这种文章挺难写的,一是JVM参数巨多,二是内容枯燥乏味,但是想理解JVM调优又是没法避开的环节,本文主要用来总结梳理便于以后翻阅,主要围绕四个大的方面展开,分别是JVM调优参数、JVM调优方法(流程)、JVM调优工具、JVM调优案例,调优案例目前正在分析,会在将来补上。
垃圾回收有关参数
参数部分,这儿只是做一个总结,更详细更新的内容请参考Oracle官网:JVM的命令行参数参考
处理器组合参数
关于JVM垃圾处理器区别,参考:JVM调优之垃圾定位、垃圾回收算法、垃圾处理器对比
-XX:+UseSerialGC = Serial New (DefNew) + Serial Old
适用于小型程序。默认情况下不会是这种选项,HotSpot会根据计算及配置和JDK版本自动选择收集器
-XX:+UseParNewGC = ParNew + SerialOld
这个组合已经很少用(在某些版本中已经废弃),详情参考:Why Remove support for ParNew+SerialOld and DefNew+CMS in the future?
-XX:+UseConc(urrent)MarkSweepGC = ParNew + CMS + Serial Old
-XX:+UseParallelGC = Parallel Scavenge + Parallel Old (1.8默认) 【PS + SerialOld】
-XX:+UseParallelOldGC = Parallel Scavenge + Parallel Old
-XX:+UseG1GC = G1
Linux中没找到默认GC的查看方法,而windows中会打印UseParallelGC
- java +XX:+PrintCommandLineFlags -version
- 通过GC的日志来分辨
Linux下1.8版本默认的垃圾回收器到底是什么?
- 1.8.0_181 默认(看不出来)Copy MarkCompact
- 1.8.0_222 默认 PS + PO
虚拟机参数
| 参数名称 | 含义 | 默认值 | 解释说明 |
|---|---|---|---|
| -Xms | 初始堆大小 | 物理内存的1/64(<1GB) | 默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制. |
| -Xmx | 最大堆大小 | 物理内存的1/4(<1GB) | 默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到-Xms的最小限制 |
| -Xmn | 年轻代大小(1.4orlator) | 注意 :此处的大小是(eden+2survivorspace).与jmap-heap中显示的Newgen是不同的。整个堆大小=年轻代大小+年老代大小+持久代大小.增大年轻代后,将会减小年老代大小.此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8 | |
| -XX:NewSize | 设置年轻代大小(for1.3/1.4) | ||
| -XX:MaxNewSize | 年轻代最大值(for1.3/1.4) | ||
| -XX:PermSize | 设置持久代(permgen)初始值 | 物理内存的1/64 | |
| -XX:MaxPermSize | 设置持久代最大值 | 物理内存的1/4 | |
| -Xss | 每个线程的堆栈大小 | JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K.更具应用的线程所需内存大小进行调整.在相同物理内存下,减小这个值能生成更多的线程.但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右一般小的应用,如果栈不是很深,应该是128k够用的大的应用建议使用256k。这个选项对性能影响比较大,需要严格的测试。和threadstacksize选项解释很类似,官方文档似乎没有解释,在论坛中有这样一句话:"”-XssistranslatedinaVMflagnamedThreadStackSize”一般设置这个值就可以了。 | |
| -XX:ThreadStackSize | ThreadStackSize | (0meansusedefaultstacksize)[Sparc:512;Solarisx86:320(was256priorin5.0andearlier);Sparc64bit:1024;Linuxamd64:1024(was0in5.0andearlier);allothers0.] | |
| -XX:NewRatio | 年轻代(包括Eden和两个Survivor区)与年老代的比值(除去持久代) | -XX:NewRatio=4表示年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5Xms=Xmx并且设置了Xmn的情况下,该参数不需要进行设置。 | |
| -XX:SurvivorRatio | Eden区与Survivor区的大小比值 | 设置为8,则两个Survivor区与一个Eden区的比值为2:8,一个Survivor区占整个年轻代的1/10 | |
| -XX:LargePageSizeInBytes | 内存页的大小不可设置过大,会影响Perm的大小 | =128m | |
| -XX:+UseFastAccessorMethods | 原始类型的快速优化 | ||
| -XX:+DisableExplicitGC | 关闭System.gc() | 这个参数需要严格的测试 | |
| -XX:MaxTenuringThreshold | 垃圾最大年龄 | 如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代.对于年老代比较多的应用,可以提高效率.如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概率该参数只有在串行GC时才有效. | |
| -XX:+AggressiveOpts | 加快编译 | ||
| -XX:+UseBiasedLocking | 锁机制的性能改善 | ||
| -Xnoclassgc | 禁用垃圾回收 | ||
| -XX:SoftRefLRUPolicyMSPerMB | 每兆堆空闲空间中SoftReference的存活时间 | 1s | softlyreachableobjectswillremainaliveforsomeamountoftimeafterthelasttimetheywerereferenced.Thedefaultvalueisonesecondoflifetimeperfreemegabyteintheheap |
| -XX:PretenureSizeThreshold | 对象超过多大是直接在旧生代分配 | 0 | 单位字节新生代采用ParallelScavengeGC时无效另一种直接在旧生代分配的情况是大的数组对象,且数组中无外部引用对象. |
| -XX:TLABWasteTargetPercent | TLAB占eden区的百分比 | 1% | |
| -XX:+CollectGen0First | FullGC时是否先YGC | false |
并行收集器相关参数
| 参数名称 | 含义 | 默认值 | 解释说明 |
|---|---|---|---|
| -XX:+UseParallelGC | FullGC采用parallelMSC(此项待验证) | 选择垃圾收集器为并行收集器.此配置仅对年轻代有效.即上述配置下,年轻代使用并发收集,而年老代仍旧使用串行收集.(此项待验证) | |
| -XX:+UseParNewGC | 设置年轻代为并行收集 | 可与CMS收集同时使用JDK5.0以上,JVM会根据系统配置自行设置,所以无需再设置此值 | |
| -XX:ParallelGCThreads | 并行收集器的线程数 | 此值最好配置与处理器数目相等同样适用于CMS | |
| -XX:+UseParallelOldGC | 年老代垃圾收集方式为并行收集(ParallelCompacting) | 这个是JAVA6出现的参数选项 | |
| -XX:MaxGCPauseMillis | 每次年轻代垃圾回收的最长时间(最大暂停时间) | 如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值. | |
| -XX:+UseAdaptiveSizePolicy | 自动选择年轻代区大小和相应的Survivor区比例 | 设置此选项后,并行收集器会自动选择年轻代区大小和相应的Survivor区比例,以达到目标系统规定的最低相应时间或者收集频率等,此值建议使用并行收集器时,一直打开. | |
| -XX:GCTimeRatio | 设置垃圾回收时间占程序运行时间的百分比 | 公式为1/(1+n) | |
| -XX:+ScavengeBeforeFullGC | FullGC前调用YGC | true | DoyounggenerationGCpriortoafullGC.(Introducedin1.4.1.) |
CMS处理器参数设置
| 参数名称 | 含义 | 默认值 | 解释说明 |
|---|---|---|---|
| -XX:+UseConcMarkSweepGC | 使用CMS内存收集 | 测试中配置这个以后,-XX:NewRatio=4的配置失效了,原因不明.所以,此时年轻代大小最好用-Xmn设置.??? | |
| -XX:+AggressiveHeap | 试图是使用大量的物理内存长时间大内存使用的优化,能检查计算资源(内存,处理器数量)至少需要256MB内存大量的CPU/内存,(在1.4.1在4CPU的机器上已经显示有提升) | ||
| -XX:CMSFullGCsBeforeCompaction | 多少次后进行内存压缩 | 由于并发收集器不对内存空间进行压缩,整理,所以运行一段时间以后会产生"碎片",使得运行效率降低.此值设置运行多少次GC以后对内存空间进行压缩,整理. | |
| -XX:+CMSParallelRemarkEnabled | 降低标记停顿 | ||
| -XX+UseCMSCompactAtFullCollection | 在FULLGC的时候,对年老代的压缩 | CMS是不会移动内存的,因此,这个非常容易产生碎片,导致内存不够用,因此,内存的压缩这个时候就会被启用。增加这个参数是个好习惯。可能会影响性能,但是可以消除碎片 | |
| -XX:+UseCMSInitiatingOccupancyOnly | 使用手动定义初始化定义开始CMS收集 | 禁止hostspot自行触发CMSGC | |
| -XX:CMSInitiatingOccupancyFraction=70 | 使用cms作为垃圾回收使用70%后开始CMS收集 | 92 | 为了保证不出现promotionfailed(见下面介绍)错误,该值的设置需要满足以下公式 CMSInitiatingOccupancyFraction计算公式 |
| -XX:CMSInitiatingPermOccupancyFraction | 设置PermGen使用到达多少比率时触发 | 92 | |
| -XX:+CMSIncrementalMode | 设置为增量模式 | 用于单CPU情况 | |
| -XX:+CMSClassUnloadingEnabled |
JVM辅助信息参数设置
| 参数名称 | 含义 | 默认值 | 解释说明 |
|---|---|---|---|
| -XX:+PrintGC | 输出形式:[GC118250K->113543K(130112K),0.0094143secs][FullGC121376K->10414K(130112K),0.0650971secs] | ||
| -XX:+PrintGCDetails | 输出形式:[GC[DefNew:8614K->781K(9088K),0.0123035secs]118250K->113543K(130112K),0.0124633secs][GC[DefNew:8614K->8614K(9088K),0.0000665secs][Tenured:112761K->10414K(121024K),0.0433488secs]121376K->10414K(130112K),0.0436268secs] | ||
| -XX:+PrintGCTimeStamps | |||
| -XX:+PrintGC:PrintGCTimeStamps | 可与-XX:+PrintGC-XX:+PrintGCDetails混合使用输出形式:11.851:[GC98328K->93620K(130112K),0.0082960secs] | ||
| -XX:+PrintGCApplicationStoppedTime | 打印垃圾回收期间程序暂停的时间.可与上面混合使用 | 输出形式:Totaltimeforwhichapplicationthreadswerestopped:0.0468229seconds | |
| -XX:+PrintGCApplicationConcurrentTime | 打印每次垃圾回收前,程序未中断的执行时间.可与上面混合使用 | 输出形式:Applicationtime:0.5291524seconds | |
| -XX:+PrintHeapAtGC | 打印GC前后的详细堆栈信息 | ||
| -Xloggc:filename | 把相关日志信息记录到文件以便分析.与上面几个配合使用 | ||
| -XX:+PrintClassHistogram | garbagecollectsbeforeprintingthehistogram. | ||
| -XX:+PrintTLAB | 查看TLAB空间的使用情况 | ||
| XX:+PrintTenuringDistribution | 查看每次minorGC后新的存活周期的阈值 | Desiredsurvivorsize1048576bytes,newthreshold7(max15)newthreshold7即标识新的存活周期的阈值为7。 |
JVM GC垃圾回收器参数设置
JVM给出了3种选择: 串行收集器 、 并行收集器 、 并发收集器 。串行收集器只适用于小数据量的情况,所以生产环境的选择主要是并行收集器和并发收集器。默认情况下JDK5.0以前都是使用串行收集器,如果想使用其他收集器需要在启动时加入相应参数。JDK5.0以后,JVM会根据当前系统配置进行智能判断。
串行收集器
-XX:+UseSerialGC:设置串行收集器。
并行收集器(吞吐量优先)
-XX:+UseParallelGC:设置为并行收集器。此配置仅对年轻代有效。即年轻代使用并行收集,而年老代仍使用串行收集。
-XX:ParallelGCThreads=20:配置并行收集器的线程数,即:同时有多少个线程一起进行垃圾回收。此值建议配置与CPU数目相等。
-XX:+UseParallelOldGC:配置年老代垃圾收集方式为并行收集。JDK6.0开始支持对年老代并行收集。
-XX:MaxGCPauseMillis=100:设置每次年轻代垃圾回收的最长时间(单位毫秒)。如果无法满足此时间,JVM会自动调整年轻代大小,以满足此时间。
-XX:+UseAdaptiveSizePolicy:设置此选项后,并行收集器会自动调整年轻代Eden区大小和Survivor区大小的比例,以达成目标系统规定的最低响应时间或者收集频率等指标。此参数建议在使用并行收集器时,一直打开。
并发收集器(响应时间优先)
并行收集器
-XX:+UseConcMarkSweepGC:即CMS收集,设置年老代为并发收集。CMS收集是JDK1.4后期版本开始引入的新GC算法。它的主要适合场景是对响应时间的重要性需求大于对吞吐量的需求,能够承受垃圾回收线程和应用线程共享CPU资源,并且应用中存在比较多的长生命周期对象。CMS收集的目标是尽量减少应用的暂停时间,减少Full GC发生的几率,利用和应用程序线程并发的垃圾回收线程来标记清除年老代内存。
-XX:+UseParNewGC:设置年轻代为并发收集。可与CMS收集同时使用。JDK5.0以上,JVM会根据系统配置自行设置,所以无需再设置此参数。
-XX:CMSFullGCsBeforeCompaction=0:由于并发收集器不对内存空间进行压缩和整理,所以运行一段时间并行收集以后会产生内存碎片,内存使用效率降低。此参数设置运行0次Full GC后对内存空间进行压缩和整理,即每次Full GC后立刻开始压缩和整理内存。
-XX:+UseCMSCompactAtFullCollection:打开内存空间的压缩和整理,在Full GC后执行。可能会影响性能,但可以消除内存碎片。
-XX:+CMSIncrementalMode:设置为增量收集模式。一般适用于单CPU情况。
-XX:CMSInitiatingOccupancyFraction=70:表示年老代内存空间使用到70%时就开始执行CMS收集,以确保年老代有足够的空间接纳来自年轻代的对象,避免Full GC的发生。
其它垃圾回收参数
-XX:+ScavengeBeforeFullGC:年轻代GC优于Full GC执行。
-XX:-DisableExplicitGC:不响应 System.gc() 代码。
-XX:+UseThreadPriorities:启用本地线程优先级API。即使 java.lang.Thread.setPriority() 生效,不启用则无效。
-XX:SoftRefLRUPolicyMSPerMB=0:软引用对象在最后一次被访问后能存活0毫秒(JVM默认为1000毫秒)。
-XX:TargetSurvivorRatio=90:允许90%的Survivor区被占用(JVM默认为50%)。提高对于Survivor区的使用率。
JVM参数优先级
-Xmn,-XX:NewSize/-XX:MaxNewSize,-XX:NewRatio 3组参数都可以影响年轻代的大小,混合使用的情况下,优先级是什么?
答案如下:
高优先级:-XX:NewSize/-XX:MaxNewSize
中优先级:-Xmn(默认等效 -Xmn=-XX:NewSize=-XX:MaxNewSize=?)
低优先级:-XX:NewRatio推荐使用-Xmn参数,原因是这个参数简洁,相当于一次设定 NewSize/MaxNewSIze,而且两者相等,适用于生产环境。-Xmn 配合 -Xms/-Xmx,即可将堆内存布局完成。
-Xmn参数是在JDK 1.4 开始支持。
下面用一些小案例加深理解:
HelloGC是java代码编译后的一个class文件,代码:
public class T01_HelloGC {
public static void main(String[] args) {
for(int i=0; i<10000; i++) {
byte[] b = new byte[1024 * 1024];
}
}
}
- java -XX:+PrintCommandLineFlags HelloGC
[root@localhost courage]# java -XX:+PrintCommandLineFlags T01_HelloGC
-XX:InitialHeapSize=61780800 -XX:MaxHeapSize=988492800 -XX:+PrintCommandLineFlags -XX
:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseParallelGC
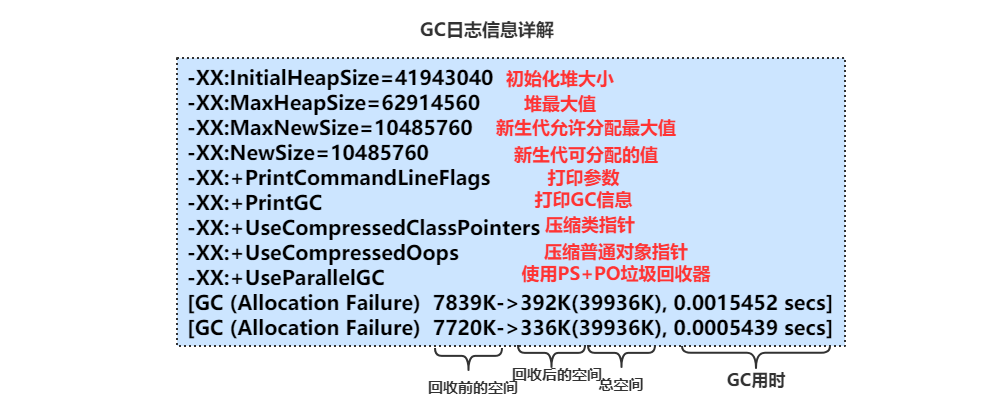
java -Xmn10M -Xms40M -Xmx60M -XX:+PrintCommandLineFlags -XX:+PrintGC HelloGC
PrintGCDetails PrintGCTimeStamps PrintGCCauses
结果:
-XX:InitialHeapSize=41943040 -XX:MaxHeapSize=62914560 -XX:MaxNewSize=10485760 -XX:NewSize=10485760 -XX:+PrintCommandLineFlags -XX:+PrintGC -XX:+UseCompressedClassPointers -XX:+UseCompressedOops
-XX:+UseParallelGC[GC (Allocation Failure) 7839K->392K(39936K), 0.0015452 secs]
[GC (Allocation Failure) 7720K->336K(39936K), 0.0005439 secs]
[GC (Allocation Failure) 7656K->336K(39936K), 0.0005749 secs]
[GC (Allocation Failure) 7659K->368K(39936K), 0.0005095 secs]
[GC (Allocation Failure) 7693K->336K(39936K), 0.0004385 secs]
[GC (Allocation Failure) 7662K->304K(40448K), 0.0028468 secs]
......
命令解释:
java:表示使用java执行器执行
-Xmn10M :表示设置年轻代值为10M
-Xms40M :表示设置堆内存的最小Heap值为40M
-Xmx60M :表示设置堆内存的最大Heap值为60M
-XX:+PrintCommandLineFlags:打印显式隐式参数,就是结果前三行
-XX:+PrintGC : 打印垃圾回收有关信息
HelloGC :这是需要执行的启动类
PrintGCDetails :打印GC详细信息
PrintGCTimeStamps :打印GC时间戳
PrintGCCauses :打印GC产生的原因
结果解释:
- java -XX:+UseConcMarkSweepGC -XX:+PrintCommandLineFlags HelloGC
表示使用CMS垃圾收集器,同时打印参数
打印结果:
-XX:InitialHeapSize=61780800
-XX:MaxHeapSize=988492800
-XX:MaxNewSize=329252864
-XX:MaxTenuringThreshold=6
-XX:OldPLABSize=16
-XX:+PrintCommandLineFlags
-XX:+UseCompressedClassPointers
-XX:+UseCompressedOops
-XX:+UseConcMarkSweepGC
-XX:+UseParNewGC
- java -XX:+PrintFlagsInitial 默认参数值
- java -XX:+PrintFlagsFinal 最终参数值
- java -XX:+PrintFlagsFinal | grep xxx 找到对应的参数
- java -XX:+PrintFlagsFinal -version |grep GC
JVM调优流程
JVM调优,设计到三个大的方面,在服务器出现问题之前要先根据业务场景选择合适的垃圾处理器,设置不同的虚拟机参数,运行中观察GC日志,分析性能,分析问题定位问题,虚拟机排错等内容,如果服务器挂掉了,要及时生成日志文件便于找到问题所在。
调优前的基础概念
目前的垃圾处理器中,一类是以吞吐量优先,一类是以响应时间优先:
\[吞吐量 = \frac{用户代码执行时间}{用户代码执行时间+垃圾回收执行时间} \]
响应时间:STW越短,响应时间越好
对吞吐量、响应时间、QPS、并发数相关概念可以参考:吞吐量(TPS)、QPS、并发数、响应时间(RT)概念
所谓调优,首先确定追求什么,是吞吐量? 还是追求响应时间?还是在满足一定的响应时间的情况下,要求达到多大的吞吐量,等等。一般情况下追求吞吐量的有以下领域:科学计算、数据挖掘等。吞吐量优先的垃圾处理器组合一般为:Parallel Scavenge + Parallel Old (PS + PO)。
而追求响应时间的业务有:网站相关 (JDK 1.8之后 G1,之前可以ParNew + CMS + Serial Old)
什么是调优?
- 根据需求进行JVM规划和预调优
- 优化运行JVM运行环境(慢,卡顿)
- 解决JVM运行过程中出现的各种问题(OOM)
调优之前的规划
-
调优,从业务场景开始,没有业务场景的调优都是耍流氓
-
无监控(压力测试,能看到结果),不调优
-
步骤:
-
熟悉业务场景(没有最好的垃圾回收器,只有最合适的垃圾回收器)
- 响应时间、停顿时间 [CMS G1 ZGC] (需要给用户作响应)
- 吞吐量 = 用户时间 /( 用户时间 + GC时间) [PS+PO]
-
选择回收器组合
-
计算内存需求(经验值 1.5G 16G)
-
选定CPU(越高越好)
-
设定年代大小、升级年龄
-
设定日志参数
-
-Xloggc:/opt/xxx/logs/xxx-xxx-gc-%t.log
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=5
-XX:GCLogFileSize=20M
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCCause
日志参数解释说明:
/opt/xxx/logs/xxx-xxx-gc-%t.log 中XXX表示路径,%t表示时间戳,意思是给日志文件添加一个时间标记,如果不添加的话,也就意味着每次虚拟机启动都会使用原来的日志名,那么会被重写。
Rotation中文意思是循环、轮流,意味着这个GC日志会循环写
GCLogFileSize=20M 指定一个日志大小为20M,太大了不利于分析,太小又会产生过多的日志文件
NumberOfGCLogFiles=5 : 指定生成的日志数目
PrintGCDateStamps :PrintGCDateStamps会打印具体的时间,而PrintGCTimeStamps
主要打印针对JVM启动的时候的相对时间,相对来说前者更消耗内存。
CPU高负荷排查流程
-
系统CPU经常100%,如何调优?(面试高频) CPU100%那么一定有线程在占用系统资源,
- 找出哪个进程cpu高(top)
- 该进程中的哪个线程cpu高(top -Hp)
- 导出该线程的堆栈 (jstack)
- 查找哪个方法(栈帧)消耗时间 (jstack)
- 工作线程占比高 | 垃圾回收线程占比高
-
系统内存飙高,如何查找问题?(面试高频)
- 导出堆内存 (jmap)
- 分析 (jhat jvisualvm mat jprofiler ... )
-
如何监控JVM
- jstat jvisualvm jprofiler arthas top...
CPU高负荷排查案例
- 测试代码:
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.concurrent.ScheduledThreadPoolExecutor;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* 从数据库中读取信用数据,套用模型,并把结果进行记录和传输
*/
public class T15_FullGC_Problem01 {
private static class CardInfo {
BigDecimal price = new BigDecimal(0.0);
String name = "张三";
int age = 5;
Date birthdate = new Date();
public void m() {}
}
private static ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(50,
new ThreadPoolExecutor.DiscardOldestPolicy());
public static void main(String[] args) throws Exception {
executor.setMaximumPoolSize(50);
for (;;){
modelFit();
Thread.sleep(100);
}
}
private static void modelFit(){
List<CardInfo> taskList = getAllCardInfo();
taskList.forEach(info -> {
// do something
executor.scheduleWithFixedDelay(() -> {
//do sth with info
info.m();
}, 2, 3, TimeUnit.SECONDS);
});
}
private static List<CardInfo> getAllCardInfo(){
List<CardInfo> taskList = new ArrayList<>();
for (int i = 0; i < 100; i++) {
CardInfo ci = new CardInfo();
taskList.add(ci);
}
return taskList;
}
}
- java -Xms200M -Xmx200M -XX:+PrintGC com.courage.jvm.gc.T15_FullGC_Problem01
- 收到CPU报警信息(CPU Memory)
- top命令观察到问题:内存不断增长 CPU占用率居高不下
[root@localhost ~]# top
top - 22:03:18 up 40 min, 5 users, load average: 0.09, 0.16, 0.34
Tasks: 210 total, 1 running, 209 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.2 us, 3.0 sy, 0.0 ni, 96.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 3861300 total, 2355260 free, 904588 used, 601452 buff/cache
KiB Swap: 4063228 total, 4063228 free, 0 used. 2716336 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3751 root 20 0 3780976 93864 11816 S 42.2 2.4 0:21.00 java
1868 mysql 20 0 1907600 357452 14744 S 0.7 9.3 0:17.40 mysqld
3816 root 20 0 162124 2352 1580 R 0.3 0.1 0:00.12 top
- top -Hp 观察进程中的线程,哪个线程CPU和内存占比高
[root@localhost ~]# top -Hp 3751
top - 22:03:15 up 40 min, 5 users, load average: 0.09, 0.16, 0.34
Threads: 66 total, 0 running, 66 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 2.5 sy, 0.0 ni, 97.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 3861300 total, 2354800 free, 905048 used, 601452 buff/cache
KiB Swap: 4063228 total, 4063228 free, 0 used. 2715876 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3801 root 20 0 3780976 93864 11816 S 1.3 2.4 0:00.40 java
3766 root 20 0 3780976 93864 11816 S 1.0 2.4 0:00.37 java
3768 root 20 0 3780976 93864 11816 S 1.0 2.4 0:00.36 java
3770 root 20 0 3780976 93864 11816 S 1.0 2.4 0:00.39 java
- jps定位具体java进程,jstack 定位线程状况
[root@localhost ~]# jstack 3751
2021-02-07 22:03:03
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.271-b09 mixed mode):
"Attach Listener" #59 daemon prio=9 os_prio=0 tid=0x00007f66bc002800 nid=0xf10 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"pool-1-thread-50" #58 prio=5 os_prio=0 tid=0x00007f66fc1de800 nid=0xee7 waiting on condition [0x00007f66e4ecd000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000ff0083a0> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
......
需要注意的是,jstack与top -Hp Port导出的栈端口号存在十六进制转换关系,例如jstack导出的" nid=0xf10 "对应"3801"。
对于上面打印的信息,重点关注跟Waiting有关的,看看在等待什么,例如:
WAITING BLOCKED eg. waiting on <0x0000000088ca3310> (a java.lang.Object)
假如有一个进程中100个线程,很多线程都在waiting on ,一定要找到是哪个线程持有这把锁,怎么找?搜索jstack dump的信息,看哪个线程持有这把锁RUNNABLE。
如果仅仅是看JAVA线程,可以使用jps命令重点关注:
[root@localhost ~]# jps
4818 Jps
4746 T15_FullGC_Problem01
- 为什么阿里规范里规定,线程的名称(尤其是线程池)都要写有意义的名称 怎么样自定义线程池里的线程名称?(自定义ThreadFactory)

- jinfo pid 进程详细信息
[root@localhost ~]# jinfo 6741
Attaching to process ID 6741, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.271-b09
Java System Properties:
java.runtime.name = Java(TM) SE Runtime Environment
java.vm.version = 25.271-b09
sun.boot.library.path = /usr/local/java/jdk1.8.0_271/jre/lib/amd64
java.vendor.url = http://java.oracle.com/
java.vm.vendor = Oracle Corporation
path.separator = :
file.encoding.pkg = sun.io
java.vm.name = Java HotSpot(TM) 64-Bit Server VM
sun.os.patch.level = unknown
sun.java.launcher = SUN_STANDARD
user.country = CN
user.dir = /usr/courage/gc/com/courage
java.vm.specification.name = Java Virtual Machine Specification
java.runtime.version = 1.8.0_271-b09
java.awt.graphicsenv = sun.awt.X11GraphicsEnvironment
os.arch = amd64
java.endorsed.dirs = /usr/local/java/jdk1.8.0_271/jre/lib/endorsed
java.io.tmpdir = /tmp
line.separator =
java.vm.specification.vendor = Oracle Corporation
os.name = Linux
sun.jnu.encoding = UTF-8
java.library.path = /usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/
libjava.specification.name = Java Platform API Specification
java.class.version = 52.0
sun.management.compiler = HotSpot 64-Bit Tiered Compilers
os.version = 3.10.0-1127.el7.x86_64
user.home = /root
user.timezone =
java.awt.printerjob = sun.print.PSPrinterJob
file.encoding = UTF-8
java.specification.version = 1.8
user.name = root
java.class.path = .
java.vm.specification.version = 1.8
sun.arch.data.model = 64
sun.java.command = T15_FullGC_Problem01
java.home = /usr/local/java/jdk1.8.0_271/jre
user.language = zh
java.specification.vendor = Oracle Corporation
awt.toolkit = sun.awt.X11.XToolkit
java.vm.info = mixed mode
java.version = 1.8.0_271
java.ext.dirs = /usr/local/java/jdk1.8.0_271/jre/lib/ext:/usr/java/packages/l
ib/extsun.boot.class.path = /usr/local/java/jdk1.8.0_271/jre/lib/resources.jar:/usr
/local/java/jdk1.8.0_271/jre/lib/rt.jar:/usr/local/java/jdk1.8.0_271/jre/lib/sunrsasign.jar:/usr/local/java/jdk1.8.0_271/jre/lib/jsse.jar:/usr/local/java/jdk1.8.0_271/jre/lib/jce.jar:/usr/local/java/jdk1.8.0_271/jre/lib/charsets.jar:/usr/local/java/jdk1.8.0_271/jre/lib/jfr.jar:/usr/local/java/jdk1.8.0_271/jre/classesjava.vendor = Oracle Corporation
file.separator = /
java.vendor.url.bug = http://bugreport.sun.com/bugreport/
sun.io.unicode.encoding = UnicodeLittle
sun.cpu.endian = little
sun.cpu.isalist =
VM Flags:
Non-default VM flags: -XX:CICompilerCount=3 -XX:InitialHeapSize=209715200 -XX
:MaxHeapSize=209715200 -XX:MaxNewSize=69730304 -XX:MinHeapDeltaBytes=524288 -XX:NewSize=69730304 -XX:OldSize=139984896 -XX:+PrintGC -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseFastUnorderedTimeStamps -XX:+UseParallelGC Command line: -Xms200M -Xmx200M -XX:+PrintGC
- jstat -gc 动态观察gc情况 / 阅读GC日志发现频繁GC / arthas观察 / jconsole/jvisualVM/ Jprofiler(最好用)
jstat gc 4655 500 : 每500毫秒打印端口4655的GC的情况
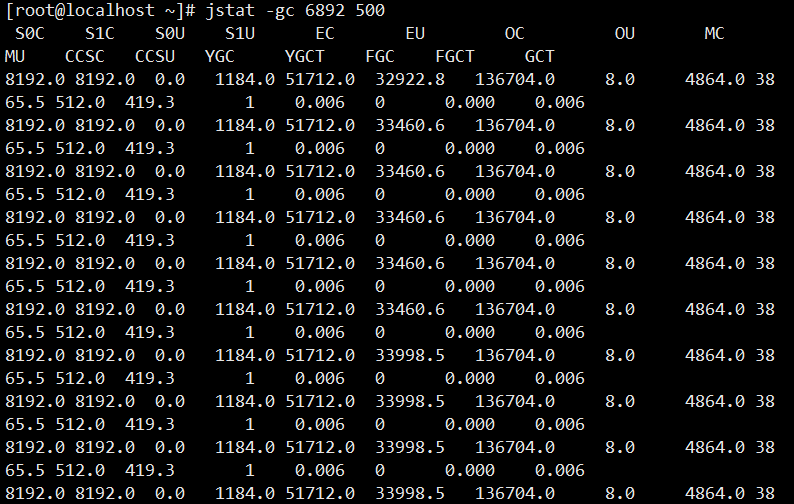
- S0C: 第一个幸存区的大小
- S1C: 第二个幸存区的大小
- S0U: 第一个幸存区的使用大小
- S1U: 第二个幸存区的使用大小
- EC: 伊甸园区的大小
- EU: 伊甸园区的使用大小
- OC: 老年代大小
- OU: 老年代使用大小
- MC: 方法区大小
- MU: 方法区使用大小
- CCSC: 压缩类空间大小
- CCSU: 压缩类空间使用大小
- YGC: 年轻代垃圾回收次数
- YGCT: 年轻代垃圾回收消耗时间
- FGC: 老年代垃圾回收次数
- FGCT: 老年代垃圾回收消耗时间
- GCT: 垃圾回收消耗总时间
如果面试官问你是怎么定位OOM问题的?能否用图形界面(不能!因为图形界面会影响服务器性能)
1:已经上线的系统不用图形界面用什么?(cmdline arthas)
2:图形界面到底用在什么地方?测试!测试的时候进行监控!(压测观察)
- jmap -histo 6892 | head -10,查找有多少对象产生
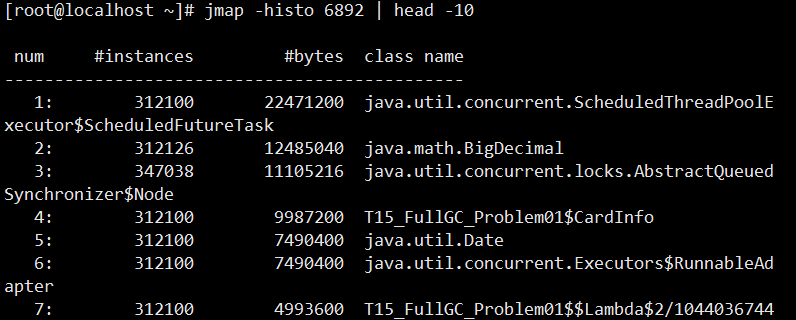
这明显能看出来是1对应的类创造的实例instances太多了,反过来追踪代码
-
jmap -dump:format=b,file=xxx pid :
线上系统,内存特别大,jmap执行期间会对进程产生很大影响,甚至卡顿(电商不适合)
1:设定了参数HeapDump,OOM的时候会自动产生堆转储文件
2:很多服务器备份(高可用),停掉这台服务器对其他服务器不影响
3:在线定位(一般小点儿公司用不到)
[root@localhost ~]# jmap -dump:format=b,file=2021_2_8.dump 6892
Dumping heap to /root/2021_2_8.dump ...
Heap dump file created
dump文件存放位置:
- java -Xms20M -Xmx20M -XX:+UseParallelGC -XX:+HeapDumpOnOutOfMemoryError com.courage.jvm.gc.T15_FullGC_Problem01
上面的意思是当发生内存溢出时自动生成堆转储文件,需要注意的是,如果生成了这个文件先不要重启服务器,将这个文件保存好之后再重启。 - 使用MAT / jhat /jvisualvm 进行dump文件分析
[root@localhost ~]# jhat -J-Xmx512M 2021_2_8.dump
报错:
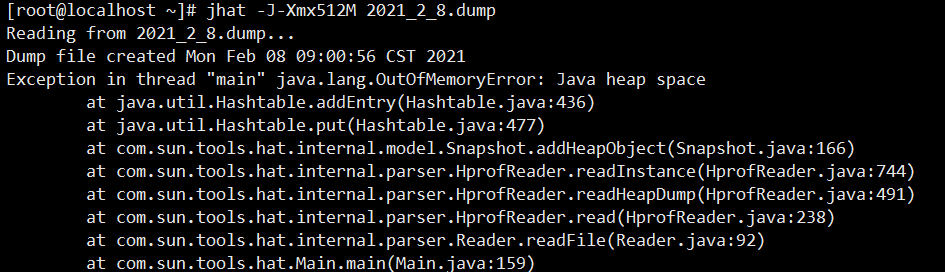
原因是设置的堆最大值太小了,将512M设置成1024M重新启动即可:
shell
[root@localhost ~]# jhat -J-Xmx1024M 2021_2_8.dump
Reading from 2021_2_8.dump...
Dump file created Mon Feb 08 09:00:56 CST 2021
Snapshot read, resolving...
Resolving 4609885 objects...
Chasing references, expect 921 dots..........................................................
.........................................................................................Eliminating duplicate references.............................................................
......................................................................................Snapshot resolved.
Started HTTP server on port 7000
Server is ready.
浏览器输入请求http://192.168.182.130:7000 即可查看,拉到最后:找到对应链接 可以使用OQL查找特定问题对象
其他可以参考:白灰——软件测试
- 最后找到代码的问题
JVM调优工具
jconsole远程连接
- 程序启动加入参数:
java -Djava.rmi.server.hostname=192.168.182.130
-Dcom.sun.management.jmxremote
-Dcom.sun.management.jmxremote.port=11111
-Dcom.sun.management.jmxremote.authenticate=false
-Dcom.sun.management.jmxremote.ssl=false XXX
- 如果遭遇 Local host name unknown:XXX的错误,修改/etc/hosts文件,把XXX加入进去
192.168.182.130 basic localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
- 关闭linux防火墙(实战中应该打开对应端口)
service iptables stop
chkconfig iptables off #永久关闭
- windows上打开 jconsole远程连接 192.168.182.130:11111
jvisualvm远程连接
这个软件在JDK8以后版本中移除了,使用的话需要额外下载,并且要在etc/visualvm.conf中修改默认的JDK_Home地址。
参考:使用jvisualvm的jstatd方式远程监控Java程序
阿里巴巴Arthas
这个直接看官网就行了,纯中文:Arthas 用户文档
JVM调优案例
参数设置之承受海量访问的动态Web应用
服务器配置:8 核 CPU, 8G MEM, JDK 1.6.X
参数方案:
-server -Xmx3550m -Xms3550m -Xmn1256m -Xss128k -XX:SurvivorRatio=6 -XX:MaxPermSize=256m -XX:ParallelGCThreads=8 -XX:MaxTenuringThreshold=0 -XX:+UseConcMarkSweepGC
调优说明:
-Xmx 与 -Xms 相同以避免JVM反复重新申请内存。-Xmx 的大小约等于系统内存大小的一半,即充分利用系统资源,又给予系统安全运行的空间。
-Xmn1256m 设置年轻代大小为1256MB。此值对系统性能影响较大,Sun官方推荐配置年轻代大小为整个堆的3/8。
-Xss128k 设置较小的线程栈以支持创建更多的线程,支持海量访问,并提升系统性能。
-XX:SurvivorRatio=6 设置年轻代中Eden区与Survivor区的比值。系统默认是8,根据经验设置为6,则2个Survivor区与1个Eden区的比值为2:6,一个Survivor区占整个年轻代的1/8。
-XX:ParallelGCThreads=8 配置并行收集器的线程数,即同时8个线程一起进行垃圾回收。此值一般配置为与CPU数目相等。
-XX:MaxTenuringThreshold=0 设置垃圾最大年龄(在年轻代的存活次数)。如果设置为0的话,则年轻代对象不经过Survivor区直接进入年老代。对于年老代比较多的应用,可以提高效率;如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概率。根据被海量访问的动态Web应用之特点,其内存要么被缓存起来以减少直接访问DB,要么被快速回收以支持高并发海量请求,因此其内存对象在年轻代存活多次意义不大,可以直接进入年老代,根据实际应用效果,在这里设置此值为0。
-XX:+UseConcMarkSweepGC 设置年老代为并发收集。CMS(ConcMarkSweepGC)收集的目标是尽量减少应用的暂停时间,减少Full GC发生的几率,利用和应用程序线程并发的垃圾回收线程来标记清除年老代内存,适用于应用中存在比较多的长生命周期对象的情况。
参数设置之内部集成构建服务器
高性能数据处理的工具应用
服务器配置:1 核 CPU, 4G MEM, JDK 1.6.X
参数方案:
-server -XX:PermSize=196m -XX:MaxPermSize=196m -Xmn320m -Xms768m -Xmx1024m
调优说明:
-XX:PermSize=196m -XX:MaxPermSize=196m 根据集成构建的特点,大规模的系统编译可能需要加载大量的Java类到内存中,所以预先分配好大量的持久代内存是高效和必要的。
-Xmn320m 遵循年轻代大小为整个堆的3/8原则。
-Xms768m -Xmx1024m 根据系统大致能够承受的堆内存大小设置即可。