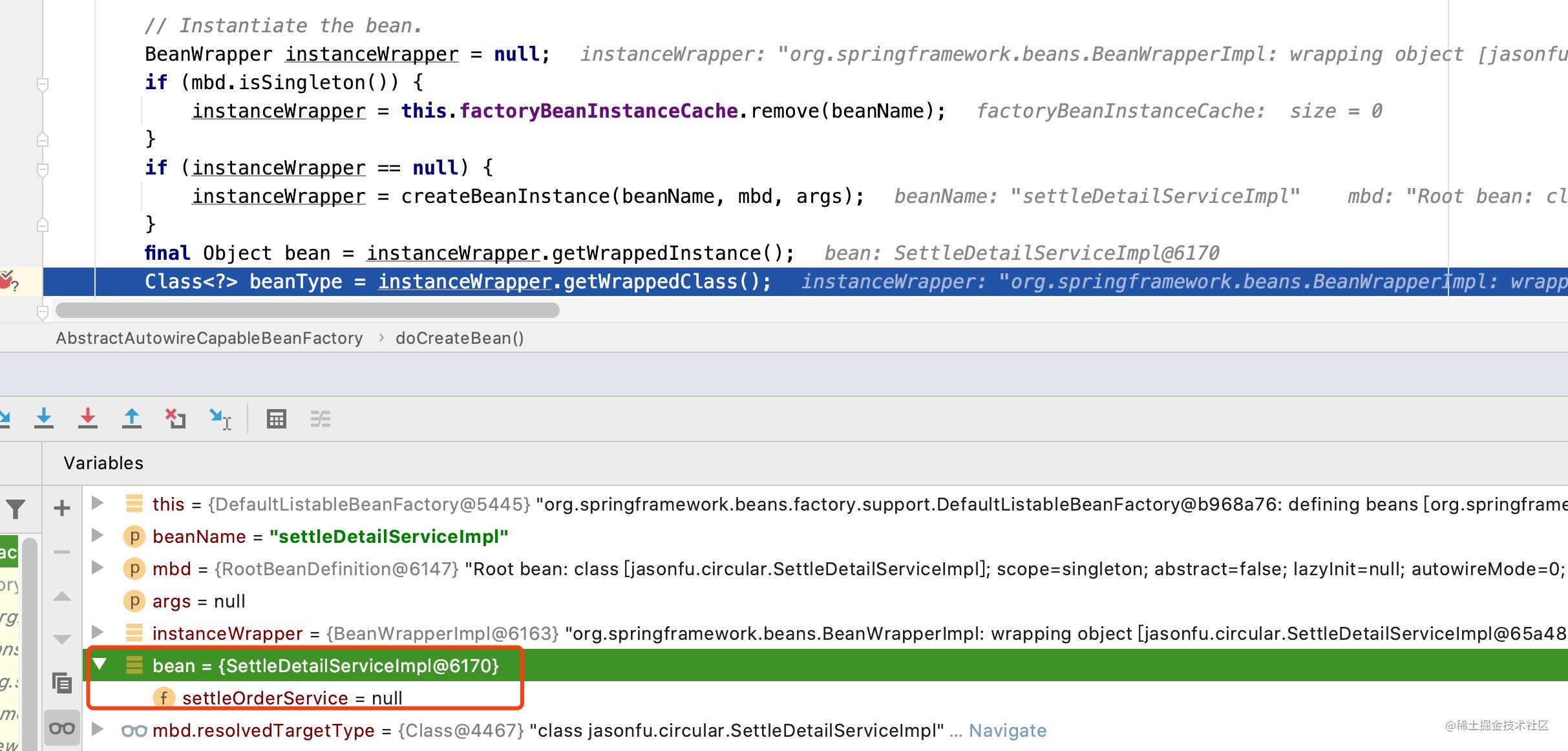
代码段D
当完成了对象的实例化之后,该段代码会尝试将创建好的对象信息的工厂对象信息加入到singletonFactories这个Map中去,代码中的注释对于这段代码的解释翻译过来的大致意思为:缓存对象信息已解决循环依赖问题。虽然注释是这么解释的,但是很多小伙伴可能依然不理解这段代码的意图,为何在此处需要将settleDetailServiceImpl的工厂信息放入到singletonFactories中去,我们带着这个疑问继续往下看,我们现在只需要知道在此时框架将settleDetailServiceImpl的工厂对象加入到了singletonFactories中即可。
如下图所示:
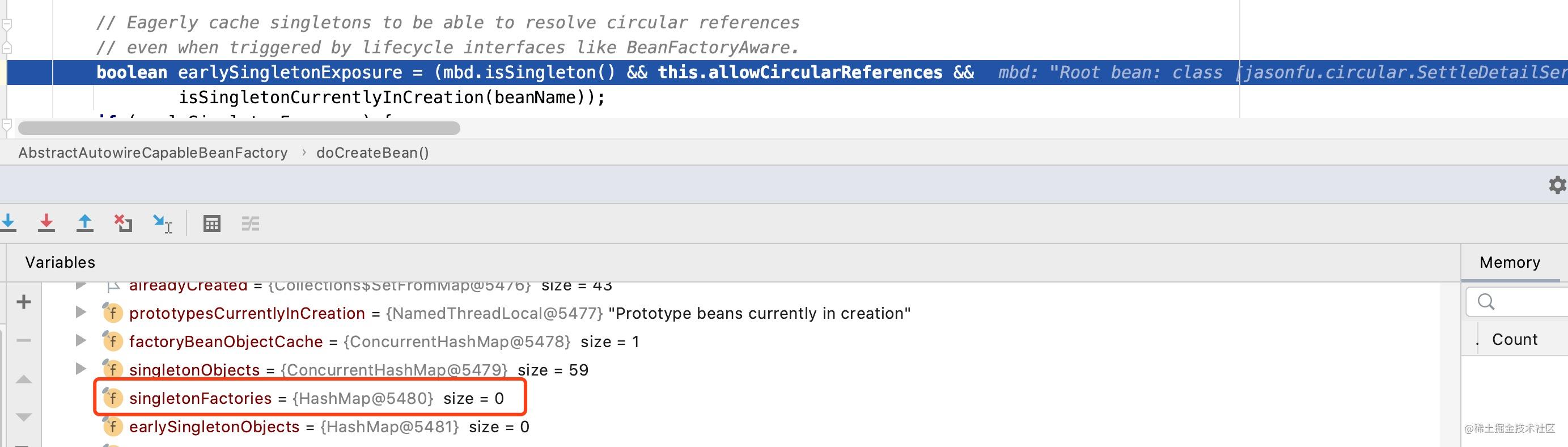 工厂对象加入Map之前
工厂对象加入Map之前
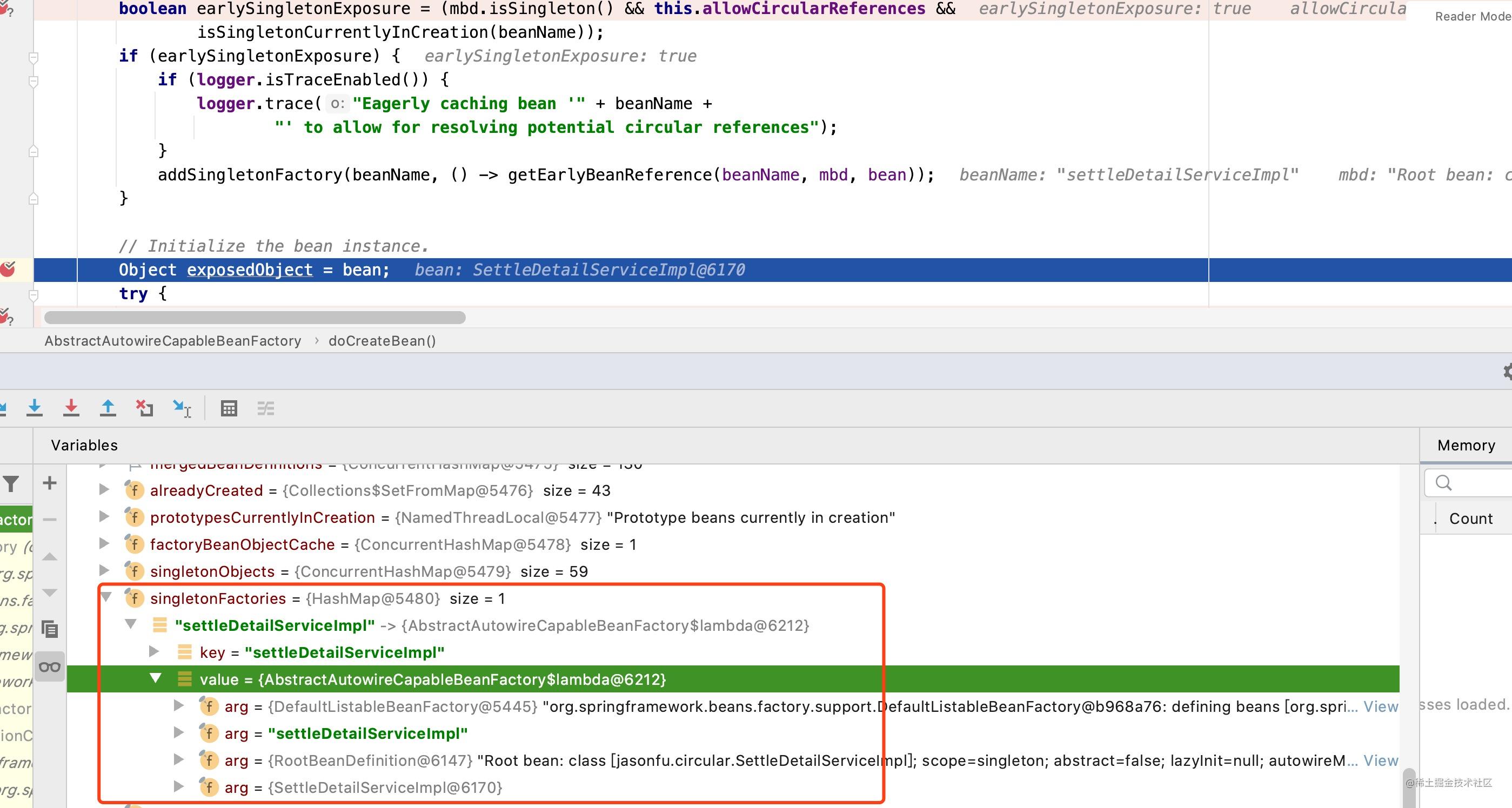 工厂对象加入Map之后
工厂对象加入Map之后
代码段E、F
当完成对象的实例化以及将对象工厂对象信息加入到singletonFactories中后,后面框架开始对settleDetailServiceImpl进行初始化的相关处理。E处调用了方法populateBean()方法,我们看看poulateBean()方法内部做了哪些事情,其内部代码实现如下:
3.AbstractAutowireCapableBeanFactory#populateBean
/**
* Populate the bean instance in the given BeanWrapper with the property values
* from the bean definition.
* @param beanName the name of the bean
* @param mbd the bean definition for the bean
* @param bw the BeanWrapper with bean instance
*/
@SuppressWarnings("deprecation") // for postProcessPropertyValues
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) {
if (bw == null) {
if (mbd.hasPropertyValues()) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Cannot apply property values to null instance");
}
else {
// Skip property population phase for null instance.
return;
}
}
// Give any InstantiationAwareBeanPostProcessors the opportunity to modify the
// state of the bean before properties are set. This can be used, for example,
// to support styles of field injection.
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
if (!ibp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
return;
}
}
}
}
PropertyValues pvs = (mbd.hasPropertyValues() ? mbd.getPropertyValues() : null);
int resolvedAutowireMode = mbd.getResolvedAutowireMode();
if (resolvedAutowireMode == AUTOWIRE_BY_NAME || resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
// Add property values based on autowire by name if applicable.
if (resolvedAutowireMode == AUTOWIRE_BY_NAME) {
autowireByName(beanName, mbd, bw, newPvs);
}
// Add property values based on autowire by type if applicable.
if (resolvedAutowireMode == AUTOWIRE_BY_TYPE) {
autowireByType(beanName, mbd, bw, newPvs);
}
pvs = newPvs;
}
boolean hasInstAwareBpps = hasInstantiationAwareBeanPostProcessors();
boolean needsDepCheck = (mbd.getDependencyCheck() != AbstractBeanDefinition.DEPENDENCY_CHECK_NONE);
PropertyDescriptor[] filteredPds = null;
if (hasInstAwareBpps) {
if (pvs == null) {
pvs = mbd.getPropertyValues();
}
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp; **G**
PropertyValues pvsToUse = ibp.postProcessProperties(pvs, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
if (filteredPds == null) {
filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
}
pvsToUse = ibp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvsToUse == null) {
return;
}
}
pvs = pvsToUse;
}
}
}
if (needsDepCheck) {
if (filteredPds == null) {
filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
}
checkDependencies(beanName, mbd, filteredPds, pvs);
}
if (pvs != null) {
applyPropertyValues(beanName, mbd, bw, pvs);
}
}
AbstractAutowireCapableBeanFactory#populateBean
我们先看其注释说了些什么,翻译过来大致意思为:使用bean定义中的属性值填充给定BeanWrapper中的Bean实例;我们可以理解该方法做了一件事情,就是填充对象的属性信息。我们着重关注标注的代码段G,该段代码的作用先是获取创建Bean的一系列的BeanPostProcessor列表,而后使用BeanPostProcessor的子接口InstantiationAwareBeanPostProcessor#postProcessProperties()方法对实例对象的属性进行修改。
这里简单补充一下BeanPostProcessor和InstantiationAwareBeanPostProcessor接口的作用;BeanPostProcessor的作用是在Spring完成实例化之后,对实例化的对象添加一些自定义的处理逻辑;InstantiationAwareBeanPostProcessor为BeanPostProcessor的子接口,它除了BeanPostProcessor接口的功能之外,还增强了三个方法,postProcessBeforeInstantiation 、postProcessAfterInstantiation()、postProcessProperties()。
- postProcessBeforeInstantiation: 在对象被实例化之前调用该方法可以实现替换生成的Bean的目的
- postProcessAfterInstantiation: 在对象被实例化之后调用,该方法的返回值作为是否调用postProcessPropertyValues的一个决定因素
- postProcessProperties: 修改对象属性值
接着上面的代码分析,我们发现框架使用了InstantiationAwareBeanPostProcessor#postProcessProperties()方法对实例对象的属性进行修改,postProcessProperties也存在很多具体的实现,如下图所示:
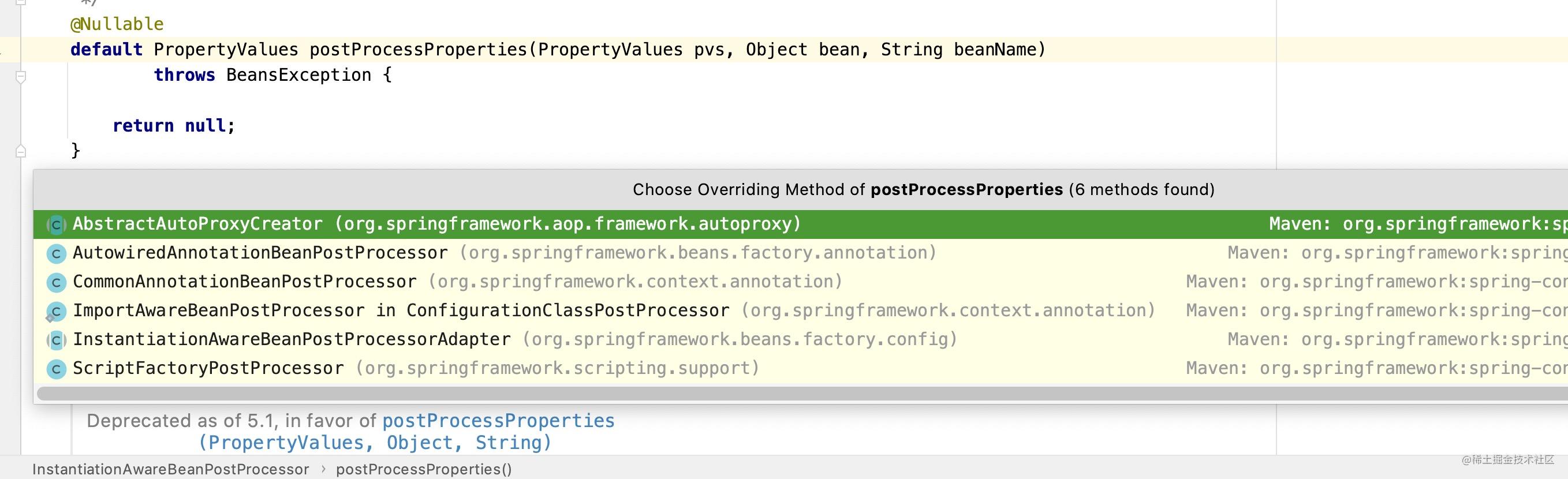
我们着重关注AutowiredAnnotationBeanProcessor#postProcessProperties()中的实现,其代码实现如下:
InjectionMetadata#inject
public void inject(Object target, @Nullable String beanName, @Nullable PropertyValues pvs) throws Throwable {
Collection<InjectedElement> checkedElements = this.checkedElements;
Collection<InjectedElement> elementsToIterate =
(checkedElements != null ? checkedElements : this.injectedElements);
if (!elementsToIterate.isEmpty()) {
for (InjectedElement element : elementsToIterate) {
if (logger.isTraceEnabled()) {
logger.trace("Processing injected element of bean '" + beanName + "': " + element);
}
element.inject(target, beanName, pvs);
}
}
}
InjectionMetadata#inject
InjectionMetadata#inject()方法实现最终的属性注入,对我们的例子来说,就是将SettleOrderService对象注入到settleDetailServiceImpl对象中,如下图所示:
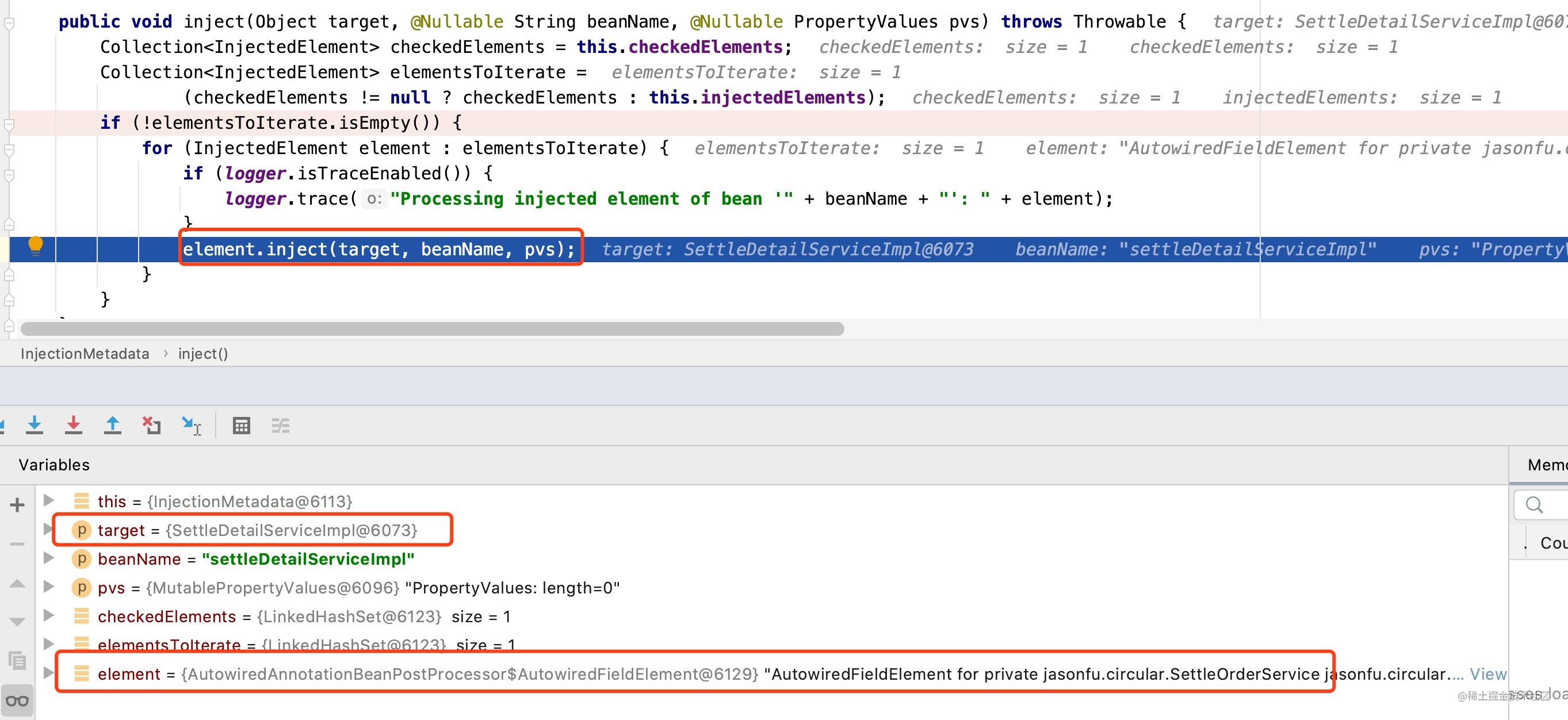
注入的具体逻辑不作为本文的叙述的中不做详细的赘述,但这里提供追踪具体注入的逻辑的trace,供感兴趣的小伙伴研究;
具体trace如下:
InjectionMetadata#inject -> DefaultListableBeanFactory#resolveDependency -> DefaultListableBeanFactory#doResolveDependency -> DependencyDescriptor#resolveCandidate -> AbstractBeanFactory#getBean
当框架尝试将SettleOrderService对象注入到settleDetailServiceImpl时,调用DefaultListableBeanFactory#doResolveDependency方法来获取满足SettleOrderService的对象信息,由于此时框架中还没有满足条件的SettleOrderService的实例对象信息,所以注入的时候会调用AbstractBeanFactory#getBean方法创建一个满足条件的对象;通过分析上述一段注入的逻辑,我们可以得出一个结论:当一个对象在创建的时候,其所依赖的对象信息不存在的时候,框架会尝试先创建所依赖的对象,来完成对象对象的创建。应用到我们的例子中,当我们尝试在初始化settleDetailServiceImpl对象时,发现其依赖了SettleOrderService对象,但是此时SettleOrderService还不存在,所以创建先尝试创建SettleOrderService对象信息,创建方法和创建settleDetailServiceImpl对象的方法一样,也就是我们上面一直追溯的代码了,不理解的小伙伴可以再尝试理解一下我们上面做的那些事情。
这里我们快速过一遍SettlOrderService的对象创建过程,先是从缓存中查看是否存在已经创建好的settleOrderServiceImpl对象信息,由于是第一次创建,所以肯定不会存在,此时的singletonFactories对象只存在settleDetailServiceImpl与其工厂对象的信息,如下图所示:
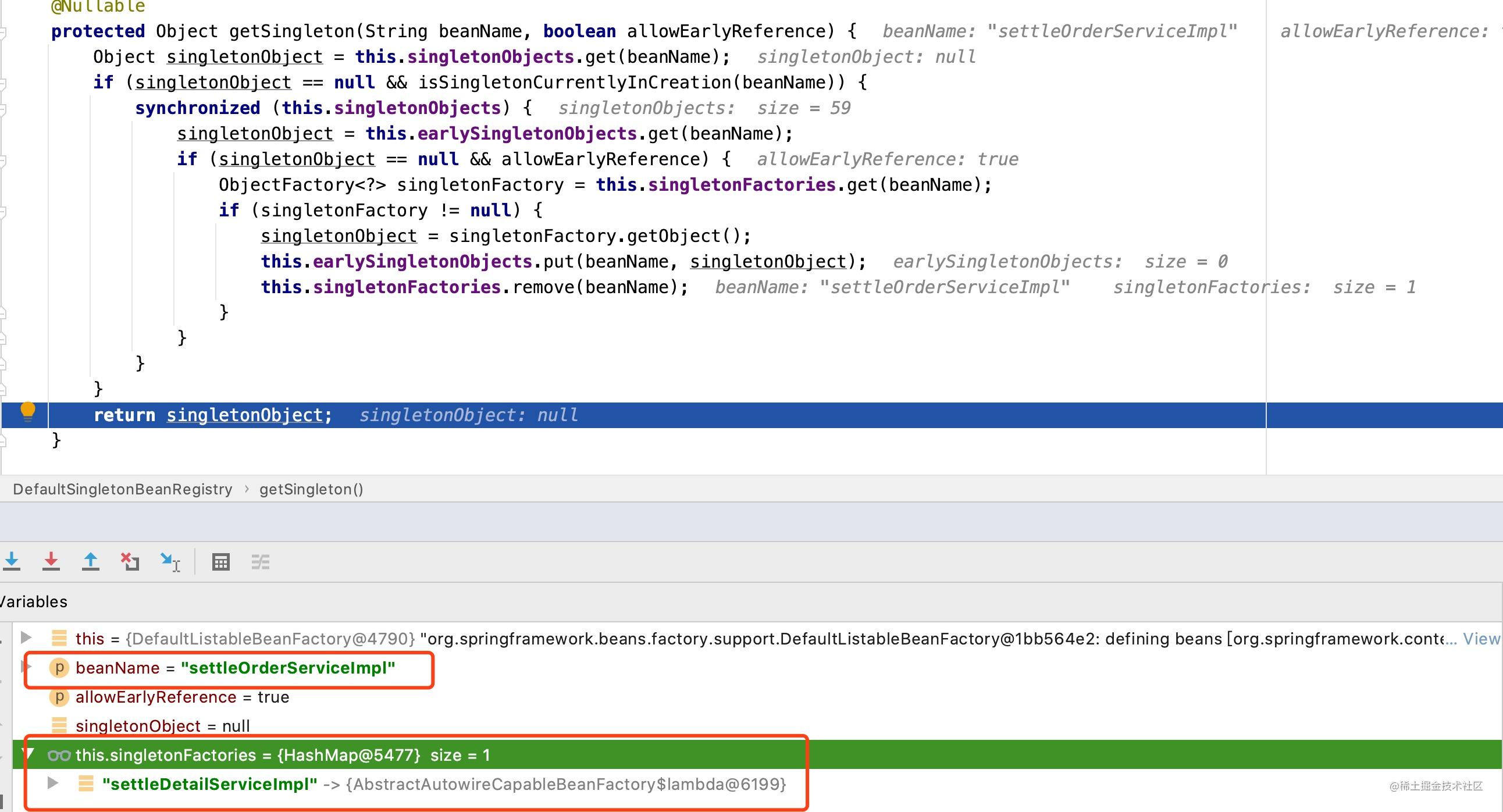
缓存中不存在settleOrderServiceImpl对象信息时,框架会继续我们上面分析的创建对象的过程,先是实例化settleOrderServiceImpl;而后将settleOrderServiceImpl的工厂信息加入到singletonFactories中,如下图所示:
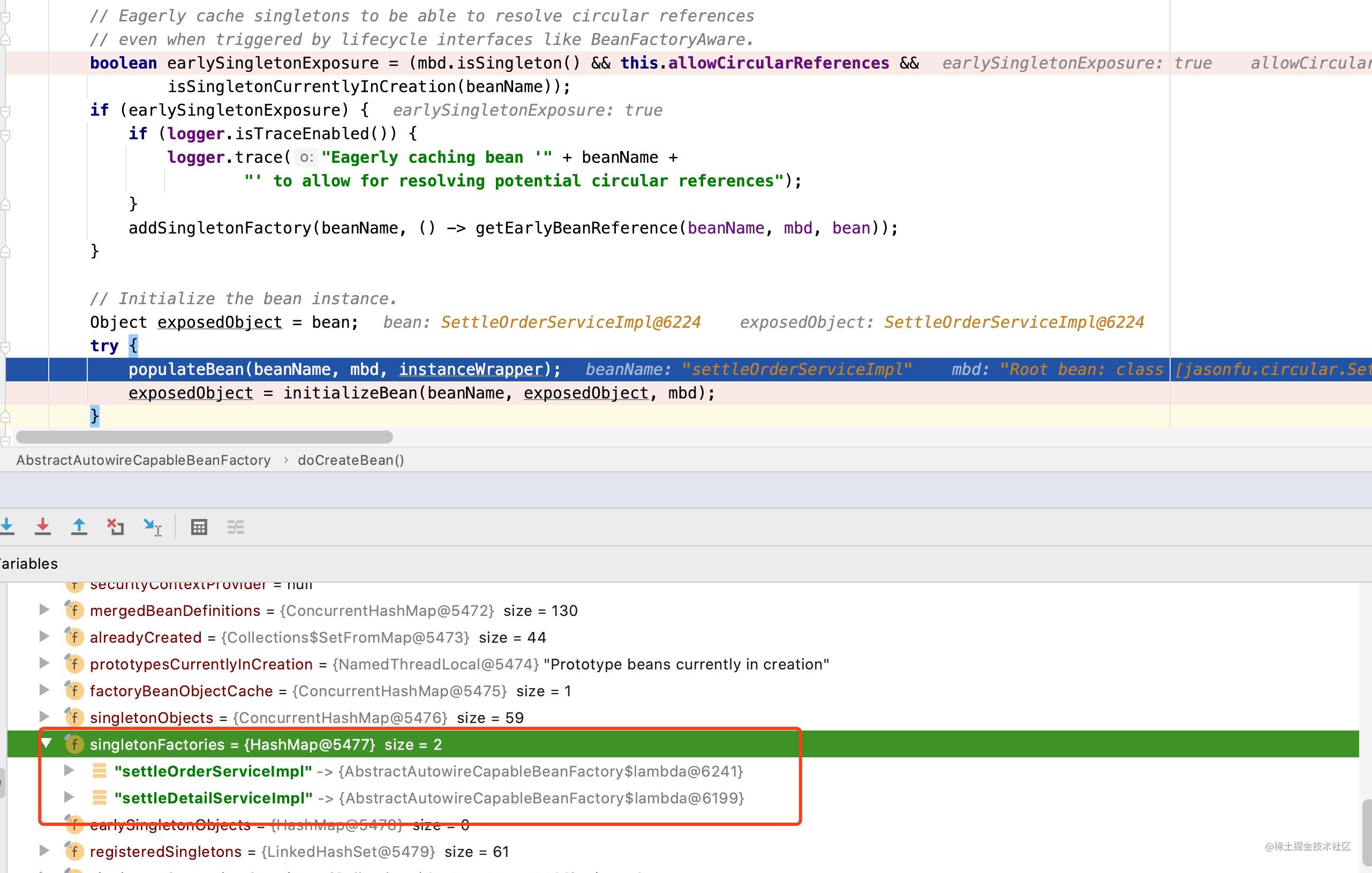
此时singletonFactories中存在settleDetailServiceImpl和settleOrderServiceImpl两个工厂对象的映射关系;然后是进行settleOrderServiceImpl对象的初始化,settleOrderServiceImpl中存在一个属性值SettleDetailService,框架会尝试寻找一个满足SettleDetailServiceImpl的对象信息,但是我们知道到目前为止,框架中存放的只是settleDetailServiceImpl和settleOrderServiceImpl两个工厂对象的映射关系,当框架再次尝试settleDetilServiceImpl对象信息时,回调用singletonFactory.getObject()方法并将创建好的对象信息加入到earlySingletonObjects中,且将settleDetailServiceImpl的映射关系从singletonFactories中移除,此时已经返回一个预加载settleDetailServiceImpl的对象信息了,如下图所示:
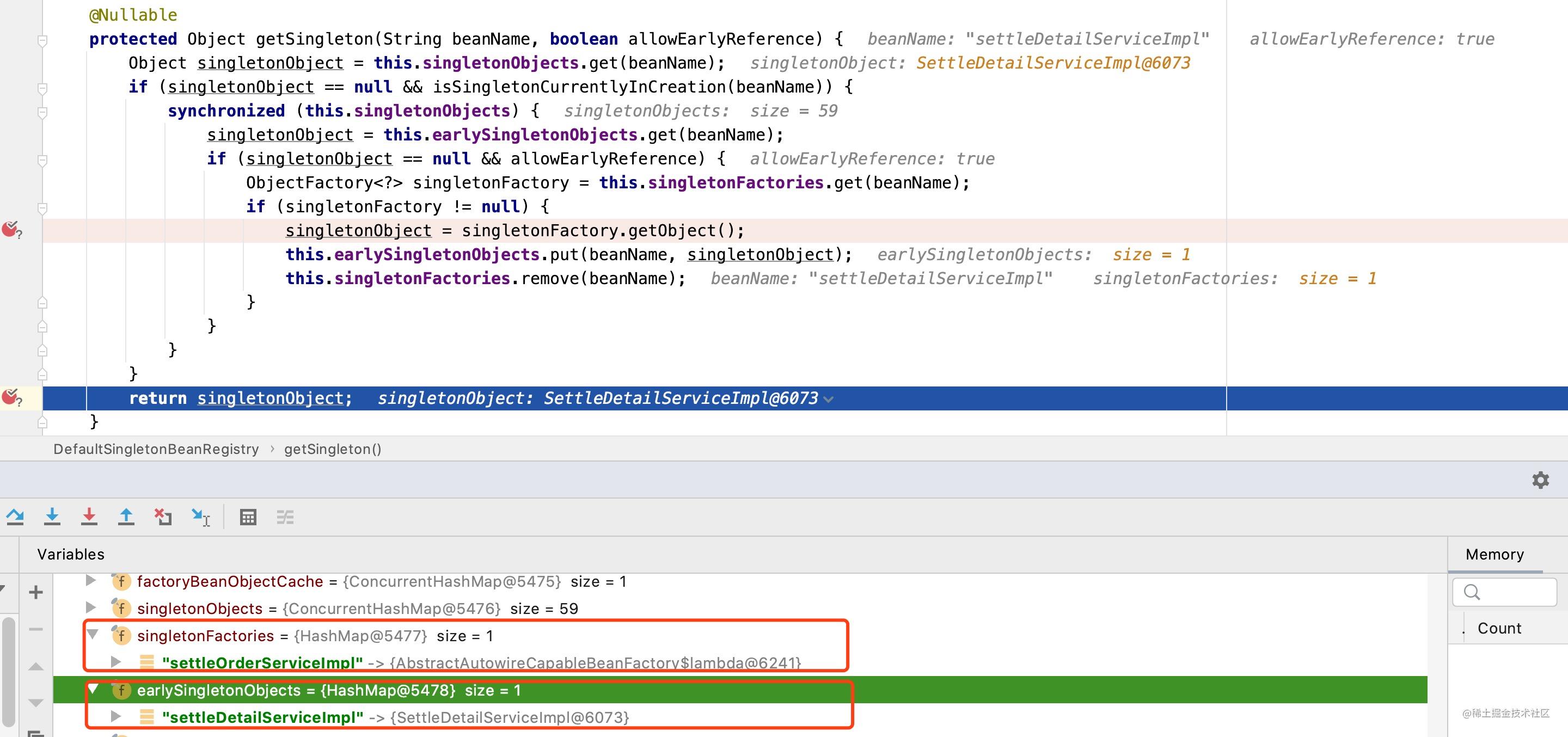
最终通过反射将创建好的settleDetailServiceImpl对象信息设置到settleOrderServiceImpl中去,如下图所示:
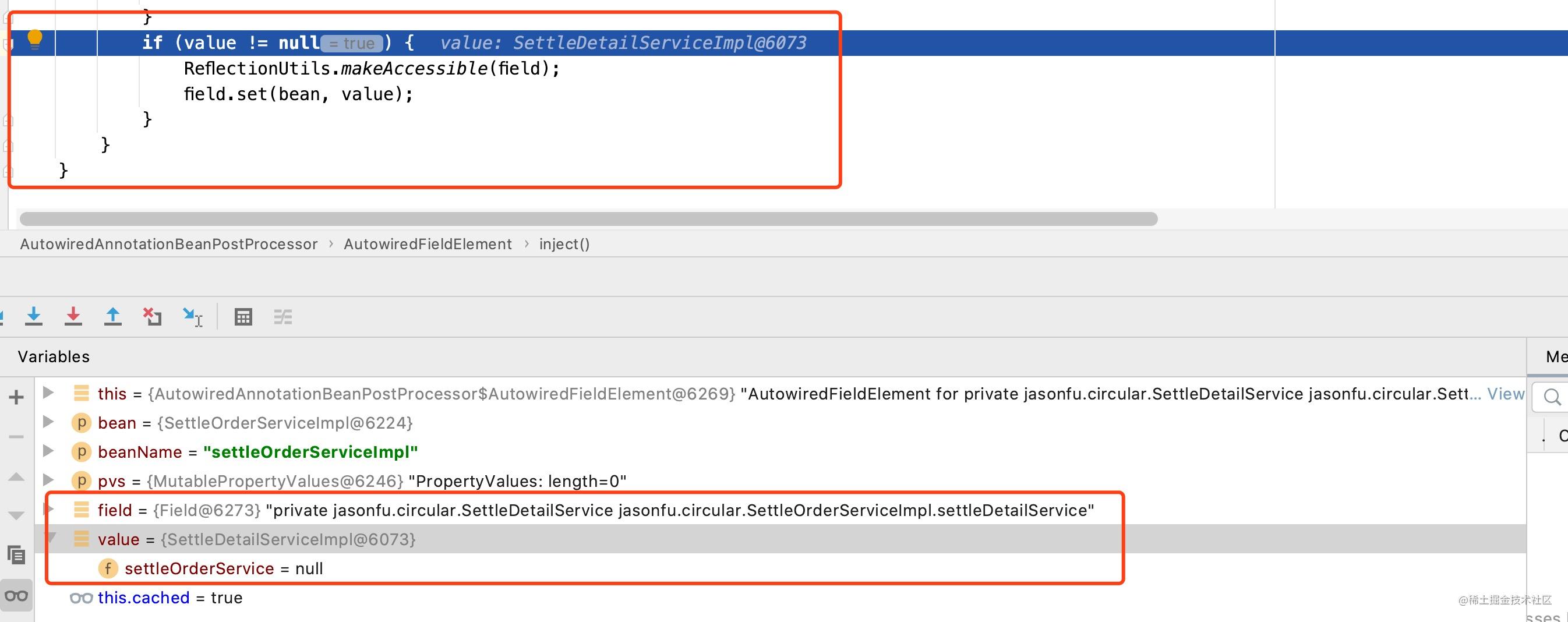
此刻settleOrderServiceImpl的SettleOrderService属性已经完成了赋值,此时一个完整的settleOrderServiceImpl对象也就被创建出来了;当SettleOrderServiceImpl对象完成了创建之后,也就能够完成一开始的对settleDetailServiceImpl的初始化了,如下图所示:
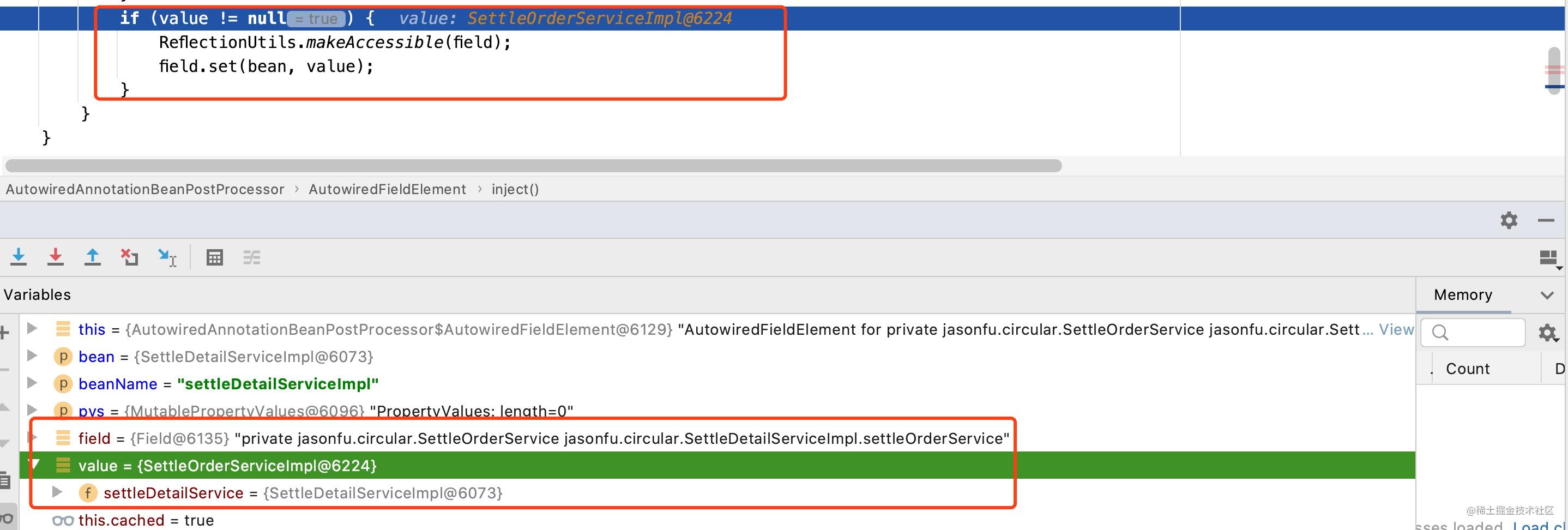
此时,框架对于settleOrderServiceImpl以及settleDetailServiceImpl两个循环依赖的创建已经完成了,其中有很多细节笔者未做详细解析,如框架何时将earlySingletonObjects中的对象清空等,感兴趣的小伙伴可以自行研究哈。
解决循环依赖步骤简述:
- 框架先实例化settleDetailServiceImpl对象,将settleDetailServiceImpl的工厂对象信息加入到singtonFactories中
- 在初始化settleDetailServiceImpl对象时,发现其依赖了settleOrderServiceImpl对象,框架会先创建settleOrderServiceImpl
- 在创建settleOrderServiceImpl对象时,先执行实例化,并将settleOrderServiceImpl的工厂对象加入到singletonFactories中
- 初始化settleOrderServiceImpl时发现其依赖了settleDetailServiceImpl对象,此时框架会尝试settleDetailServiceImpl
- signletonFactories中已经存在工厂对象信息,调用beanFactory#getObject方法创建settleDetailServiceImpl,并将创建好的settleSettleServiceImpl对象信息加入到earlySingletonFactories中,并移除singletonFactories中 settleDetailServiceImpl的工厂对象信息
- 将初始化完成后的settleDetailServiceImpl通过反射设置到settleOrderServiceImpl中,此时的settleOrderServiceImpl已经完成了实例化和初始化
- 框架通过反射将完整的settleOrderServiceImpl设置到settleDetailServiceImpl对象中去,此时settleDetailServiceImpl也完成了初始化
- settleDetailServiceImpl和settleOrderServiceImpl都完成了实例化和初始化,自此两个对象全部创建完成
上述的所有步骤,即为Spring框架对于循环依赖解决的方案,其中起到关键作用的就是singletonObjects、earlySingletonObjects、singletonFactories三个Map,到这里我们大概也就能够体会这个三个Map的作用,解答了我们文章开篇时对三个Map作用的疑惑。
反思:
通过上文的解析,大家或许对于循环的依赖的解决都或多或少有了一些自己的理解。笔者是由于需求的变动且在写代码的不严谨性,导致了循环依赖的产生,虽然框架提供了我们解决循环的方法,但是如果我们前期对需求有足够的理解或者设计的更加的合理的话,或许我们自己就可以避免这些问题的产生。