
一、详解JVM内存模型
JVM有本地方法栈、虚拟机栈、程序计数器、堆、方法区。
JVM内存分为共享区(可以被所有方法(线程)直接访问)和私有区(对线程来说是私有的,其他线程无法直接访问)。
在共享区里包含着堆和方法区,在私有区里包含着程序计数器、虚拟机栈和本地方法栈。
程序计数器PC:是一个行号计数器,程序在进行跳转时,我们要记住跳转的行号,它方便我们的程序进行还原。
虚拟机栈:包含了Java方法执行时的状态,每一个Java方法都会在虚拟机栈里面创建一个栈帧,里面存放局部变量表、操作数栈、动态链接、方法出口等。
本地方法栈:跟虚拟机栈类型,在用于调用操作系统的底层方法时才会创建栈帧。
堆:用来保存着Java程序运行时的变量,比如new的对象。
方法区:则保存着静态的东西,比如静态变量、常量、类的信息、方法的申明等。
二、JVM中一次完整的GC流程是怎样的
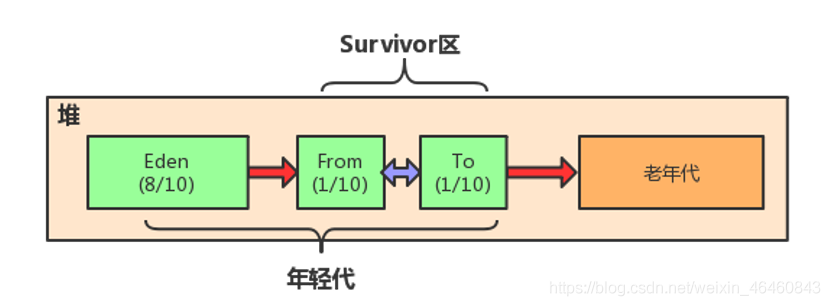
Java堆 = 老年代 + 新生代
新生代 = Eden + S0 + S1
当 Eden 区的空间满了, Java虚拟机会触发一次 Minor GC,以收集新生代的垃圾,存活下来的对象,则会转移到 Survivor区。
大对象(需要大量连续内存空间的Java对象,如那种很长的字符串)直接进入老年态;
如果对象在Eden出生,并经过第一次Minor GC后仍然存活,并且被Survivor容纳的话,年龄设为1,每熬过一次Minor GC,年龄+1,若年龄超过一定限制(15),则被晋升到老年态。即长期存活的对象进入老年态。
老年代满了而无法容纳更多的对象,Minor GC 之后通常就会进行Full GC,Full GC 清理整个内存堆 – 包括年轻代和老年代老年代。
Major GC 发生在老年代的GC,清理老年区,经常会伴随至少一次Minor GC,比Minor GC慢10倍以上。
三、GC垃圾回收的算法有哪些
引用计数算法
跟踪回收算法
压缩回收算法
复制回收算法
按代回收算法
浅析Java的垃圾回收机制(GC)和五种常用的垃圾回收算法
四、简单说说你了解的类加载器
类加载器 就是根据指定全限定名称将class文件加载到JVM内存,转为Class对象。
启动类加载器(Bootstrap ClassLoader):由C++语言实现(针对HotSpot),负责将存放在<JAVA_HOME>\lib目录或-Xbootclasspath参数指定的路径中的类库加载到内存中。
扩展类加载器(Extension ClassLoader):负责加载<JAVA_HOME>\lib\ext目录或java.ext.dirs系统变量指定的路径中的所有类库。
应用程序类加载器(Application ClassLoader): 负责加载用户类路径(classpath)上的指定类库,我们可以直接使用这个类加载器。一般情况,如果我们没有自定义类加载器默认就是用这个加载器。
五、双亲委派机制是什么,有什么好处,怎么打破
双亲委派机制:如果一个类加载器收到类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器完成。每个类加载器都是如此,只有当父加载器在自己的搜索范围内找不到指定的类时(即ClassNotFoundException),子加载器才会尝试自己去加载。
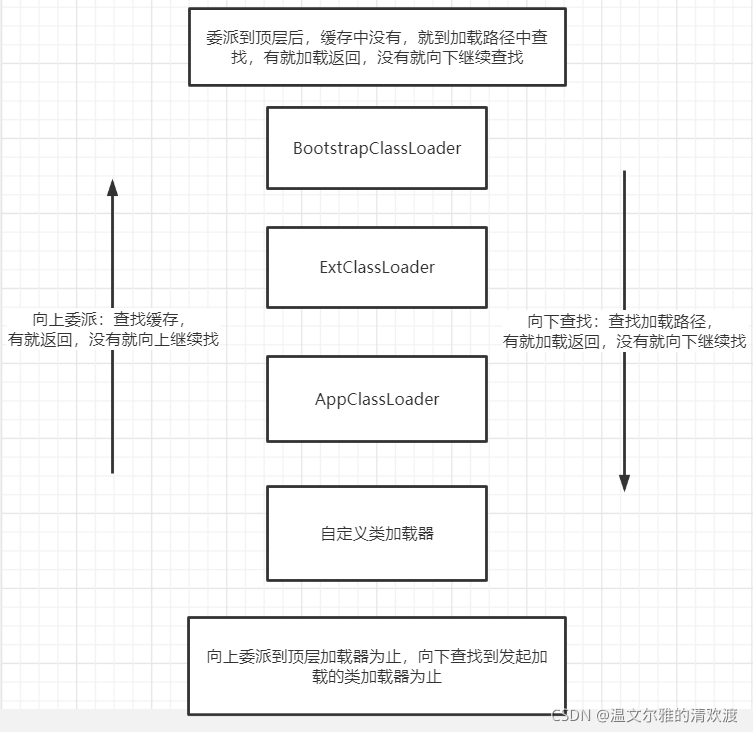
双亲委派模型的好处:
●主要是为了安全性,避免用户自己编写的类动态替换Java的一 些核心类,比如String。
●同时也避免了类的重复加载,因为JVM中区分不同类,不仅仅是根据类名,相同的class文件被不同的ClassLoader加载就是不同的两个类。
打破双亲委派机制则不仅要继承ClassLoader类,还要重写loadClass和findClass方法。
六、说说你JVM调优的几种主要的JVM参数
1)堆栈配置相关
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k
-XX:MaxPermSize=16m -XX:NewRatio=4 -XX:SurvivorRatio=4 -XX:MaxTenuringThreshold=0
-Xmx3550m: 最大堆大小为3550m。
-Xms3550m: 设置初始堆大小为3550m。
-Xmn2g: 设置年轻代大小为2g。
-Xss128k: 设置线程堆栈大小为128k。
-XX:MaxPermSize: 设置持久代大小为16m
-XX:NewRatio=4: 设置年轻代(包括Eden和两个Survivor区)与老年代的比值(除去持久代)。
-XX:SurvivorRatio=4: 设置年轻代中Eden区与Survivor区的大小比值。设置为4,则两个Survivor区与一个Eden区的比值为2:4,一个Survivor区占整个年轻代的1/6
-XX:MaxTenuringThreshold=0: 设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入老年代。
2)垃圾收集器相关
-XX:+UseParallelGC
-XX:ParallelGCThreads=20
-XX:+UseConcMarkSweepGC
-XX:CMSFullGCsBeforeCompaction=5
-XX:+UseCMSCompactAtFullCollection:
-XX:+UseParallelGC: 选择垃圾收集器为并行收集器。
-XX:ParallelGCThreads=20: 配置并行收集器的线程数
-XX:+UseConcMarkSweepGC: 设置老年代为并发收集。
-XX:CMSFullGCsBeforeCompaction:由于并发收集器不对内存空间进行压缩、整理,所以运行一段时间以后会产生“碎片”,使得运行效率降低。此值设置运行多少次GC以后对内存空间进行压缩、整理。
-XX:+UseCMSCompactAtFullCollection: 打开对老年代的压缩。可能会影响性能,但是可以消除碎片
3)辅助信息相关
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGC 输出形式:
[GC 118250K->113543K(130112K), 0.0094143 secs] [Full GC 121376K->10414K(130112K), 0.0650971 secs]
-XX:+PrintGCDetails 输出形式:
[GC [DefNew: 8614K->781K(9088K), 0.0123035 secs] 118250K->113543K(130112K), 0.0124633 secs] [GC [DefNew: 8614K->8614K(9088K), 0.0000665 secs][Tenured: 112761K->10414K(121024K), 0.0433488 secs] 121376K->10414K(130112K), 0.0436268 secs
七、JVM调优
1.将堆的最大、最小设置为相同的值,目的是防止垃圾收集器在最小、最大之间收缩堆而产生额外的时间。
-Xmx3550m: 最大堆大小为3550m。
-Xms3550m: 设置初始堆大小为3550m。
2.在配置较好的机器上(比如多核、大内存),可以为老年代选择并行收集算法: -XX:+UseParallelOldGC 。
3.年轻代和老年代将根据默认的比例(1:2)分配堆内存, 可以通过调整二者之间的比率来调整二者之间的大小,也可以针对回收代。
比如年轻代,通过 -XX:newSize -XX:MaxNewSize来设置其绝对大小。同样,为了防止年轻代的堆收缩,我们通常会把-XX:newSize -XX:MaxNewSize设置为同样大小。
4.年轻代和老年代设置多大才算合理
1)更大的年轻代必然导致更小的老年代,大的年轻代会延长普通GC的周期,但会增加每次GC的时间;小的老年代会导致更频繁的Full GC
2)更小的年轻代必然导致更大老年代,小的年轻代会导致普通GC很频繁,但每次的GC时间会更短;大的老年代会减少Full GC的频率
如何选择应该依赖应用程序对象生命周期的分布情况: 如果应用存在大量的临时对象,应该选择更大的年轻代;如果存在相对较多的持久对象,老年代应该适当增大。但很多应用都没有这样明显的特性。
在抉择时应该根 据以下两点:
(1)本着Full GC尽量少的原则,让老年代尽量缓存常用对象,JVM的默认比例1:2也是这个道理 。
(2)通过观察应用一段时间,看其他在峰值时老年代会占多少内存,在不影响Full GC的前提下,根据实际情况加大年轻代,比如可以把比例控制在1:1。但应该给老年代至少预留1/3的增长空间。
八、类加载的机制及过程
加载>>验证>>准备>>解析>>初始化
(1)加载:在硬盘上查找并通过I0读入字节码文件,在堆内存中生成一个对象,作为方法区数据的访问入口
(2)验证: 校验字节码文件的正确性
(3)准备:给类的静态变量分配内存,并赋予默认值
(4)解析(动态链接): 将静态方法的符号引用替换为直接引用(有对应的内存地址信息)
(5)初始化: 给类的静态变量初始化为指定的值,执行静态代码块
九、Jdk1.7到Jdk1.8 java虚拟机发⽣了什么变化?
1.7中存在永久代,1.8中没有永久代,替换它的是元空间,元空间所占的内存不是在虚拟机内部,⽽是本地 内存空间,这么做的原因是,不管是永久代还是元空间,他们都是⽅法区的具体实现,之所以元空间所占 的内存改成本地内存,官⽅的说法是为了和JRockit统⼀,不过额外还有⼀些原因,⽐如⽅法区所存储的类 信息通常是⽐较难确定的,所以对于⽅法区的⼤⼩是⽐较难指定的,太⼩了容易出现⽅法区溢出,太⼤了 ⼜会占⽤了太多虚拟机的内存空间,⽽转移到本地内存后则不会影响虚拟机所占⽤的内存。
十、你们项目如何排查JVM问题 ?
分两种情况
①对于还在正常运⾏的系统:
- 可以使⽤jmap来查看JVM中各个区域的使⽤情况;
- 可以通过jstack来查看线程的运⾏情况,⽐如哪些线程阻塞、是否出现了死锁;
- 可以通过jstat命令来查看垃圾回收的情况,特别是fullgc,如果发现fullgc⽐较频繁,那么就得进⾏调优了 ;
- 通过各个命令的结果,或者jvisualvm等⼯具来进⾏分析 ;
- ⾸先,初步猜测频繁发送fullgc的原因,如果频繁发⽣fullgc但是⼜⼀直没有出现内存溢出,那么表示 fullgc实际上是回收了很多对象了,所以这些对象最好能在younggc过程中就直接回收掉,避免这些对 象进⼊到⽼年代,对于这种情况,就要考虑这些存活时间不⻓的对象是不是⽐较大,导致年轻代放不 下,直接进⼊到了⽼年代,尝试加⼤年轻代的⼤⼩,如果改完之后,fullgc减少,则证明修改有效;
- 同时,还可以找到占⽤CPU最多的线程,定位到具体的⽅法,优化这个⽅法的执⾏,看是否能避免某些 对象的创建,从⽽节省内存 。
② 对于已经发⽣了OOM的系统:
1.⼀般⽣产系统中都会设置当系统发⽣了OOM时,⽣成当时的dump⽂件(- XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/base)
2. 我们可以利⽤jsisualvm等⼯具来分析dump⽂件
3. 根据dump⽂件找到异常的实例对象,和异常的线程(占⽤CPU⾼),定位到具体的代码
4. 然后再进⾏详细的分析和调试
十一、深拷贝和浅拷贝
深拷贝和浅拷贝就是指对象的拷贝,一个对象中存在两种类型的属性,一种是基本數据类型, 一种是实例对象的引用。
1.浅拷贝是指,只会拷贝基本数据类型的值,以及实例对象的引用地址,并不会复制一份引用地址所指向的对象, 也就是浅拷贝出来的对象,内部的类属性指向的是同一个对象
2深拷贝是指,既会拷贝基本数据类型的值,也会针对实例对象的引用地址所指向的对象进行复制,深拷贝出来的对象,内部的类执行指向的不是同一个对象
十二、说⼀下JVM中,哪些可以作为GC root
首先,GC root是根对象,JVM在进⾏垃圾回收时,需要找到“垃圾”对象,也就是没有被引⽤的对象,但是直接找“垃圾”对象是⽐较耗时的,所以反过来,先找“⾮垃圾”对象,也就是正常对象,那么就需要从某些“根”开始去找,根据这些“根”的引⽤路径找到正常对象,⽽这些“根”有⼀个特征,就是它只会引⽤其他对象,⽽不会被其他对象引⽤,例如:栈中的本地变量、⽅法区中的静态变量、本地⽅法栈中的变量、正在运⾏的线程等可以作为GC root。
十三、JVM诊断工具有哪些?
阿里的Arthas
JDK自带JVM诊断工具:JAVA VisualVM
Full GC把整个堆都回收
OOM:内存溢出 Out of Memory Error
十四、为什么要使用STW?
STW:stop the word JAVA进行GC时会停止用户线程,对用户体验很不好
反证法,如果没有STW,用户线程将一直执行。
GC要进行垃圾回收,就要找所有垃圾和非垃圾,先找GC root,然后找引用对象。因为程序会在GC的过程中一直在执行,然后结束了,结束之后内存空间都被释放了,栈帧弹出,GC root已经没了,之前找的非垃圾已经全变成垃圾了。