最近修改了一个导出员工培训课程的历史记录(一年数据),导出功能本来就有的,不过前台做了时间限制(只能选择一个月时间内的),还有一些必选条件, 导出的数据非常有局限性。心想:为什么要做出这么多条件限制呢?条件限制无所谓了,能限制导出数据的准确性,但是时间? 如果我想导出一年的数据,还要一月一月的去导出,这也太扯了。于是我试着放开时间js限制,让用户自己随便选好了,然后自己选了一段时间,选了几门课程,点击按钮导出,MD报错了,看后台日志说什么IO流报异常,看了下代码,代码也很简单,查询数据,用HSSFWorkbook 写入数据,关闭流,导出,似乎没什么问题。于是去把查询的sql拉出来,放入数据库,查询数据,20w条数据,好吧,这下终于知道为什么加时间限制了,数据量过大!!!程序处理不了,改代码吧。 虽说实际工作中很少有百万数据导入excel,但不缺少一些会excel的高手,分析对比数据,像我这种手残党是不行,他们怎么用暂时不用管,能不能实现,就是我们应该考虑的事了。
此案例能解决2个问题:
1.用户导出速度过慢
2.采用分页导出,以解决单个sheet页数据量过大,打开速度过慢
简单介绍下我的操作:
1.HSSFWorkbook 和SXSSFWorkbook区别
HSSFWorkbook:是操作Excel2003以前(包括2003)的版本,扩展名是.xls,一张表最大支持 65536 行数据,256列,也就是说一个sheet页,最多导出 6w多条数据
XSSFWorkbook:是操作Excel2007-2010的版本,扩展名是.xlsx对于不同版本的EXCEL文档要使用不同的工具类,如果使用错了,
会提示如下错误信息。
org.apache.poi.openxml4j.exceptions.InvalidOperationException
org.apache.poi.poifs.filesystem.OfficeXmlFileException
它的一张表最大支持 1048576 行,16384列,关于两者介绍,对下面导出百万数据很重要,不要使用错了!
2.使用SXSSFWorkbook对象,导出百万数据
SXSSFWorkbook使用方法和 HSSFWorkbook差不多,如果你之前和我一样用的HSSFWorkbook,现在想要修改,则只需要将HSSFWorkbook改成SXSSFWorkbook即可,下面有我介绍,具体使用也可参考API。
3.如何将百万数据分成多个sheet页,导出到excel
导出百万数据到excel,很简单,只需要将原来的HSSFWorkbook修改成SXSSFWorkbook,或者直接使用SXSSFWorkbook对象,它是直接用来导出大数据用的,官方文档 有介绍,但是如果有300w条数据,一下导入一个excel的sheet页中,想想打开excel也需要一段时间吧,慢的话有可能导致程序无法加载,或者直接结束进程的情况发生,曾看到过一段新闻 ,这里对老外的毅力也是深表佩服。
这里给出部分代码,供参考研究,分页已实现:
@SuppressWarnings({ "deprecation", "unchecked" })
@RequestMapping("export-TrainHistoryRecord")
@ResponseBody
protected void buildExcelDocument(EmployeeTrainHistoryQuery query,ModelMap model,
SXSSFWorkbook workbook, HttpServletRequest request,
HttpServletResponse response) throws Exception {
try {
response.reset();
// 获得国际化语言
RequestContext requestContext = new RequestContext(request);
String CourseCompany = requestContext
.getMessage("manage-student-trainRecods");
response.setContentType("APPLICATION/vnd.ms-excel;charset=UTF-8");
// 注意,如果去掉下面一行代码中的attachment; 那么也会使IE自动打开文件。
response.setHeader(
"Content-Disposition",
"attachment; filename="
+ java.net.URLEncoder.encode(
DateUtil.getExportDate() + ".xlsx", "UTF-8"));//Excel 扩展名指定为xlsx SXSSFWorkbook对象只支持xlsx格式
OutputStream os = response.getOutputStream();
CellStyle style = workbook.createCellStyle();
// 设置样式
style.setFillForegroundColor(HSSFColor.SKY_BLUE.index);//设置单元格着色
style.setFillPattern(HSSFCellStyle.SOLID_FOREGROUND); //设置单元格填充样式
style.setBorderBottom(HSSFCellStyle.BORDER_THIN);//设置下边框
style.setBorderLeft(HSSFCellStyle.BORDER_THIN);//设置左边框
style.setBorderRight(HSSFCellStyle.BORDER_THIN);//设置右边框
style.setBorderTop(HSSFCellStyle.BORDER_THIN);//上边框
style.setAlignment(HSSFCellStyle.ALIGN_CENTER);// 居中
//获取国际化文件
String employeeCode = requestContext.getMessage("employeeCode");
String employeeName = requestContext.getMessage("employeeName");
String orgName = requestContext.getMessage("orgName");
String startDate = requestContext.getMessage("start.date");
String endDate = requestContext.getMessage("end.date");
String courseCode = requestContext.getMessage("courseCode");
String courseName = requestContext.getMessage("courseName");
String sessionName = requestContext.getMessage("sessionName");
List<EmployeeTrainHistoryModel> list = null;
try {
//查询数据库中共有多少条数据
query.setTotalItem(employeeTrainHistoryService.fetchCountEmployeeTrainHistoryByQuery(query));
int page_size = 100000;// 定义每页数据数量
int list_count =query.getTotalItem();
//总数量除以每页显示条数等于页数
int export_times = list_count % page_size > 0 ? list_count / page_size
+ 1 : list_count / page_size;
//循环获取产生每页数据
for (int m = 0; m < export_times; m++) {
query.setNeedQueryAll(false);
query.setPageSize(100000);//每页显示多少条数据
query.setCurrentPage(m+1);//设置第几页
list=employeeTrainHistoryService.getEmployeeTrainHistoryByQuery(query);
//新建sheet
Sheet sheet = null;
sheet = workbook.createSheet(System.currentTimeMillis()
+ CourseCompany+m);
// 创建属于上面Sheet的Row,参数0可以是0~65535之间的任何一个,
Row header = sheet.createRow(0); // 第0行
// 产生标题列,每个sheet页产生一个标题
Cell cell;
String[] headerArr = new String[] { employeeCode, employeeName,
orgName, startDate, endDate, courseCode, courseName, sessionName,
hoursNunber };
for (int j = 0; j < headerArr.length; j++) {
cell = header.createCell((short) j);
cell.setCellStyle(style);
cell.setCellValue(headerArr[j]);
}
// 迭代数据
if (list != null && list.size() > 0) {
int rowNum = 1;
for (int i = 0; i < list.size(); i++) {
EmployeeTrainHistoryModel history=list.get(i);
sheet.setDefaultColumnWidth((short) 17);
Row row = sheet.createRow(rowNum++);
row.createCell((short) 0).setCellValue(
history.getEmployeeCode());
row.createCell((short) 1).setCellValue(
history.getEmployeeName());
row.createCell((short) 2)
.setCellValue(history.getOrgName());
if (history.getTrainBeginTime() != null) {
row.createCell((short) 3).setCellValue(
DateUtil.toString(history.getTrainBeginTime()));
} else {
row.createCell((short) 3).setCellValue("");
}
if (history.getTrainEndTime() != null) {
row.createCell((short) 4).setCellValue(
DateUtil.toString(history.getTrainEndTime()));
} else {
row.createCell((short) 4).setCellValue("");
}
row.createCell((short) 5).setCellValue(
history.getCourseCode());
row.createCell((short) 6).setCellValue(
history.getCourseName());
row.createCell((short) 7).setCellValue(
history.getSessionName());
if (history.getHoursNumber() != null)
row.createCell((short) 8).setCellValue(
history.getHoursNumber().toString());
}
}
list.clear();
}
} catch (Exception e) {
e.printStackTrace();
}
try {
workbook.write(os);
os.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} catch (IOException e) {
e.printStackTrace();
}
}
4.如何高效导出数据
第3部分,大数据量导出数据,分页都已实现,但怎样才能去压榨时间,高效导出?Apache POI既然提供了导出excel的方法,想必也考虑到了效率问题,查看官方文档 , 果不其然,看文档,大概意思就是说SXSSF在必须生成大型电子表格时使用,堆空间有限
 官方提供了2种方法:
官方提供了2种方法:
- SXSSFWorkbook wb = new SXSSFWorkbook(100); // keep 100 rows in memory, exceeding rows will be flushed to disk
2.SXSSFWorkbook wb = new SXSSFWorkbook(-1); // turn off auto-flushing and accumulate all rows in memory
值100 在内存中保留100行,超过行将被刷新到磁盘
值-1表示无限制访问。 在这种情况下所有,没有被调用flush()刷新的记录可用,用于随机访问。
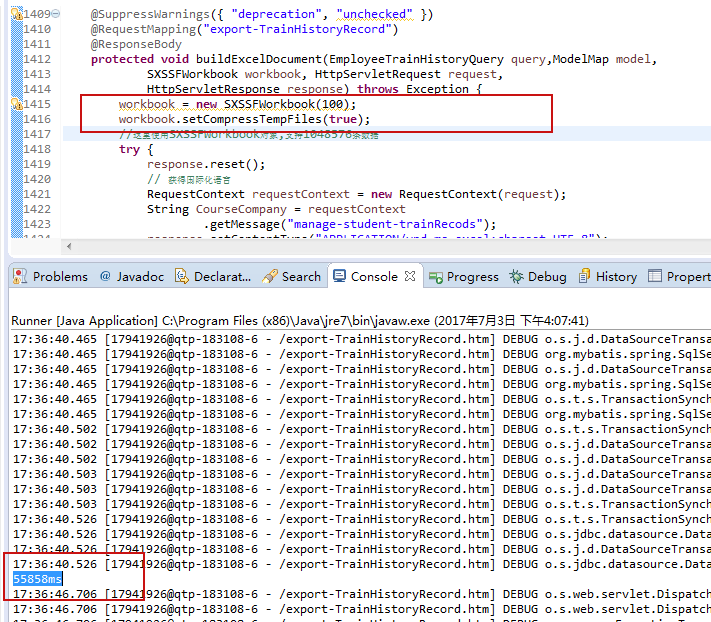
文章在最后说,当临时文件过大时,可使用setCompressTempFiles方法进行压缩,

比较贪心,这里我用了两个,一个用来设置临时文件,另一个用来输入数据,测试数据为30w数据,结果如图,不过还是感觉花费时间太多,不知道是不是我的程序写的有问题,知道的小伙伴,留个言吧!