Netty提供了ByteBuf缓冲区组件来替代Java NIO的ByteBuffer缓冲区组件,以便更加快捷和高效地操纵内存缓冲区。
1 ByteBuf的优势
与Java NIO的ByteBuffer相比,ByteBuf的优势如下:
- Pooling(池化),减少了内存复制和GC,提升了效率。
- 复合缓冲区类型,支持零复制。
- 不需要调用flip()方法去切换读/写模式。
- 可扩展性好。
- 可以自定义缓冲区类型。
- 读取和写入索引分开。
- 方法的链式调用。
- 可以进行引用计数,方便重复使用。
2 ByteBuf的组成部分
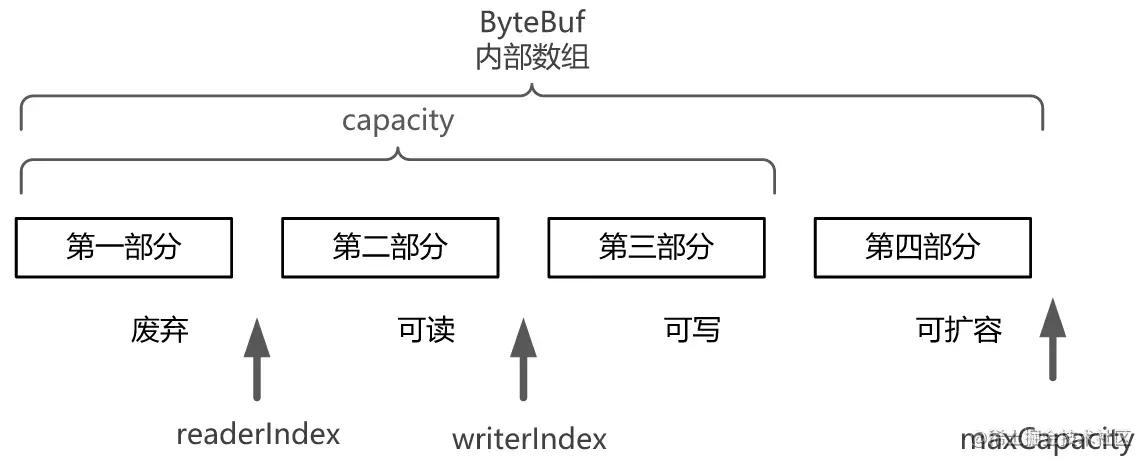
ByteBuf是一个字节容器,内部是一个字节数组。从逻辑上来分,字节容器内部可以分为四个部分
- 第一部分是已用字节,表示已经使用完的废弃的无效字节;
- 第二部分是可读字节,这部分数据是ByteBuf保存的有效数据,从ByteBuf中读取的数据都来自这一部分;
- 第三部分是可写字节,写入ByteBuf的数据都会写到这一部分中;
- 第四部分是可扩容字节,表示的是该ByteBuf最多还能扩容的大小。
3 ByteBuf的重要属性
ByteBuf通过三个整数类型的属性有效地区分可读数据和可写数据的索引,使得读写之间相互没有冲突。这三个属性定义在AbstractByteBuf抽象类中
- readerIndex(读指针):指示读取的起始位置。每读取一个字节,readerIndex自动增加1。 一旦readerIndex与writerIndex相等,则表示ByteBuf不可读了。
- writerIndex(写指针):指示写入的起始位置。每写一个字节,writerIndex自动增加1。 一旦增加到writerIndex与capacity()容量相等,则表示ByteBuf不可写了。 注意,capacity()是一个成员方法,不是一个成员属性,表示ByteBuf中可以写入的容量,而且它的值不一定是最大容量值。
- maxCapacity(最大容量):表示ByteBuf可以扩容的最大容量。当向ByteBuf写数据的时候,如果容量不足,可以进行扩容。扩容的最大限度由maxCapacity来设定,超过maxCapacity就会报错。
4 ByteBuf的API
4.1 容量操作
- capacity():表示ByteBuf的容量,是 废弃的字节数、可读字节数和可写字节数之和 。
- maxCapacity():表示ByteBuf能够容纳的最大字节数。当向ByteBuf中写数据的时候,如果发现容量不足,则进行扩容,直至扩容到maxCapacity设定的上限。
4.2 数据写入相关API
- isWritable(): 表示ByteBuf是否可写。如果capacity()容量大于writerIndex指针的位置,则表示可写,否则为不可写 。注意:isWritable()返回false并不代表不能再往ByteBuf中写数据了。如果Netty发现往ByteBuf中写数据写不进去,就会自动扩容ByteBuf。
- writableBytes():取得可写入的字节数,它的值等于容量capacity()减去writerIndex。
- maxWritableBytes():取得最大的可写字节数,它的值等于最大容量maxCapacity减去writerIndex。
- writeBytes(byte[] src):把入参src字节数组中的数据全部写到ByteBuf。这是最为常用的一个方法。
- writeTYPE(TYPE value):写入基础数据类型的数据。TYPE表示基础数据类型,这里包含了八种大基础数据类型:writeByte()、writeBoolean()、writeChar()、writeShort()、writeInt()、writeLong()、writeFloat()、writeDouble()。
- setTYPE(TYPE value):基础数据类型的设置,不改变writerIndex指针值。TYPE表示基础数据类型这里包含了八大基础数据类型的设置,即setByte()、setBoolean()、setChar()、setShort()、setInt()、setLong()、setFloat()、setDouble()。setTYPE系列与writeTYPE系列的不同点是setTYPE系列不改变写指针writerIndex的值,writeTYPE系列会改变写指针writerIndex的值。
- markWriterIndex()与resetWriterIndex():前一个方法表示把当前的写指针writerIndex属性的值保存在markedWriterIndex标记属性中;后一个方法表示把之前保存的markedWriterIndex的值恢复到写指针writerIndex属性中。这两个方法都用到了标记属性markedWriterIndex,相当于一个写指针的暂存属性。
4.3 数据读取相关API
- isReadable():返回ByteBuf是否可读。如果writerIndex指针的值大于readerIndex指针的值,则表示可读,否则为不可读。
- readableBytes():返回表示ByteBuf当前可读取的字节数,它的值等于writerIndex减去readerIndex。
- readBytes(byte[] dst):将数据从ByteBuf读取到dst目标字节数组中,这里dst字节数组的大小通常等于readableBytes()可读字节数。这个方法也是最为常用的方法之一。
- readTYPE():读取基础数据类型。可以读取八大基础数据类型:readByte()、readBoolean()、readChar()、readShort()、readInt()、readLong()、readFloat()、readDouble()。
- getTYPE():读取基础数据类型,并且不改变readerIndex读指针的值,具体为getByte()、getBoolean()、getChar()、getShort()、getInt()、getLong()、getFloat()、getDouble()。getTYPE系列
- markReaderIndex()与resetReaderIndex():前一种方法表示把当前的读指针readerIndex保存在markedReaderIndex属性中;后一种方法表示把保存在markedReaderIndex属性的值恢复到读指针readerIndex中。markedReaderIndex属性定义在AbstractByteBuf抽象基类中,是一个标记属性,相当于一个读指针的暂存属性。
5 使用Demo
package study.wyy.netty.bytebuf;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
public class WriteReadTest {
public static void main(String[] args) {
// 使用默认的分配器分配了一个初始容量为9、最大限制为100个字节的缓冲区
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(9, 100);
System.out.println(buffer);
// 写入数据
buffer.writeBytes(new byte[]{1, 2, 3, 4});
System.out.println("写入4个字节结束");
// 测试获取,不改变指针位置
for (int i = 0; i < buffer.readableBytes(); i++) {
System.out.println(buffer.getByte(i));
}
System.out.println("====================");
// 测试读取数据
while (buffer.isReadable()) {
System.out.println(buffer.readByte());
}
}
}
6 ByteBuf的引用计数
JVM中使用“计数器”(一种GC算法)来标记对象是否“不可达”进而收回,Netty也使用了这种手段来对ByteBuf的引用进行计数。(注:GC是Garbage Collection的缩写,即Java中的垃圾回收机制。)Netty的ByteBuf的内存回收工作是通过引用计数方式管理的。
Netty之所以采用“计数器”来追踪ByteBuf的生命周期:
- 一是能对Pooled ByteBuf进行支持
- 二是能够尽快“发现”那些可以回收的ByteBuf(非Pooled),以便提升ByteBuf的分配和销毁的效率。
什么是池化(Pooled)的ByteBuf缓冲区呢?从Netty 4版本开始,新增了ByteBuf的池化机制,即创建一个缓冲区对象池,将没有被引用的ByteBuf对象放入对象缓存池中,需要时重新从对象缓存池中取出,而不需要重新创建。
ByteBuf引用计数的大致规则如下:
- 在默认情况下,当创建完一个ByteBuf时,引用计数为1;
- 每次调用retain()方法,引用计数加1;
- 每次调用release()方法,引用计数减1;
- 如果引用为0,再次访问这个ByteBuf对象,将会抛出异常;
- 如果引用为0,表示这个ByteBuf没有哪个进程引用,它占用的内存需要回收。
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
public class RefTest {
public static void main(String[] args) {
// 创建buffer
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(9, 100);
System.out.println("创建时引用的数:" + buffer.refCnt());
// 调用retain, 就会增加一次
buffer.retain();
System.out.println("调用retain之后引用数:" + buffer.refCnt());
// 调用release, 就会减少一次
buffer.release();
System.out.println("调用release之后引用数:" + buffer.refCnt());
// 调用release, 就会减少一次
buffer.release();
System.out.println("再次调用release之后引用数:" + buffer.refCnt());
//错误:refCnt: 0,不能再retain
buffer.retain();
}
}
测试输出:
创建时引用的数:1
调用retain之后引用数:2
调用release之后引用数:1
再次调用release之后引用数:0
Exception in thread "main" io.netty.util.IllegalReferenceCountException: refCnt: 0, increment: 1
最后一次retain()方法抛出了IllegalReferenceCountException异常。原因是:在此之前,缓冲区buffer的引用计数已经为0,不能再retain了。也就是说:在Netty中,引用计数为0的缓冲区不能再继续使用。
为了确保引用计数不会混乱,在Netty的业务处理器开发过程中应该坚持一个原则:retain()和release()方法应该结对使用。对缓冲区调用了一次retain(),就应该调用一次release():
public void handlMethodA(ByteBuf byteBuf) {
byteBuf.retain();
try {
// do something....
handlMethodB(byteBuf);
} finally {
byteBuf.release();
}
}
如果retain()和release()这两个方法一次都不调用: Netty在缓冲区使用完成后会调用一次release(),就是释放一次。例如,在Netty流水线上,中间所有的业务处理器处理完ByteBuf之后会直接传递给下一个,由最后一个Handler负责调用其release()方法来释放缓冲区的内存空间。
当ByteBuf的引用计数已经为0时,Netty会进行ByteBuf的回收,分为以下两种场景:
- 如果属于池化的ByteBuf内存,回收方法是:放入可以重新分配的ByteBuf池,等待下一次分配。
- 如果属于未池化的ByteBuf缓冲区,需要细分为两种情况:如果是堆(Heap)结构缓冲,会被JVM的垃圾回收机制回收;如果是直接(Direct)内存类型,则会调用本地方法释放外部内存(unsafe.freeMemory)。
除了通过ByteBuf成员方法retain()和release()管理引用计数之外,Netty还提供了一组用于增加和减少引用计数的通用静态方法:
- ReferenceCountUtil.retain(Object):增加一次缓冲区引用计数的静态方法,从而防止该缓冲区被释放。
- ReferenceCountUtil.release(Object):减少一次缓冲区引用计数的静态方法,如果引用计数为0,缓冲区将被释放。
7 ByteBuf的分配器
Netty通过ByteBufAllocator分配器来创建缓冲区和分配内存空间。Netty提供了两种分配器实现: PoolByteBufAllocator 和 UnpooledByteBufAllocator
- PoolByteBufAllocator(池化的ByteBuf分配器)将ByteBuf实例放入池中,提高了性能,将内存碎片减少到最小;池化分配器采用了jemalloc高效内存分配的策略,该策略被好几种现代操作系统所采用。
- UnpooledByteBufAllocator是普通的未池化ByteBuf分配器,没有把ByteBuf放入池中,每次被调用时,返回一个新的ByteBuf实例;使用完之后,通过Java的垃圾回收机制回收或者直接释放(对于直接内存而言)。
在Netty中,默认的分配器为ByteBufAllocator.DEFAULT。该默认的分配器可以通过系统参数(System Property)选项io.netty.allocator.type进行配置,配置时使用字符串值:"unpooled","pooled"。
不同的Netty版本,对于分配器的默认使用策略是不一样的。
- 在Netty 4.0版本中,默认的分配器为UnpooledByteBufAllocator(非池化内存分配器)。
- 在Netty 4.1版本中,默认的分配器为PooledByteBufAllocator(池化内存分配器) 初始化代码在ByteBufUtil类中的静态代码中:
// /Android系统默认为unpooled,其他系统默认为pooled
// 除非通过系统属性io.netty.allocator.type 做专门配置
String allocType = SystemPropertyUtil.get(
"io.netty.allocator.type", PlatformDependent.isAndroid() ? "unpooled" : "pooled");
allocType = allocType.toLowerCase(Locale.US).trim();
在PooledByteBufAllocator已经广泛使用了一段时间,并且有了增强的缓冲区泄漏追踪机制。因此,也可以在Netty程序中设置引导类Bootstrap装配的时候将PooledByteBufAllocator设置为默认的:
ServerBootstrap b = new ServerBootstrap()
//设置通道的参数
b.option(ChannelOption.SO_KEEPALIVE, true);
//设置父通道的缓冲区分配器
b.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
//设置子通道的缓冲区分配器
b.childOption(ChannelOption.ALLOCATOR,PooledByteBufAllocator.DEFAULT);
使用缓冲区分配器创建ByteBuf的方法有多种,下面列出几种主要的:
public static void initBuffer(String[] args) {
ByteBuf buffer = null;
// 方式一:通过默认分配器
// 初始化一个初始容量为9、最大容量为100的缓冲区
buffer = ByteBufAllocator.DEFAULT.buffer(9, 100);
// 方法2:通过默认分配器分配
// 初始容量为256、最大容量为Integer.MAX_VALUE的缓冲区
buffer = ByteBufAllocator.DEFAULT.buffer();
//方法3:非池化分配器,分配Java的堆(Heap)结构内存缓冲区
buffer = UnpooledByteBufAllocator.DEFAULT.heapBuffer();
//方法4:池化分配器,分配由操作系统管理的直接内存缓冲区
buffer = PooledByteBufAllocator.DEFAULT.directBuffer();
}
8 ByteBuf缓冲区的类型
根据内存的管理方不同,缓冲区分为堆缓冲区和直接缓冲区,也就是Heap ByteBuf和Direct ByteBuf。另外,为了方便缓冲区进行组合,还提供了一种组合缓存区(composite ByteBuf)。
| 类型 | 说明 | 优点 | 不足 |
|---|---|---|---|
| HeapByteBuf | 内部数据为一个数组,存在jvm堆空间,可以通过hasArray方法判断是不是堆缓冲区 | 未采用池化情况下,可以提供快速的分配和释放 | 写入底层传输通道前,都会复制到直接缓冲区 |
| DirectByteBuf | 内部数据存储在操作系统的物理内存中 | 能获取超过jvm堆限制的大小的内存空间,写入比堆缓冲区更快 | 释放和分配空间昂贵(使用了操作系统的方法),在java中读取数据时,需要复制到堆上 |
| compositeByteBuf | 多个缓冲区的组合表示 | 方便一次操作多个缓冲区实例 |
上面三种缓冲区都可以通过池化(Pooled)、非池化(Unpooled)两种分配器来创建和分配内存空间。
直接内存
-
Direct Memory不属于Java堆内存,所分配的内存其实是调用操作系统malloc()函数来获得的,由Netty的本地Native堆进行管理。
-
Direct Memory容量可通过-XX:MaxDirectMemorySize来指定,如果不指定,则默认与Java堆的最大值(-Xmx指定)一样。注意:并不是强制要求,有的JVM默认Direct Memory与-Xmx值无直接关系。
-
Direct Memory的使用避免了Java堆和Native堆之间来回复制数据。在某些应用场景中提高了性能。
-
在需要频繁创建缓冲区的场合,由于创建和销毁Direct Buffer(直接缓冲区)的代价比较高昂,因此不宜使用Direct Buffer。也就是说,Direct Buffer尽量在池化分配器中分配和回收。如果能将Direct Buffer进行复用,在读写频繁的情况下就可以大幅度改善性能。
-
对Direct Buffer的读写比Heap Buffer快,但是它的创建和销毁比普通Heap Buffer慢。
-
在Java的垃圾回收机制回收Java堆时,Netty框架也会释放不再使用的Direct Buffer缓冲区,因为它的内存为堆外内存,所以清理的工作不会为Java虚拟机(JVM)带来压力。注意一下垃圾回收的应用场景:
- 垃圾回收仅在Java堆被填满,以至于无法为新的堆分配请求提供服务时发生;
- 在Java应用程序中调用System.gc()函数来释放内存。
Heap ByteBuf和Direct ByteBuf的使用上的不同
- Heap ByteBuf通过调用分配器的buffer()方法来创建;Direct ByteBuf通过调用分配器的directBuffer()方法来创建。
- Heap ByteBuf缓冲区可以直接通过array()方法读取内部数组;Direct ByteBuf缓冲区不能读取内部数组。
- 可以调用hasArray()方法来判断是否为Heap ByteBuf类型的缓冲区;如果hasArray()返回值为true,则表示是堆缓冲,否则为直接内存缓冲区。
- 从Direct ByteBuf读取缓冲数据进行Java程序处理时,相对比较麻烦,需要通过getBytes/readBytes等方法先将数据复制到Java的堆内存,然后进行其他的计算。