1.写在前面
前面分享了 JVM调优原则和原理分析 ,详情可查看:这里
基于该文章,我们大体上对 JVM 有一个概况性的理解,同时我们知道了 JVM调优原则 (JVM优化是不得已的手段)
对 调优基础知识 (head堆,垃圾回收器)等知识点,有一个初步的认识。
那今天我们继续分享一下: 垃圾回收算法 ,和 调优的关键指标 ,等内容。

2.JVM的GC基本原理
2.1 什么是垃圾?
在内存中 没有被引用的对象 就是垃圾(一次请求会在内存中创建出很多的对象,这些对象不会自己消失,必须进行 垃圾回收 ,当然 垃圾回收器 是jvm自己提供的。)
(特别注意:高并发的场景下,内存中尤其会创建海量的对象,这些对象所占用的内存必须及时被释放,否则影响程序性能)
一个对象引用消失了,那么这个对象就变成 垃圾 ;因此这个对象必须被 垃圾回收器 回收;
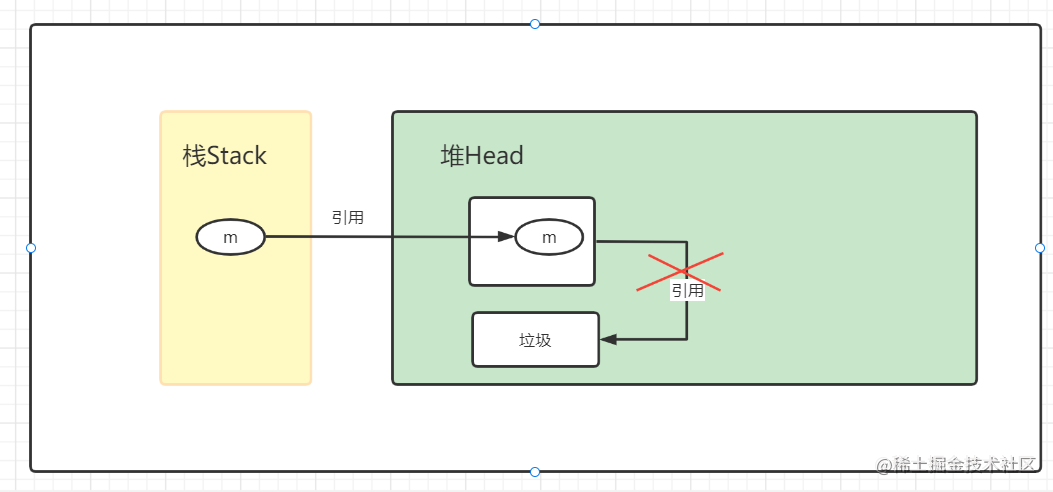
那说到这里,我们就会有疑问了,怎样判断一个对象,将会成为垃圾呢?
别急,且听哥们一一道来!!!接着往下。
2.2 如何找到这个垃圾?
Jvm中有 2 种寻找垃圾对象的方案:
1 、引用计数算法
2 、根可达算法 ----- hotspot垃圾回收器 都是使用这个算法
1) 引用计数算法:
通过引用计数方法,找到这个垃圾:
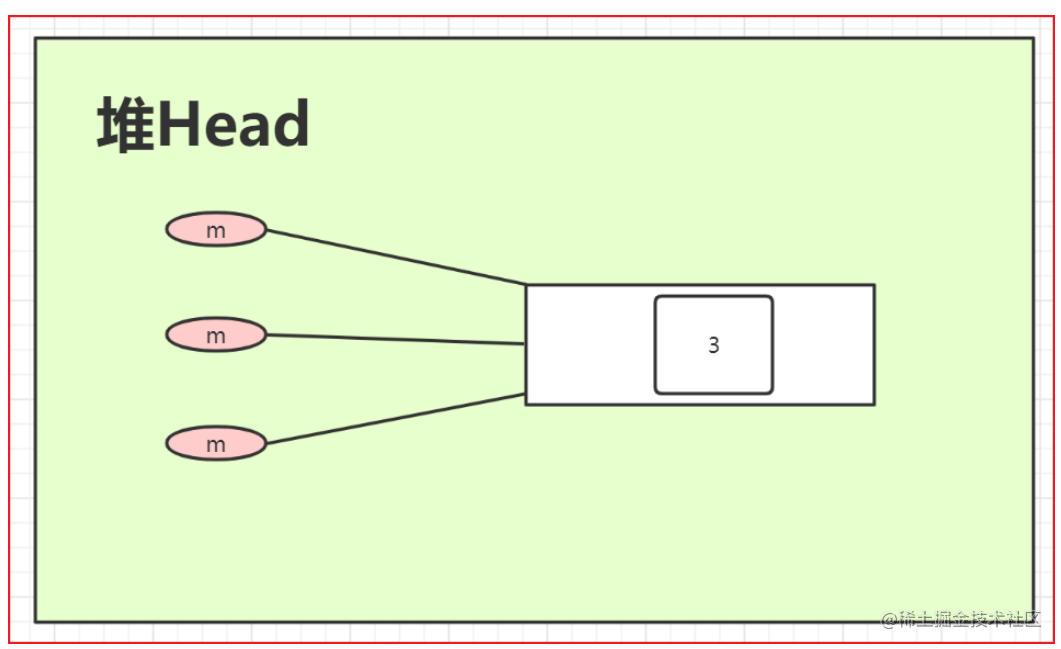
当这个对象引用都消失了,消失一个计数减一,当引用都消失了,计数就会变为0.此时这个对象就会变成垃圾。
这样,会存在问题:
在堆内存中主要的引用关系有如下三种:
- 单一引用
- 循环引用
- 无引用
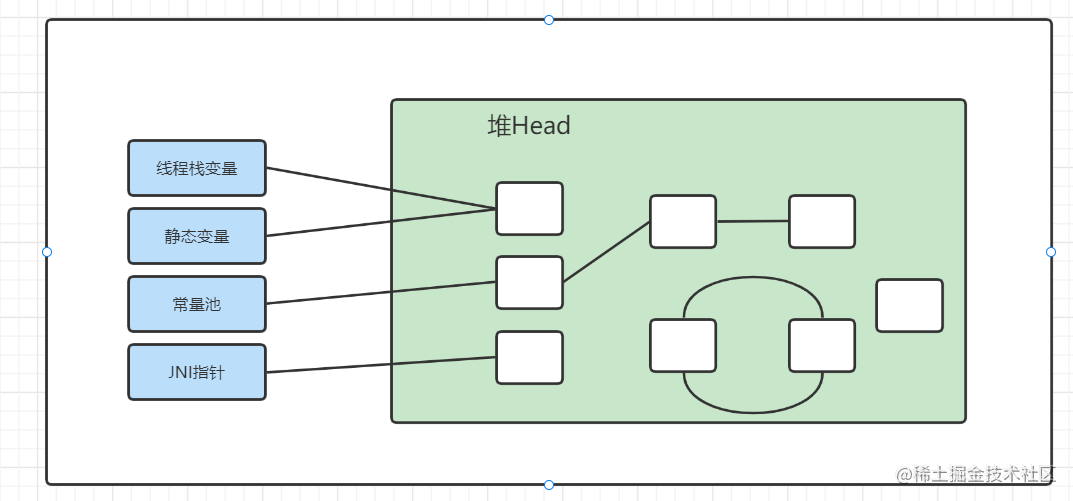
由此可见,引用计数算法不能解决循环引用问题。为了解决这个问题,Java使用了根可达分析算法。
循环引用,使用这个算法,是无法解决的。
那就引出了另外一种算法: 根可达算法
2) 根可达算法:
hotspot 目前使用的主要的垃圾回收器的算法,因为引用计数无法解决循环引用计数的问题。
根可达分析算法 的基本思想是: 通过一系列名为"GC roots"的对象作为起始点,从这个被称为GC roots的对象开始,向下搜索,如果一个对象到GC roots没有任何引用链相连时,说明此对象不可用。
也即给定一个集合的引用作为 根 出发,通过引用关系遍历对象图,能够遍历到的(可到达)对象就被判定为 存活 ,没有则自然被判定为 死亡 。
所谓的"GC roots"对象起始点,或者说tracing GC的"根集合"就是一组必须活跃的引用。
通过 根可达算法 ,我们已经找出垃圾对象了,接下来,就是清除垃圾。
如何清除垃圾呢?这里JVM提供3种算法。且听哥们一一道来!!!

2.3 如何清除垃圾?
JVM提供 3 种方法,清除垃圾对象
- Mark-Sweep 标记清除算法
- Copying 拷贝算法
- Mark-Compact 标记压缩算法
Mark-Sweep 标记清除算法
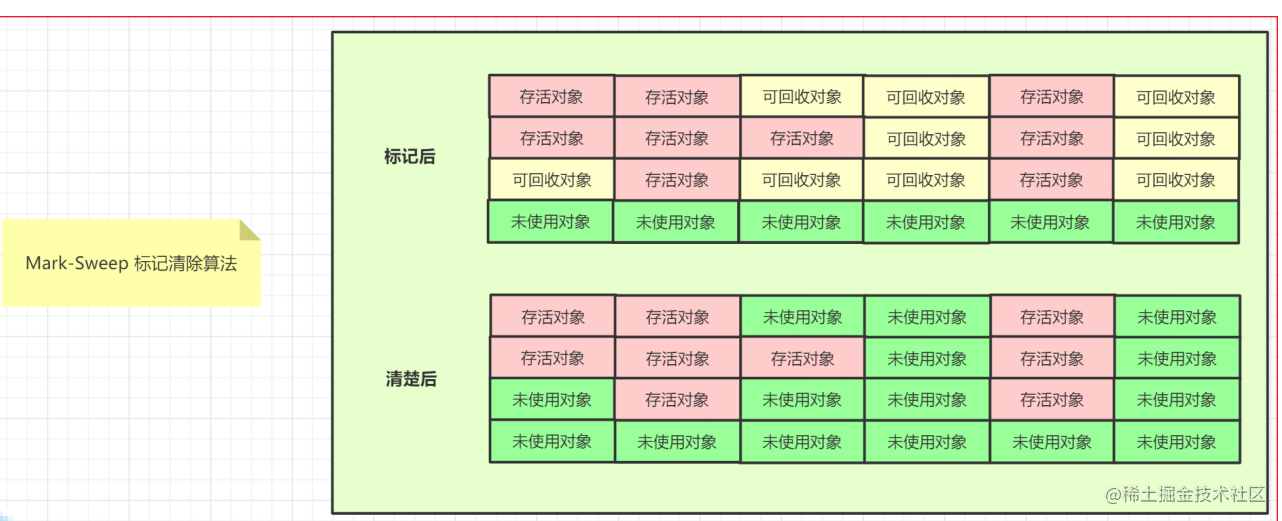
- 缺点:内存存储空间碎片化
Copying 拷贝算法
为了解决效率问题,Copying 拷贝算法将可用内存按容量划分为大小相等的两块,每次只使用其中一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。这样使得每次都是对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将内存缩小为了原来的一半。
- 优点:没有碎片化,所有的有用的空间都连接在一起,所有的空闲空间都连接在一起
- 缺点:存在空间浪费。
Mark-Compact 标记压缩算法
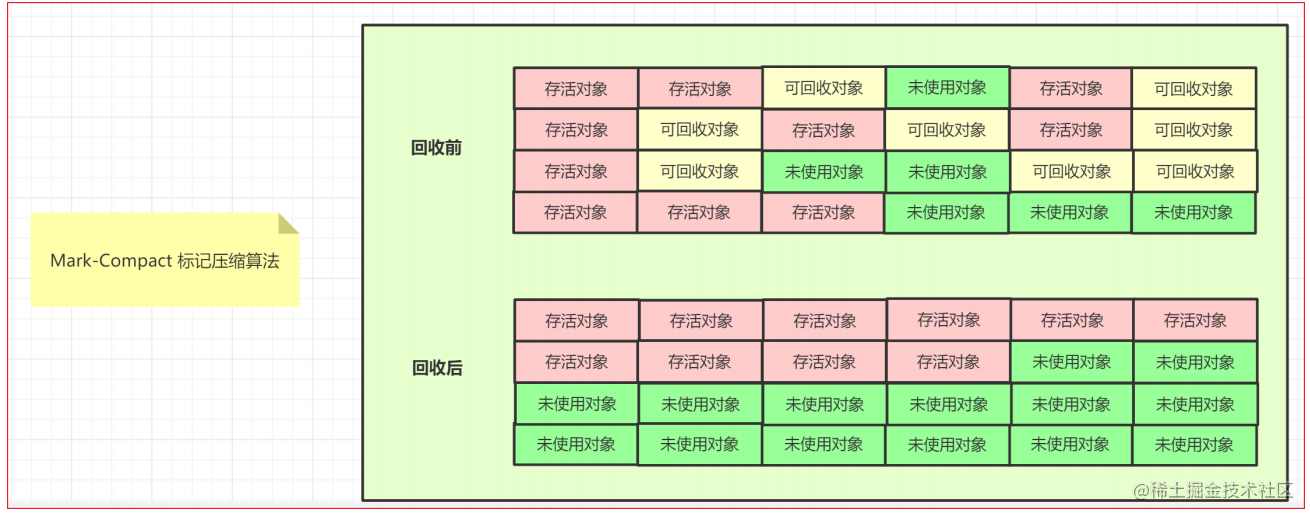
标记压缩算法,把存活对象拷贝到可回收的空间,然后把存活对象空间进行压缩,串联起来,把未使用的对象空间串联起来,组成连续的内存空间,这样就不会有碎片。
- 缺点:性能较低,因为除了拷贝对象以外,还需要对象内存空间进行压缩,所以性能较低。
2.4 用什么清除垃圾
有 7 种不同的垃圾回收器,它们分别用于不同分代的垃圾回收。
- 新生代回收器:Serial、ParNew、Parallel Scavenge
- 老年代回收器:Serial Old、Parallel Old、CMS
- 整堆回收器:G
两个垃圾回收器之间有连线表示它们可以搭配使用,可选的搭配方案如下:
| 新生代 | 老年代 |
|---|---|
| Serial | SerialOld |
| Serial | CMS |
| ParNew | SerialOld |
| ParNew | CMS |
| ParallelScavenge | SerialOld |
| ParallelScavenge | ParallelOld |
| G1 | G1 |
3.调优关键指标
调优的最终目的都是为了应用程序使用 最小的硬件 消耗来承载更大的 吞吐量
3.1 吞吐量
重要指标之一,吞吐量是衡量系统在单位时间里面完成的工作数量。吞吐量需求通常忽略延迟或者响应时间。通常情况下,提升吞吐量需要以系统响应变慢和更多内存消耗作为代价。
- TPS:每秒事务数
- Throughput:吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间),虚拟机总共运行了 100 分钟,其中垃圾收集花掉 1 分钟,那吞吐量就是99%。
3.2 延迟或响应时间
延迟或者响应时间是衡量应用从接收到一个任务到完成这个任务消耗的时间。一个延迟或者响应时间的需求需要忽略吞吐量。通常来讲,提升应用的响应时间需要以更低吞吐量或提高应用的内存消耗。
延迟或者响应时间例子:"例如系统处理一个HTTP请求需要200ms,这个200ms就是系统的响应时间。"
3.3 内存占用
内存占用是衡量应用消耗的内存,这个内存占用是指应用在运行在某一个吞吐量、延迟以及可用性和易管理性指标下的内存消耗,内存占用是通常描述为应用运行的时候Java堆的大小或者总共需要消耗内存。
通常情况下,通过增加Java堆的大小以增加应用内存占用可以提升吞吐量或者减少延迟,或者两者兼具。当应用可用的内存减少的时候,吞吐量和延迟通常会受到损失。在给定内存的情况下,应用占用的内存可以限制应用的实例数(这个会影响可用性)。
内存占用需求例子:“这个应用会单独运行在一个8G的系统上面或者多出 3 个应用实例运行在一个24G的应用系统上面。”
好了,以上就是我个人的经验的分享了。
个人理解,可能也不够全面,班门弄斧了。
今天就先到这里了,掰掰了!!!^_^
如果觉得有收获的,帮忙点赞、评论、收藏一下呗!!!
