(本文参考书籍netty in action编写)
什么是ByteBuf
说到网络编程,大家都知道,网络数据的基本单位总是字节。ByteBuf就是一个由netty实现的字节容器,英文全称应该是ByteBuffer(字节缓冲区)。
那么为什么不叫ByteBuffer呢?这自然是因为java nio包中,提供了同样功能的东西就叫ByteBuffer,所以自己实现的当然不能和官方的重名啦。但是官方实现的ByteBuffer使用起来过于复杂繁琐,因此netty就提供了自己的实现。
ByteBuf的工作原理
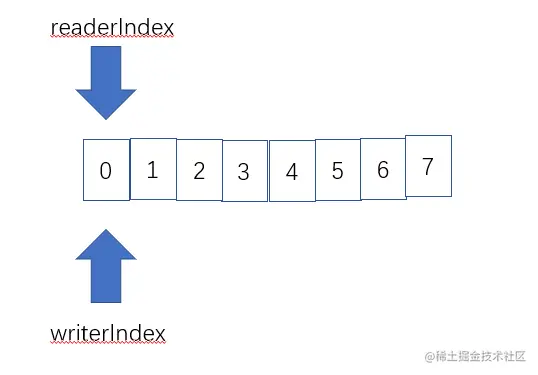
(如图就是一个8个字节大小的ByteBuf简易图,请忽略我对不齐的边框)
ByteBuf维护了两个不同的索引,就是rederIndex和writerIndex。一个用于读取,一个用于写入。 当你读取的时候readerIndex会自动递增你读取的字节数。同样,当你写入时,writerBuffer也会递增你写入的字节数。这两个索引默认都为0(如上图)。
我们看看源码就会发现 源码中有一堆read开头的方法和write开头的方法,其中大部分的read开头的方法都会使rederIndex递增,write开头的方法都会使writerIndex递增。
然后也还有很多get或者set开头的方法。他们一般不会递增索引,而是直接对他们做操作。我们还可以给ByteBuf设置一个初始的容量,如果超出了容量的操作就会抛出异常。
那么他们是怎么被使用的呢
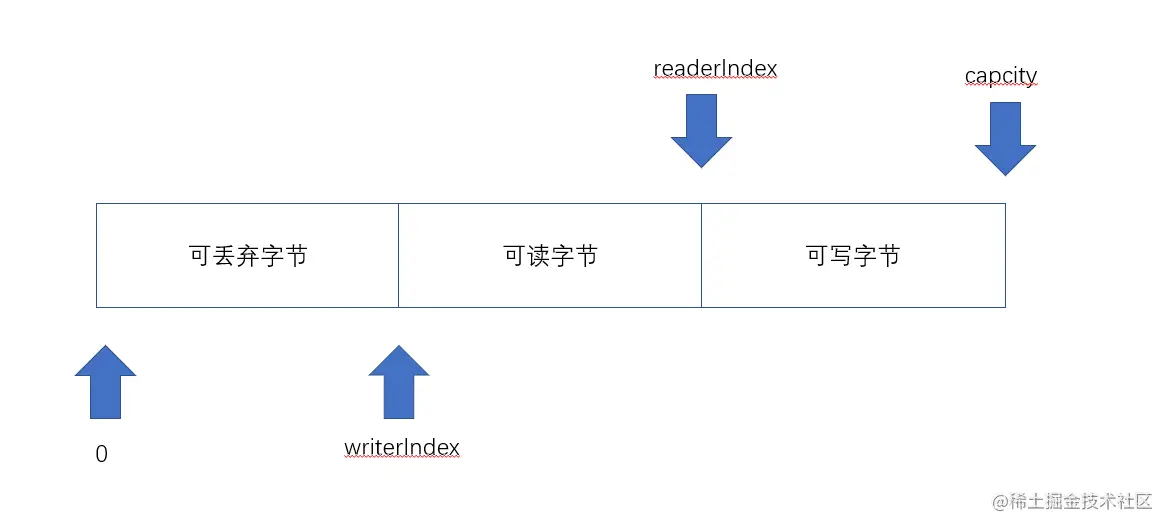
如果学过java nio中的ByteBuffer,大家一定知道:他有两种模式:读模式和写模式,如果切换模式还得调用flip()函数。这是因为他内部其实只维护了一个索引。而netty中的ByteBuf维护了两个索引,自然就不需要flip函数了。
书归正题,一般情况下,一个被使用的ByteBuf的两个索引会如图这样分布(也就是writerIndex在后,readerIndex在前)。这样可把整个ByteBuf分成三个模块:可废弃字节(0和readerIndex之间),可读字节(readerIndex和writerIndex之间),可写字节(writerIndex之后)
可丢弃字节
其实他们就是以及读过的字节。所以自然是可以丢弃的(当然也有可能会重复读取之前读过的导致不能丢弃,这得看具体业务需求)
通过调用discardReadBytes()方法可以丢弃他们并且回收空间,把这些内存变为可写的。如下:
AbstractByteBuf类的实现
@Override
public ByteBuf discardReadBytes() {
//如果readerIndex是0 那不需要任何处理
if (readerIndex == 0) {
// 判断是否可访问
ensureAccessible();
return this;
}
//正常情况都会不相等
if (readerIndex != writerIndex) {
//把可读区域整体移到从0开始的地方
setBytes(0, this, readerIndex, writerIndex - readerIndex);
//修改一下index
writerIndex -= readerIndex;
adjustMarkers(readerIndex);
readerIndex = 0;
} else {
//读写相等 那只要改索引
ensureAccessible();
adjustMarkers(readerIndex);
writerIndex = readerIndex = 0;
}
return this;
}

虽然这个方法看上去很美好,但是实际上会导致大量的内存复制(就是上面代码中的setBytes方法)。而且这并不会确保可写分段的内容都被擦除了(不过没关系,反正接着写会覆盖他们)。
总之,一般来说,只有当内存非常宝贵的时候,才推荐使用这种方法。一般情况不推荐使用。他的代替方法是clear()
@Override
public ByteBuf clear() {
readerIndex = writerIndex = 0;
return this;
}
这个方法非常轻量级,仅仅是改变了索引,把所有区域都置为可写区域,并不会清除缓存中的内容,也不会导致内存复制。所以一般更推荐在合适的时候使用这个方法而不是discardReadBytes().
可读字节
可读字节就是写过但是还没读的数据。以read开头的方法都会读取当前readerIndex位置的字节,而以skip开头的一般都会跳过当前readerIndex位置的字节。两者都会改变当前的readerIndex的位置。
最常见的使用是readByte() 会读取当前字节。如果此时可读字节为0,则会报错。
下面是一个常见的使用方法:读取所有可读的字节。
while (buf.isReadable()){
System.out.println(buf.readByte());
}
其中isReadable()方法所返回的就是0,和writerIndex-readerIndex 中的较大值。
可写字节
可写分段指的是一个有未定义内容的,写入就绪的内存区域。以write开头的方法都会从当前writerIndex开始写数据,并将它增加已经写入的字节数。如果写操作的目标是ByteBuf,并且没有指定源索引的值,那么默认是从他的rederIndex开始写,所以源索引区的readerIndex也同样会增加相同的大小。这个调用如下:
writerBytes(ByteBuf dest);
如果写入超过容量的数据,则会报错。
如下是一个用随机整数值填充ByteBuf,直到它空间不足的例子。writeableBytes()方法在这里被采用来确定该缓冲区中是否还有足够的空间,它将返回等于(this.capacity(代表容量,后文还有讲到) - this.writerIndex)的可写字节数。
while (buf.writableBytes() >= 4){
buf.writeInt(random.nextInt());
}
ByteBuf的操作
随机访问索引和顺序访问索引
在ByteBuf的实现类中,有的在字段里加了一个byte数组 有的则是一个int类型的字段,叫length。
无论如何,他们的其中一个作用就是实现获取到最后一个字节的索引。最后一个字节的索引一定是byte数组的length-1或者他维护的那个length-1。为了方便调用,ByteBuf有一个方法可以快速获得这个值,那就是capacity()
PooledByteBuf<T>类的实现
protected int length;
@Override
public final int capacity() {
return length;
}
UnpooledHeapByteBuf类中
byte[] array;
@Override
public int capacity() {
return array.length;
}
(还有更多种实现我就不一一列举了)
有了这个capcity()方法,我们就能很简单的实现随机访问索引。 比如说我想遍历每一个值,使用如下方式即可。
for (int i = 0;i<buf.capacity();i++){
char b = (char)buf.getByte(i);
System.out.println(b);
}
索引管理
作为一款强大的字节容器,我们肯定不能只靠read或者write方法来移动两个索引。肯定还有其他更自由的方法。
在JDK的InputStream中定义了mark(int readlimit)和reset()方法,这些方法分别被用来将流中的当前位置标记为指定的值,以及将流重置到该位置。
同样,我们可以调用markReaderInex()、markWriterIndex()、resetWriterIndex()和resetReaderIndex()来标记和重置ByteBuf的readerIndex和writerIndex。和InputStream的使用类似,只不过没有readLimit参数来指定标记什么时候失效。
当然,我们还可以调用readerIndex(int),或者writerIndex(int)来让索引移动到指定位置。但是试图将他们移动到非法的位置都会报错。
学到这里,我们就可以顺便讲一下之前说的discardReadBytes()方法不能保证擦除写是啥意思了。
public static void main(String[] args) {
ByteBuf buf = Unpooled.copiedBuffer("abcdef", CharsetUtil.UTF_8);
System.out.println("当前可读区 " + buf.readableBytes());
System.out.println("当前可写区" + buf.writableBytes());
buf.readBytes(4);
System.out.println("-------读4个字节之后-----------------");
System.out.println("当前可读区 " + buf.readableBytes());
System.out.println("当前可写区" + buf.writableBytes());
System.out.println("-------执行discardReadBytes()之后-----------------");
buf.discardReadBytes();
System.out.println("当前可读区 " + buf.readableBytes());
System.out.println("当前可写区" + buf.writableBytes());
System.out.println("-------此时若是移动读索引,就可能读到之前没清空的数据-----------------");
//读索引移动后如果比写索引大了,那就回报错,所以要先移动写索引
buf.writerIndex(4);
buf.readerIndex(3);
System.out.println("当前字节(本该在被删除但其实没有):"+(char)buf.readByte());
System.out.println("当前可读区 " + buf.readableBytes());
System.out.println("当前可写区" + buf.writableBytes());
}
当前可读区 6
当前可写区58
-------读4个字节之后-----------------
当前可读区 2
当前可写区58
-------执行discardReadBytes()之后-----------------
当前可读区 2
当前可写区62
-------此时若是移动读索引,就可能读到之前没清空的数据-----------------
当前字节(本该在被删除但其实没有):d
当前可读区 0
当前可写区60
这样就读到了之前读过,应该被舍弃的数据。
查找操作
如果是想通过值找索引的话,ByteBuf有比较简单的方法可以实现:就是indexOf()。他的使用也就和其他的容器一样---给定一个值返回他的索引,这没什么好说的。 下面是一个例子:
ByteBuf buf = Unpooled.copiedBuffer("abcdef", CharsetUtil.UTF_8);
System.out.println("b的位置是:" + buf.indexOf(0, buf.capacity(), (byte) 'b'));
但是如果想查一些更复杂的,那就需要一个ByteProcessor类型的对象作为参数的方法了。
假如说我想查找一个回车字符。我们应该如下这么做。
int index = buf.forEachByte(ByteProcessor.FIND_CR);
ByteProcessor类封装了很多常见的值,用起来很方便。而forEachByte方法也是遍历,不过比在循环里一次一次read更快,因为减少了许多次的边界检查。
派生缓冲区
有时候,我们可能需要获取缓冲区的复制,或者切片。netty中自然也提供了对应的方法。 如:slice(int,int).Unpolled.unmodifiableBuffer(...),order(ByteOrder),readSlice(int)等。
这些方法都返回一个ByteBuf实例,它具有自己的读索引,写索引和表及索引,内存也是共享的。这使得创建这种派生缓冲区成本很低廉。但也意味着,如果你改了派生缓冲区的值,源缓冲区也会被修改。所以要多加小心。
如果需要一个缓冲区的真实副本,应该使用copy()方法 ,这会返回一个独立的ByteBuf实例。
下面展示了如何对缓冲区进行切片并且操作。
public static void main(String[] args) {
//创建一个缓冲区
ByteBuf buf = Unpooled.copiedBuffer("abcdef", CharsetUtil.UTF_8);
//对其索引0到2进行切片
ByteBuf slice = buf.slice(0, 2);
System.out.println("slice的内容:"+slice.toString(CharsetUtil.UTF_8));
buf.setByte(0,'g');
System.out.println("操作后slice的内容:"+slice.toString(CharsetUtil.UTF_8));
}
slice的内容:ab
操作后slice的内容:gb
如果使用copy方法则不会改变切片的内容。
读写操作
其实讲到这里,大家对读写操作也能有大致的印象了。还没讲到的无非也就是一些 setInt getInt readInt writeInt之类的,大家看看函数名就能大概知道怎么用了。
其他操作
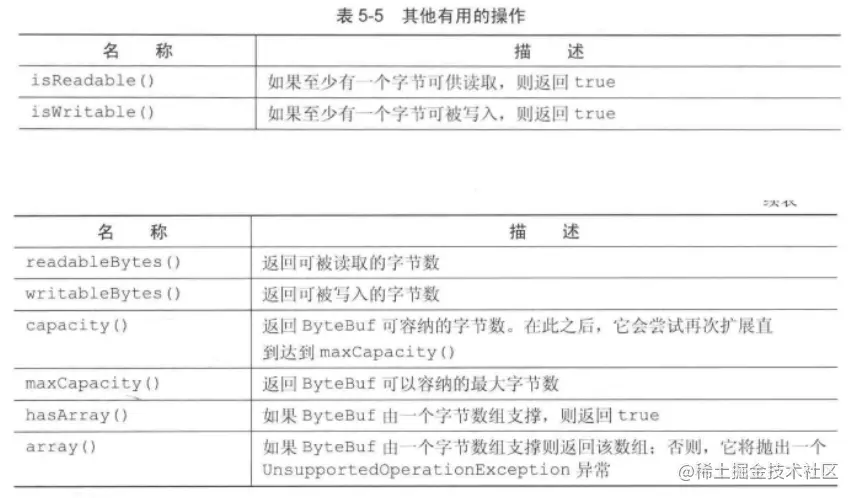 大家看图就好啦
大家看图就好啦
重要接口-ByteBufHolder接口
一般来说,真正的数据负载一般都应该不止是一个ByteBuf。比如HTTP响应,除了表示字节的内容,还应该有状态码,cookie等信息。
为了保存这些东西,Netty提供了ByteBufHolder接口。
public interface ByteBufHolder extends ReferenceCounted {
/**
* 返回持有的ByteBuf
*/
ByteBuf content();
/**
* 创建一个新的ByteBufHolder副本,和源副本无关系
*/
ByteBufHolder copy();
/**
* 创建一个新的ByteBufHolder副本,和源副本有关系
*/
ByteBufHolder duplicate();
...
}
关于ReferenceCounted的讲解会在后面进行。
如果想要实现一个将其有效负载存储在ByteBuf中的消息对象,那么这个接口将是一个很好的选择。
ByteBuf的分配
ByteBuf有三种内存分配模式:
1.堆缓冲区
最常用的模式就是把它分配在jvm堆中,这种方式也叫支撑数组(backing array),它能在没有使用池化的情况下快速的分配和释放。 通过ByteBuf的hasArray方法就可以判断是不是这种形式。
2.直接缓冲区
如果选择使用直接缓冲区,那么有好处也有坏处。直接缓冲区的内容将驻留在常规的会被垃圾回收的堆之外。这也解释了为什么这种方式比较适合作为网络数据传输,因为这能避免每次调用本地io操作之前或者之后,将缓冲区的内容复制到一个中间缓冲区(如果是之后的话就是从中间缓冲区复制回来)。如果在堆里,那就一定要这么来回复制了。
但是直接缓冲区缺点也很明显,相对于堆来说,他的释放和分配都很昂贵,如果处理遗留代码,还会遇到另一个问题,就是数据不在对堆上,你可能得在进行一次复制,才能使用。
所以一般来说,事先知道容器中的数据会被像数组一样访问的话,还是使用堆内存比较好。
如下是两种方法的使用区别:
public static void main(String[] args) {
//创建一个缓冲区
ByteBuf buf = Unpooled.copiedBuffer("abcdef", CharsetUtil.UTF_8);
System.out.println(buf.hasArray());
if(buf.hasArray()){
//在堆内,直接获取支撑数组
byte[] array = buf.array();
//获取第一个字节的偏移量 其实arrayOfSet的大部分实现都是return 0(不return 0的情况我还没想到,或许是用循环数组作为支撑数组)
int offset = buf.arrayOffset() + buf.readerIndex();
int length = buf.readableBytes();
doSomething(array,offset,length);
}
else {
int length = buf.readableBytes();
//在堆外,得创建数组
byte[] array = new byte[length];
buf.getBytes(buf.readerIndex(),array);
doSomething(array,0,length);
}
3.复合缓冲区
复合缓冲区就是混用上述的两种。
原生的JDK中,想实现这种方式很复杂。但是netty提供了一个ByteBuf子类,叫CompositeByteBuf来实现这个功能,这个类如果混合使用了多种内存分配方式,他的hasArray方法会返回false,如果只有单种,则会返回对应的hasArray方法。
那么如何使用呢:
public static void main(String[] args) {
//创建一个CompositeByteBuf
CompositeByteBuf byteBufs = Unpooled.compositeBuffer();
//随便创建两个buffer 在直接内存还是堆内存都行
ByteBuf buf1 = Unpooled.copiedBuffer("123456", CharsetUtil.UTF_8);
ByteBuf buf = Unpooled.copiedBuffer("abcdef", CharsetUtil.UTF_8);
//加到CompositeByteBuf里面
byteBufs.addComponents(buf,buf1);
//do something
//移除第一个buf
byteBufs.removeComponent(0);
//循环遍历他里面有的所有实例
for(ByteBuf b:byteBufs){
System.out.println(b.toString());
}
}
如果想访问他里面的数据的话,我们还是得默认他里面hasArray为false,那么代码就和直接 内存的用法差不多了。
public static void main(String[] args) {
CompositeByteBuf buf = Unpooled.compositeBuffer();
int length = buf.readableBytes();
//在堆外,得创建数组
byte[] array = new byte[length];
buf.getBytes(buf.readerIndex(),array);
doSomething(array,0,length);
}
需要注意的是,Netty使用了CompositeByteBuf来优化套接字的io操作,尽可能的消除了由jdk的缓冲区实现所导致的性能以及内存使用率的惩罚。这种优化发生在Netty的核心代码中,因此不会暴露出来,但我们有必要知道这件事的存在。
说到底,如何创建一个ByteBuf对象呢
按需分配:ByteBufAllocator接口
为了降低分配和释放内存的开销,Netty通过ByteBufAllocator接口实现了池化。他可以用来分配我们所描述过的任何类型的ByteBuf的实例。下图是这个接口定义的操作:
 获取ByteBufAllocator的方法一般要么是用channel的alloc()方法,要么是channelHandlerContext的alloc()方法。
获取ByteBufAllocator的方法一般要么是用channel的alloc()方法,要么是channelHandlerContext的alloc()方法。
Netty对于ByteBufAllocator接口也有两种实现:PooledByteBufAllocator和UnPooledByteBufAllocator。前者用了一种被称为jemalloc的,已经被大量现代操作系统所采用的的高效方法来分配内存。后者则仅仅是返回一个新的实例。
在Netty4.1之前,系统默认使用Unpool版本,而之后,改为了Pool版本。当然我们可以手动设置,这也并不复杂。
Unpooled缓冲器
在前文中,我已经多次使用过这个类。因为在很多情况下,我们不能获取到一个ByteBufAllocator接口的实例,这时候,我们就可以通过这个类的静态辅助方法去创建非池化的ByteBuf实例。
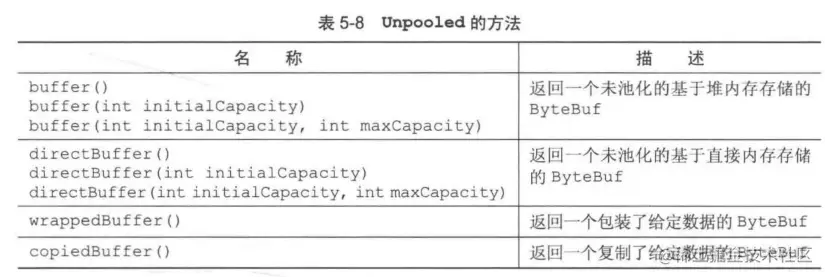
ByteBufUtil类
这就是一个很普通的工具类,他的api与是否池化无关。其中最有用的应该是equal方法,用于判断两个ByteBuf是否相等。
如果实现自己的ByteBuf实例,估计就能在那里找到更多有用的方法。
引用计数
引用计数是一种常见的垃圾回收策略,并被广泛应用在各种地方,比如python的垃圾回收策略就是引用计数(但java不是)。他其实不难理解。就是对象中维护一个字段代表被多少其他对象所引用,如果这个数值大于0,则不会被垃圾回收,如果减少到0则会被回收。
netty中的ByteBuf和ByteBufHolder 就继承了ReferenceCounted接口,为了优化内存使用和性能,使用了引用计数。
引用计数这个技术对于池化功能尤其重要,就是因为他降低了内存分配的开销。
ByteBuf buf = byteBufAllocator.directBuffer();
//这里应该是1
System.out.println(buf.refCnt());
//减少这个对象的引用计数,如果减少为0 返回true 该对象被释放
boolean release = buf.release();
//再次访问被释放的对象会抛出异常
buf.readByte();
其中 refCnt方法或者release方法不一定非得+1引用计数或者-1引用计数。比如一些实现中,我们可能需要只要调用release就释放对象,那就得把它的引用计数值置为0。总之这个是由自己自由实现的。
那么谁负责释放呢:
一般来说,最后访问这个对象的对象负责释放这个对象。
最后
感谢大家阅读到这里,辛苦啦!
如果本文有什么错误的话,希望大家能提出来,非常感谢!