本文个人博客地址:JVM运行时数据区 (leafage.top)
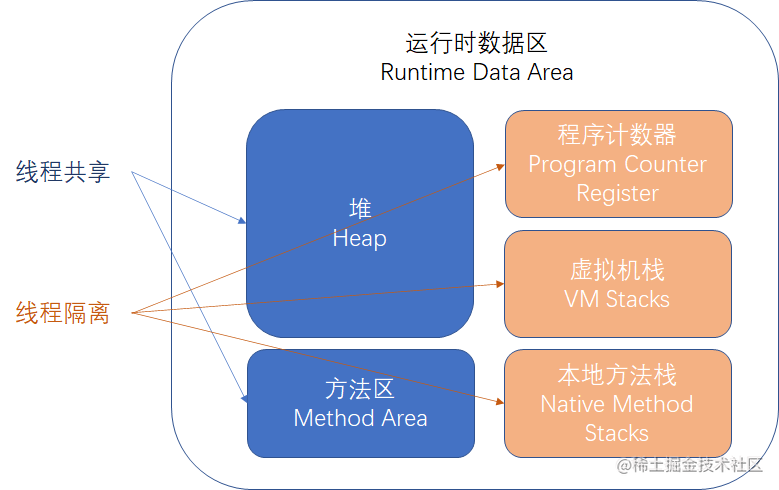
JVM 的运行时数据区分为:
- 程序计数器;
- 虚拟机栈;
- 本地方法栈;
- 堆;
- 方法区;
其中堆、方法区是线程共享的,程序计数器、虚拟机栈、本地方法栈是线程隔离的,结构图示如下:
1. 程序计数器:
Java虚拟机的多线程是通过线程轮流切换、分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)都只会执行一条线程中的指令。
为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,可以看作是当前线程所执行的字节码的行号指示器(存储指向下一条指令的地址),即将要执行的指令代码,各条线程之间计数器互不影响,独立存储。
通过 idea 的 debug 模式可以看到具体的信息:
其特点是:
- 程序计数器是一块较小的内存空间,线程私有的;
- 记录非本地方法执行时的字节码指令地址,如果是本地方法,值为 undefined;
- 唯一一个在《Java虚拟机规范》中没有规定任何 OutOfMemoryError 情况的区域;
2. 虚拟机栈:
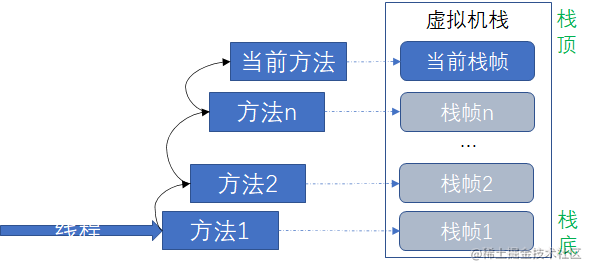
虚拟机栈描述的是Java方法执行的线程内存模型:每一个Java虚拟机线程创建的同时会创建一个独自的虚拟机栈,其内部保存一个个栈帧(Stack Frame)对应着一次次方法调用。
栈帧:
线程执行方法的内容保存在栈帧中,每一个方法都有自己的栈帧,而对于多层嵌套调用的方法,是根据方法的调用链,向栈中设置栈帧的(栈的操作都是先入,后出),示例如下所示:
同样,通过代码 debug 可以看到其效果:
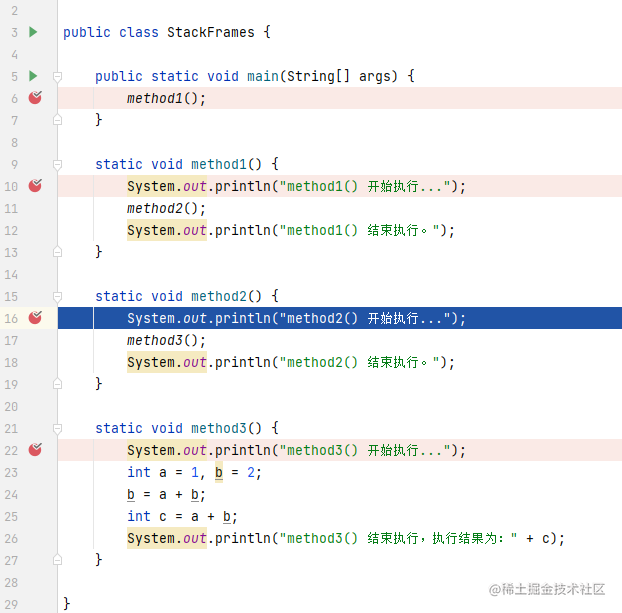
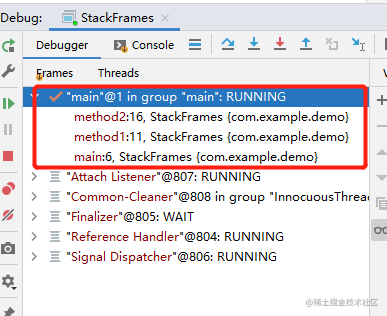
每个栈帧(Stack Frame)中存储着:
- 局部变量表(Local Variables);
- 操作数栈(Operand Stack);
- 动态链接(Dynamic Linking):指向运行时常量池的方法引用 ;
- 方法返回地址(Return Address):方法正常退出或异常退出的地址 一些附加信息;
- 附加信息
栈帧结构示例图如下所示:

3. 本地方法栈:
什么是本地方法?
答: 由其它语言编写的,编译成和处理器相关的机器代码。
本地方法保存在动态链接库中,即.dll(Windows系统)文件中,格式是各个平台专有的(Java是平台无关的,但是本地方法不是,这也是为什么 JDK 分 Linux、Windows、MacOS版本)
为什么要使用本地方法?
答: 使用本地方法的原因有以下几点:
- 与 Java 环境外交互:有时 Java 应用需要与 Java 外面的环境交互;
- 与操作系统交互:JVM 支持 Java 语言本身和运行时库,但是有时仍需要依赖一些底层系统的支持。通过本地方法,我们可以实现用 Java 与实现了 jre 的底层系统交互, JVM 的一些部分就是 C 语言写的。
- Sun‘s Java:Sun的解释器就是C实现的,这使得它能像一些普通的C一样与外部交互。比如:类 java.lang.Thread 的 setPriority() 的方法是用Java 实现的,但它实现调用的是该类的本地方法 setPrioruty(),该方法是C实现的,并被植入 JVM 内部。
本地方法栈的特点:
-
线程私有,允许线程固定或者可动态扩展的内存大小(同虚拟机栈一样):
- 如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常;
- 如果Java虚拟机栈容量可以动态扩展(HotSpot虚拟机的栈容量是不可以动态扩展的),当栈扩展时无法申请到足够的内存会抛出OutOfMemoryError异常;
-
通过本地方法接口来访问虚拟机内部的运行时数据区;
-
并不是所有 JVM 都支持本地方法。因为 《Java 虚拟机规范》并没有明确要求本地方法栈的使用语言、具体实现方式、数据结构等;
-
HotSpot虚拟机中,虚拟机栈和本地方法栈合二为一;
4. 堆:
对于大多数应用,Java 堆是 Java 虚拟机管理的内存中最大的一块,被所有线程共享。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例以及数据都在这里分配内存。
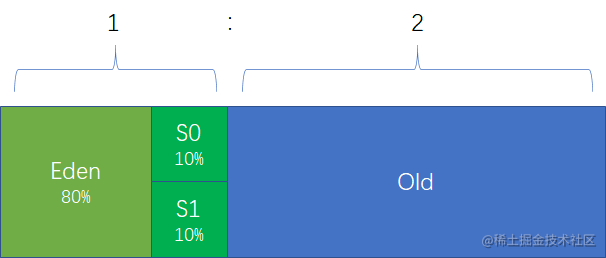
为了进行高效的垃圾回收,虚拟机把堆内存逻辑上划分成三块区域,目的只是为了更好地回收内存,或者更快地分配内存。
老年代的内存大小和年轻代的大小默认比例为 2:1,老年代默认的最小值为:操作系统运行内存/64,默认最大内存:操作系统运行内存/4;
这个我们可以通过代码,来看一看是否和描述的一致:
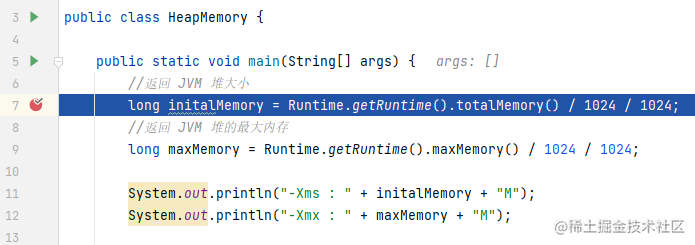
public class HeapMemory {
public static void main(String[] args) {
//返回 JVM 堆大小
long initalMemory = Runtime.getRuntime().totalMemory() / 1024 / 1024;
//返回 JVM 堆的最大内存
long maxMemory = Runtime.getRuntime().maxMemory() / 1024 / 1024;
System.out.println("-Xms : " + initalMemory + "M");
System.out.println("-Xmx : " + maxMemory + "M");
System.out.println("系统内存大小:" + initalMemory * 64 / 1024 + "G");
System.out.println("系统内存大小:" + maxMemory * 4 / 1024 + "G");
}
}
运行结果如下:
D:\env\jdk11\bin\java.exe ...
-Xms : 250M
-Xmx : 3996M
系统内存大小:15G
系统内存大小:15G
说到堆,那就离不开一个重要的概念,垃圾回收,JVM 垃圾回收针对不同的分代年龄,有不同的执行策略或算法。
什么是 Minor GC、Major GC、Mixed GC、Full GC?
答: 在进行 GC 时,并非每次都对堆内存(新生代、老年代;方法区)区域一起回收的,大部分时候回收的都是指新生代。
针对 HotSpot VM 的实现,它里面的 GC 按照回收区域又分为两大类:
-
部分收集:不是完整收集整个 Java 堆的垃圾收集。其中又分为:
- 新生代收集(Minor GC):只是新生代的垃圾收集;
- 老年代收集(Major GC):只是老年代的垃圾收集;
- 混合收集(Mixed GC):收集整个新生代以及部分老年代的垃圾收集(目前只有 G1 GC 会有这种行为 );
-
整堆收集(Full GC):收集整个 Java 堆和方法区的垃圾;
5. 方法区:
方法区存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等数据;
很多人都更愿意把方法区称呼为“永久代”(PermanentGeneration),或将两者混为一谈。本质上这两者并不是等价的,因为仅仅是当时的HotSpot虚拟机设计团队选择把收集器的分代设计扩展至方法区,或者说使用永久代来实现方法区而已,这样使得HotSpot的垃圾收集器能够像管理Java堆一样管理这部分内存,省去专门为方法区编写内存管理代码的工作。
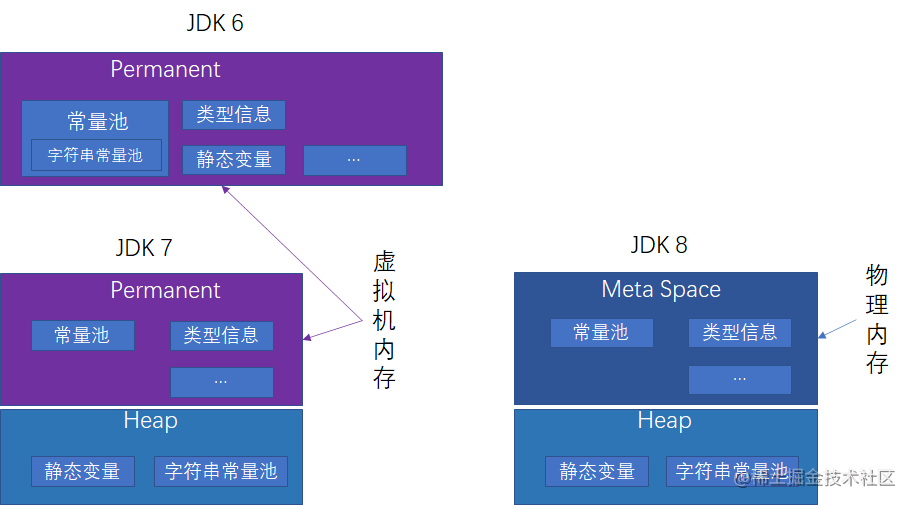
方法区随着 JDK 的发展,进行了几次大的变更,最重要的变更发生在 JDK6、JDK7、JDK8 ,其变化为:
- JDK6 --> JDK7: 将字符串常量池,静态变量移出老年代,放到堆中;
- JDK7 --> JDK8: 将老年代废弃,使用元空间实现,同时将数据存储变更为使用物理内存,不在占用 JVM 内存空间;
变更示例如下图所示:
为什么要替换永久代,使用元空间?
答: 原因有以下几点:
- 为永久代设置空间大小是很难确定的;
在某些场景下,如果动态加载类过多,容易产生 Perm 区的 OOM。如果某个实际 Web 工程中,因为功能点比较多,在运行过程中,要不断动态加载很多类,经常出现 OOM。而元空间和永久代最大的区别在于,元空间不在虚拟机中,而是使用本地内存,所以默认情况下,元空间的大小仅受本地内存限制
- 对永久代进行调优较困难;