前两天一个晚上,正当我沉浸在敲代码的快乐中时,听到隔壁的同事传来一声不可置信的惊呼:线程池提交命令怎么可能会执行一秒多?
线程池提交方法执行一秒多?那不对啊,线程池提交应该是一个很快的操作,一般情况下不应该执行一秒多那么长的时间。
看了一下那段代码,好像也没什么问题,就是一个简单的提交任务的代码。
executor.execute( () -> {
// 具体的任务代码
// 这里有个for循环
});
虽然执行的Job里面有一个for循环,可能比较耗时,但是execute提交任务的时候,并不会去真正去执行Job,所以应该不是这个原因引起的。
分析
看到这个情况,我们首先想到的是线程池提交任务时候的一个处理过程:
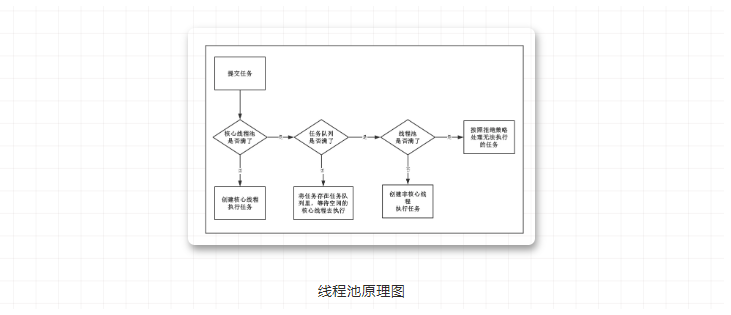
然后逐个分析一下有可能耗时一秒多的操作:
创建线程耗时?
根据上面的图,我们可以知道,如果核心线程数量设置过大,就可能会不断创建新的核心线程去执行任务。同理,如果核心线程池和任务队列都满了,会创建非核心线程去执行任务。
创建线程是比较耗时的,而且Java线程池在这里创建线程的时候还上了锁。
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
我们写个简单的程序,可以模拟出来线程池耗时的操作,下面这段代码创建2w个线程,在我的电脑里大概会耗时6k多毫秒。
long before = System.currentTimeMillis();
for (int i = 0; i < 20000; i++) {
// doSomething里面睡眠一秒
new Thread(() -> doSomething()).start();
}
long after = System.currentTimeMillis();
// 下面这行在我的电脑里输出6139
System.out.println(after - before);
但是看了一下我们的监控,线程数量一直比较健康,应该不是这个原因。再说那个地方新线程也不太可能达到这个量级。
入任务队列耗时?
线程池的任务队列是一个同步队列。所以入队列操作是同步的。
常用的几个同步队列:
- LinkedBlockingQueue
链式阻塞队列,底层数据结构是链表,默认大小是Integer.MAX_VALUE,也可以指定大小。 - ArrayBlockingQueue
数组阻塞队列,底层数据结构是数组,需要指定队列的大小。 - SynchronousQueue
同步队列,内部容量为0,每个put操作必须等待一个take操作,反之亦然。 - DelayQueue
延迟队列,该队列中的元素只有当其指定的延迟时间到了,才能够从队列中获取到该元素 。
所以使用特殊的同步队列还是有可能导致execute方法阻塞一秒多的,比如SynchronousQueue。如果配合一个特殊的“拒绝策略”,是有可能造成这个现象的,我们将在下面给出例子。
拒绝策略?
线程数量达到最大线程数就会采用拒绝处理策略,四种拒绝处理的策略为 :
- ThreadPoolExecutor.AbortPolicy:默认拒绝处理策略,丢弃任务并抛出异常。
- ThreadPoolExecutor.DiscardPolicy:丢弃新来的任务,但是不抛出异常。
- ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列头部(最旧的)的任务,然后重新尝试执行程序(如果再次失败,重复此过程)。
- ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务。
可以看到,前面三种拒绝处理策略都是会“丢弃”任务,而最后一种不会。最后一种拒绝策略配合上面的SynchronousQueue,就有可能造成我们遇到的情况。示例代码:
Executor executor = new ThreadPoolExecutor(2,2, 2,
TimeUnit.MILLISECONDS,new SynchronousQueue<>(),
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 0; i < 3; i++) {
long before = System.currentTimeMillis();
executor.execute( () -> {
// doSomething里面睡眠一秒
doSomething();
});
long after = System.currentTimeMillis();
// 下面这段代码,第三行会输出1001
System.out.println(after - before);
}
SimpleAsyncTaskExecutor
所以我们遇到的问题会是上面的种种原因导致的吗?带着这些猜测,我们去找到了定义executor的代码。
SimpleAsyncTaskExecutor executor = new SimpleAsyncTaskExecutor();
executor.setConcurrencyLimit(20);
设置最大并发数量是20好像没什么问题,等等,这个SimpleAsyncTaskExecutor是个什么鬼?
好像是Spring提供的一个线程池吧……(声音逐渐不自信)
em…看了一下包的定义,org.springframework.core.task,确实是Spring提供的。至于是不是线程池,先看看类图:
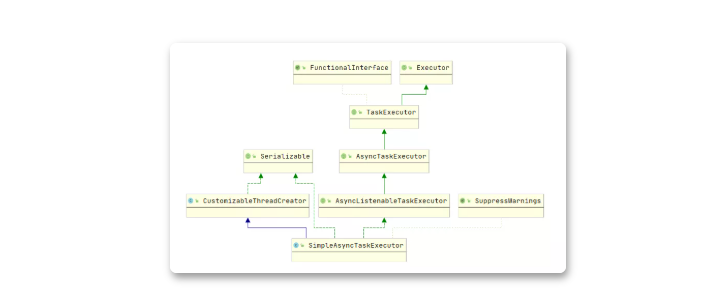
实现的是Executor接口,但是继承树里为什么没有ThreadPoolExecutor?我们猜测可能是Spring自己实现了一个线程池?虽然应该没什么必要。
源码
带着疑问,我们继续看了一下这个类的源码。主要看execute方法,发现每次执行之前,都要先调用一个beforeAccess方法,这个方法里面有这样一段很奇怪的代码:
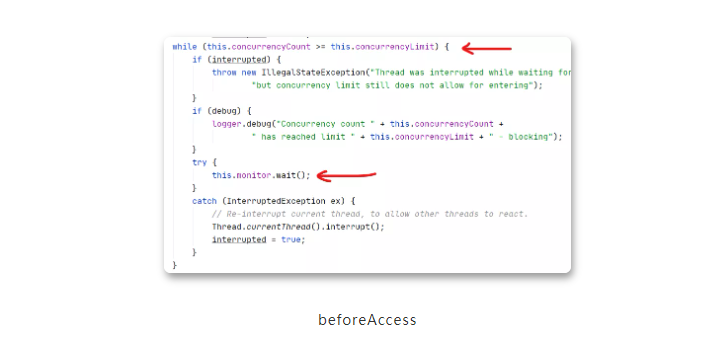
while循环去检查,如果当前并发线程数量大于等于设置的最大值,就等待。
找到原因了,这应该就是罪魁祸首。可是为什么Spring要这么设计呢?
我们在SimpleAsyncTaskExecutor类的注释上面找到了作者的留言:
* <p><b>NOTE: This implementation does not reuse threads!</b> Consider a
* thread-pooling TaskExecutor implementation instead, in particular for
* executing a large number of short-lived tasks.
大概意思就是:这个实现并不复用线程,如果你要复用线程请去使用线程池的实现。这个是用来执行很多耗时很短的任务的。
至此,真相大白。
反思
使用接口前先了解一下
造成这个问题的根本原因是,我们以为SimpleAsyncTaskExecutor是一个“线程池”,而其实它不是!!!
我们在使用开源项目的时候,往往直接就用了,不会去仔细看看它的源码,也可能没有考虑清楚它的应用环境。等到程序出问题了才发现,已经晚了。
所以使用接口之前最好先了解一下,至少要看看官方文档或者接口文档/注释。
哪怕是真的出问题了,看源码也不失为一种排查问题的方式,因为代码都是死的,它不会骗人。
代码规约
阿里有这么一个代码规约:不建议我们直接使用Executors类中的线程池,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学需要更加明确线程池的运行规则,规避资源耗尽的风险。
以前我还不太理解,心想使用Executors类可以提高可读性,JDK提供了这样的工具类,不用白不用。直到遇到这个问题,才明白这条规约的良苦用心。
如果我们使用规范的方式去使用线程池,而不是用一个所谓的Spring提供的“线程池”,就不会遇到这个问题了。
明确接口职责
再来想一想为什么同事会把它当成一个线程池?因为它的类名、方法名都太像一个线程池了。它实现了Executor接口的execute方法,才导致我们误以为它是一个线程池。
所以回归到Executor这个接口上来,它的职责究竟是什么?我们可以在JDK的execute方法上看到这个注释:
/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*/
大意就是,在将来某个时间执行传入的命令,这个命令可能会在一个新的线程里面执行,可能会在线程池里,也可能在调用这个方法的线程中,具体怎么执行是由实现类去决定的。
所以这才是Executor这个类的职责,它的职责并不是提供一个线程池的接口,而是提供一个“将来执行命令”的接口。
所以,真正能代表线程池意义的,是ThreadPoolExecutor类,而不是Executor接口。
在我们写代码的时候,也要定义清楚接口的职责哟。这样别人用你的接口或者阅读源码的时候,才不会疑惑。
来源:编了个程
作者:Yasin x