什么是JVM
JVM就是java virtual machine,java虚拟机
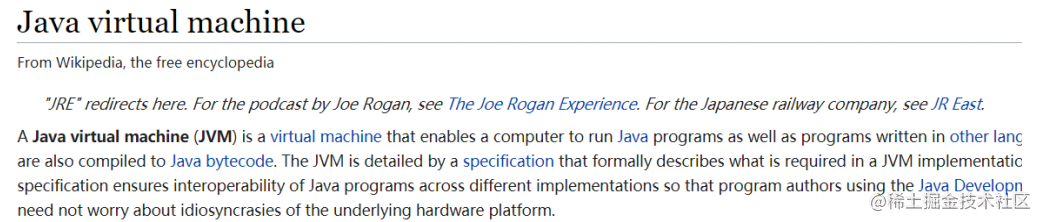
JVM就是将java源文件编译成字节码文件,然后加载到虚拟机,JVM在执行字节码时,最终把字节码解释成具体平台上的机器指令执行。这个就是一次编写,到处运行。
JVM是一种java虚拟机规范,很多厂商进行了实现,可以通过java -version命令查看
- Oracle:HotSpot、JRockit
- IBM:J9 VM
- Ali:TaobaoVM
- Zual:Zing
当然最常见的就是HotSpot了

docs.oracle.com/javase/8/do… ,JVM在这一层,所以平时我们装了jdk,jvm也自带装好了。
HotSpot JVM架构
下面是hotspot官网上的架构图
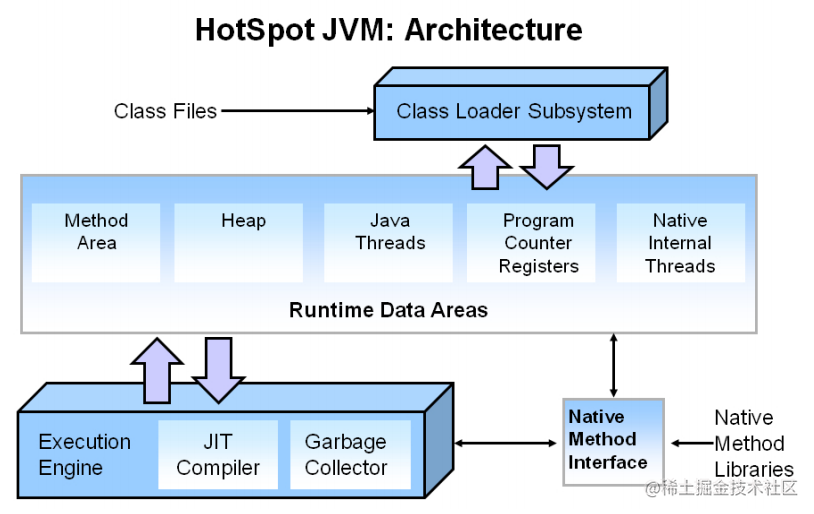
然后我们来依次介绍各个组件
类加载器
类加载器分为三个过程,Loading,Linking,Initializing。
Loading装载
装载就是找到Class文件所在的全路径,然后装载到内存中,生成一个与之匹配的Class对象 。JVM在运行的时候会产生三个类加载器,每一个类加载器加载自己所属范围的架包。用户也可以自定义类加载器。
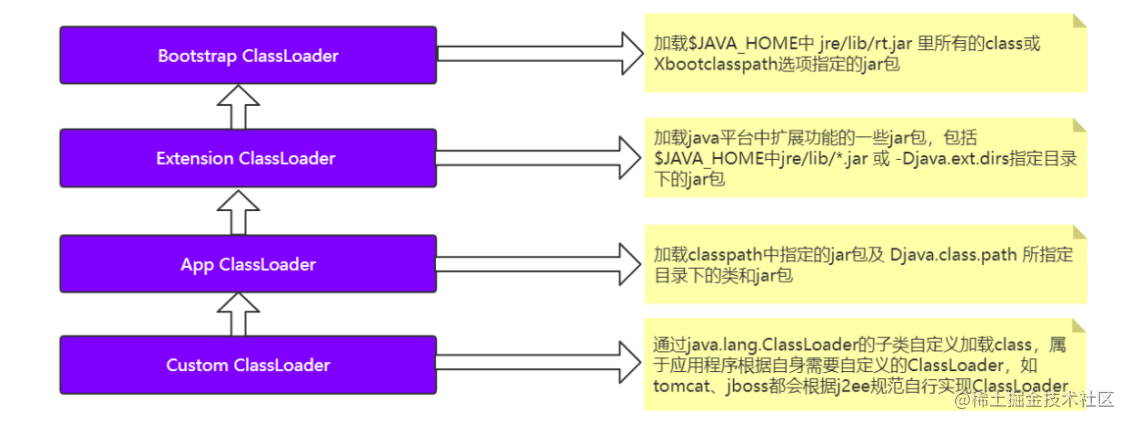
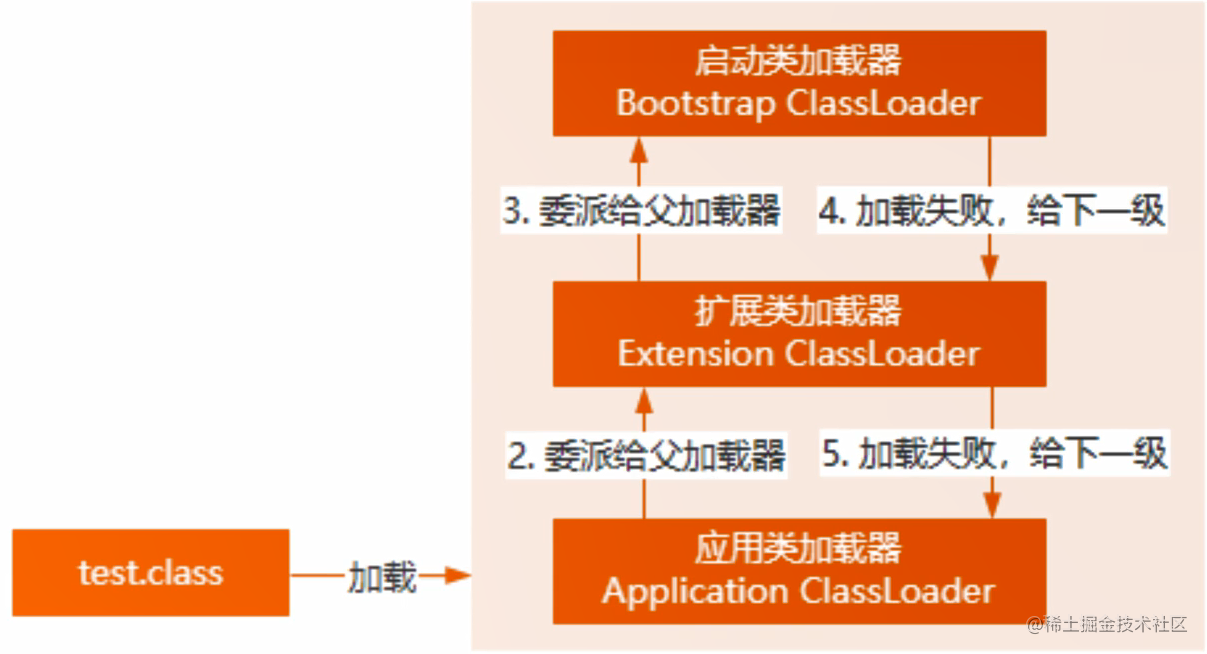
类加载的时候使用的是 双亲委派模式 。当加载一个类的时候先检查是否已经装载过了,如果没有的话判断是否存在上层,如果有上层就继续交给上层去装载,直到最顶层。如果找到最顶层都发现没有被装载过,那就自顶向下再加载。
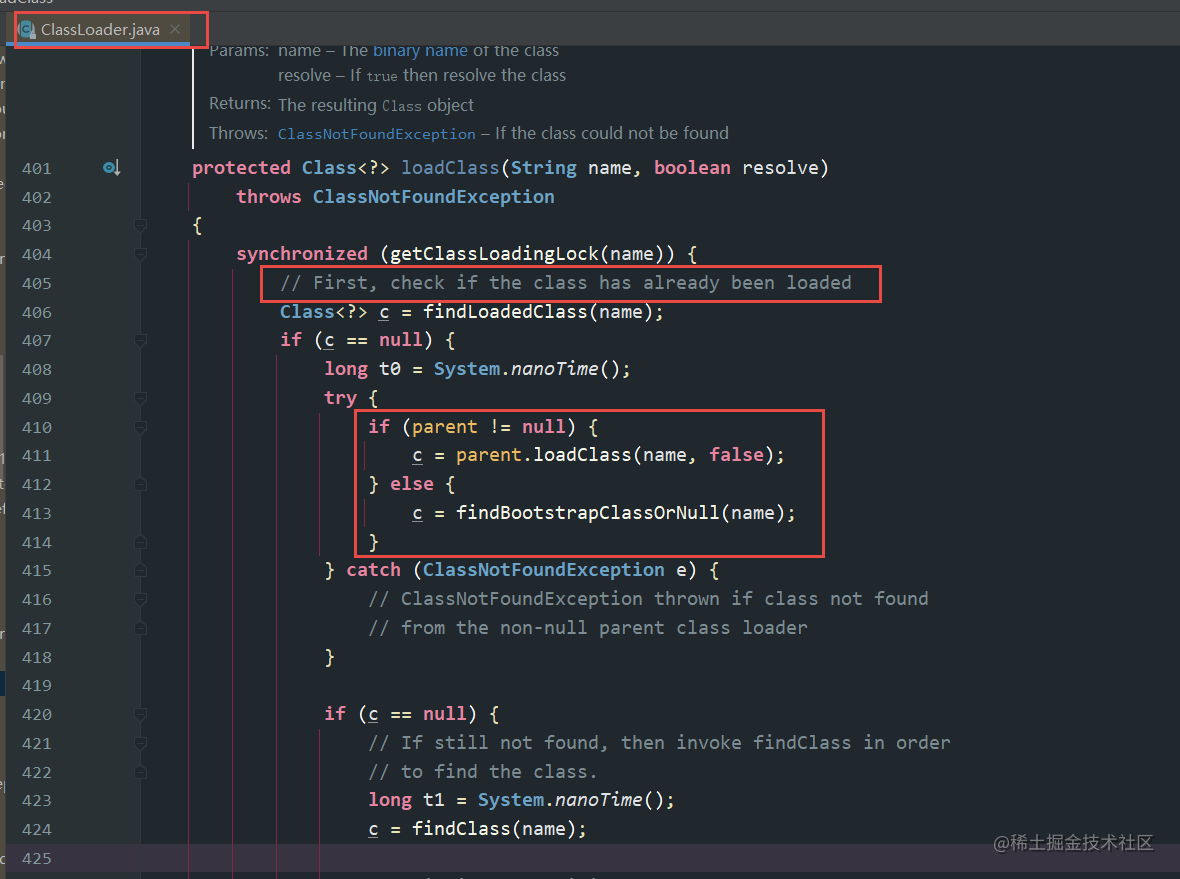
我们点开ClassLoader.java源码发现也是这么一个过程。
 那么这么做的一个好处就是安全,当我们自己写了一个java.lang.String的类要装载的时候,由于这样的机制,需要交给顶层Bootstrap ClassLoader去装载,当到达顶层的时候发现已经被装载过了,那么就直接返回,那么自己写的java.lang.String类也就不会被装载进去了,具体的思路流程小伙伴可以结合着ClassLoader.java源码再理解下。
那么这么做的一个好处就是安全,当我们自己写了一个java.lang.String的类要装载的时候,由于这样的机制,需要交给顶层Bootstrap ClassLoader去装载,当到达顶层的时候发现已经被装载过了,那么就直接返回,那么自己写的java.lang.String类也就不会被装载进去了,具体的思路流程小伙伴可以结合着ClassLoader.java源码再理解下。
小伙伴们再看下demo,加深下印象。
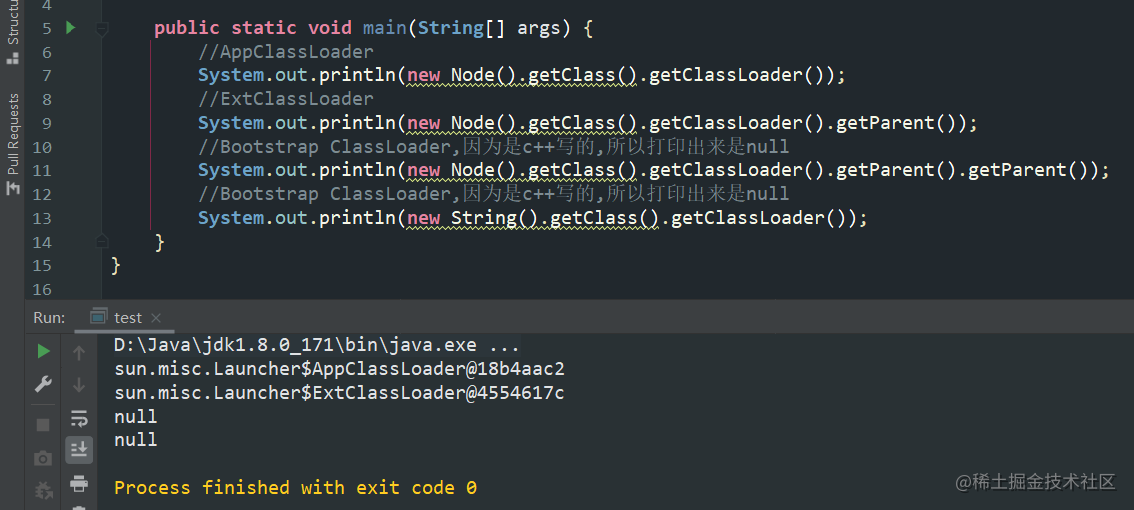
Linking链接
Linking又分为 Verification验证、Preparation准备、Resolution解析 三个过程。
验证 就是确保Class文件字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身安全。
准备 负责为类的类变量(被static修饰的变量)分配内存,并设置默认初始化值。
解析 动态地将运行时常量池中的符号引用转变为直接引用。
符号引用长这样:5d85 5849 2f63
直接引用长这样:0x00ab 0x00ba 物理内存地址
Initializing初始化
对类的静态变量,静态代码块执行初始化操作。
运行时数据区
一共有五个区域,方法区,堆,java虚拟机栈,程序计数器,本地方法栈。
堆
Java堆是Java虚拟机所管理内存中最大的一块,在虚拟机启动时创建,被所有线程共享。Java对象实例以及数组都在堆上分配。堆内存空间不足时,就会抛出OOM。
一个Java对象在内存中包括3个部分:对象头、实例数据和对齐填充。Mark Word里面更详细的64位可以查看《大话Synchronized及锁升级》文章。

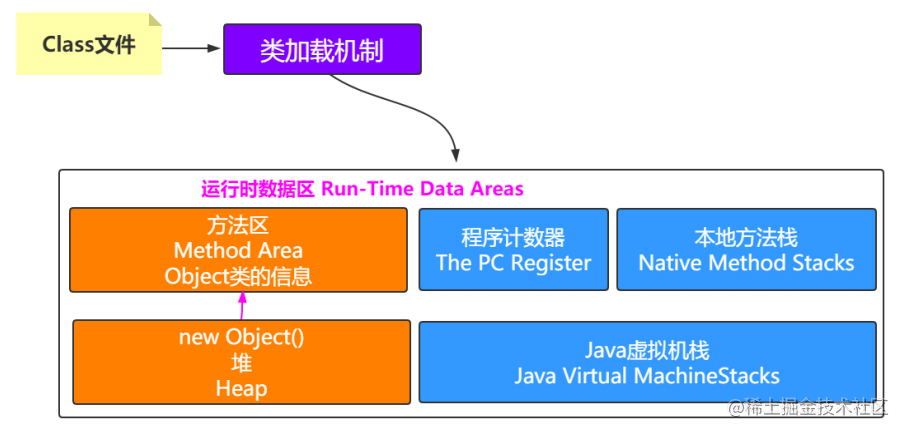
当执行下面这句话的时候,静态成员变量存储在方法区,而new Object()对象存储在堆。
private static Object obj = new Object();
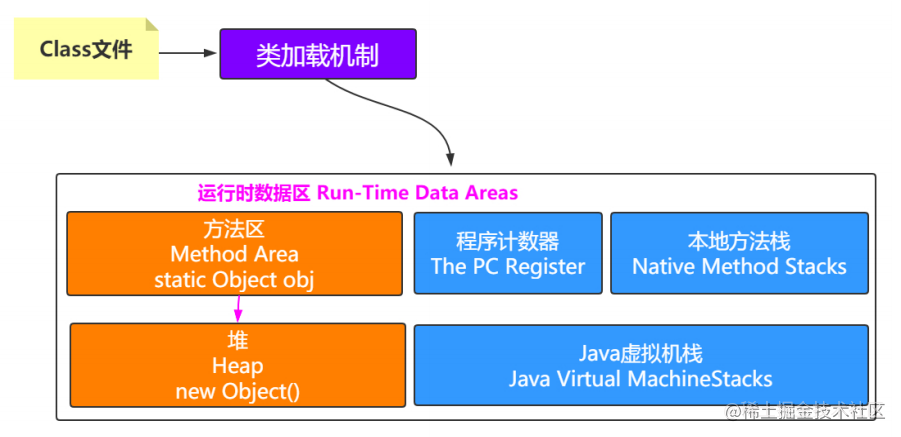
new Object()对象的类信息即类的模板存储在方法区。
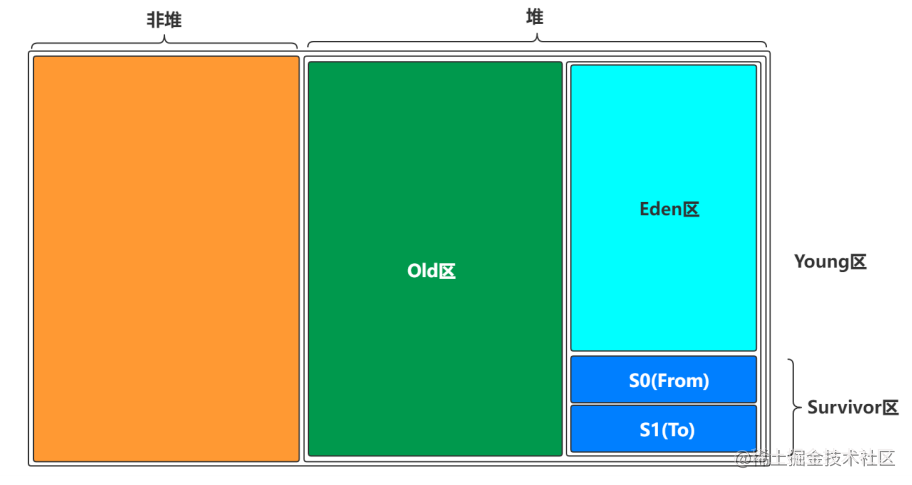
堆分为两大块,一个是old区,一个是young区,young区又分为两大块,一个是Survivor区(S0+S1),一块是Eden区,S0和S1一样大,也可以叫From和To。
感受OOM:
首先打开jdk安装目录下的bin目录下的jvisualvm.exe文件, 以管理员身份运行 。
打开以后点击工具—插件
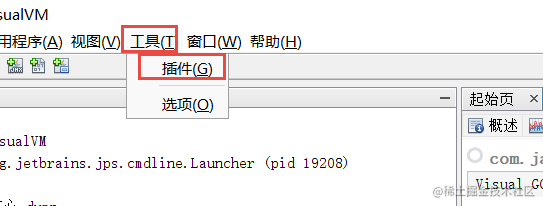
然后安装一下Visual GC这个插件,重启一下
启动一个Spring Boot项目,JVM的参数设置成-Xmx50M -Xms50M,这样堆的大小就设置成50M。
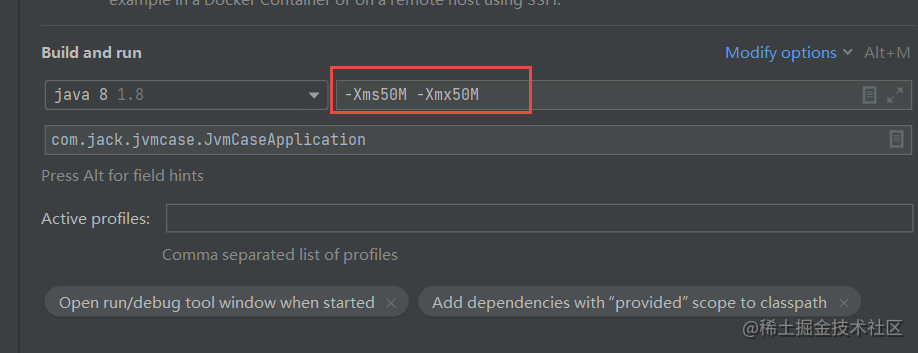
我们看到已经注册上来了
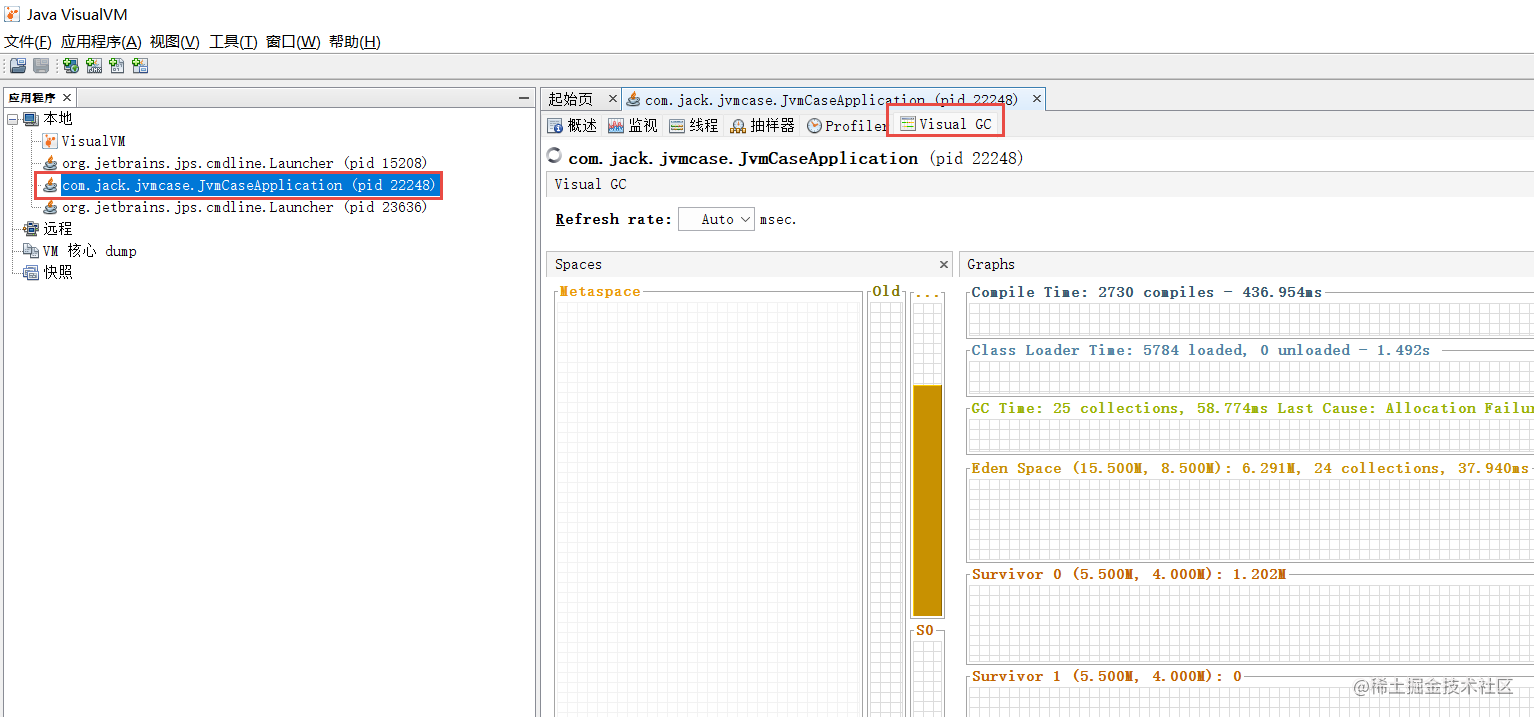
写一段生成对象的代码
@RestController
public class HeapController {
List<Worker> list = new ArrayList<Worker>();
@GetMapping("/heap")
public String heap() throws Exception {
while (true) {
// Thread.sleep(10);
list.add(new Worker());
}
}
}
访问一下,一直在转圈
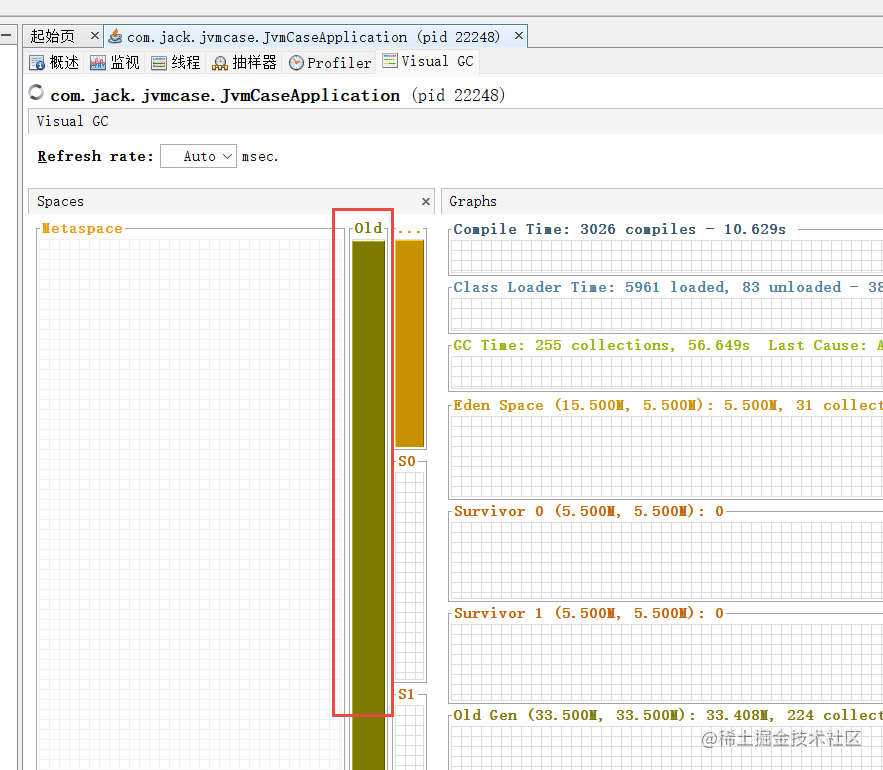
我们看到VisualVM里old区已经飙升满了
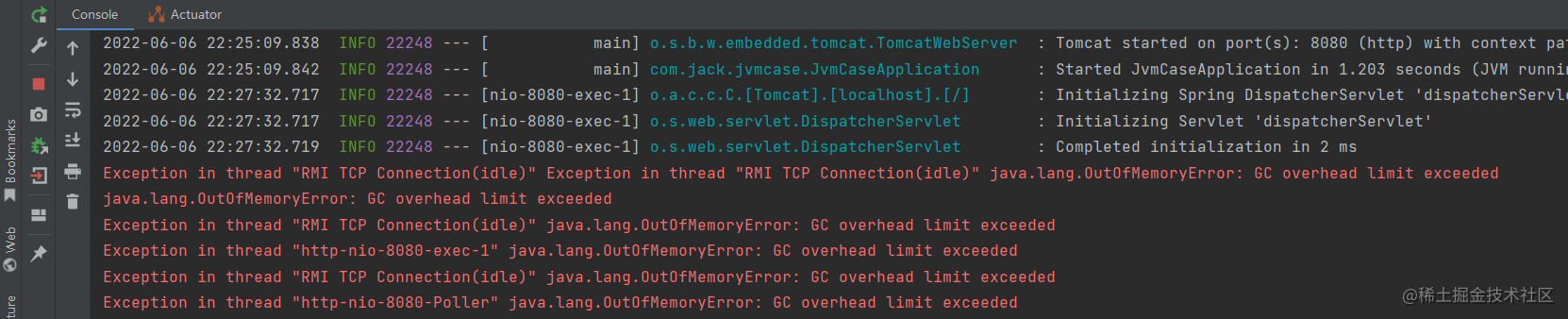
编辑器也报出了OOM的错误信息
感受结束
方法区
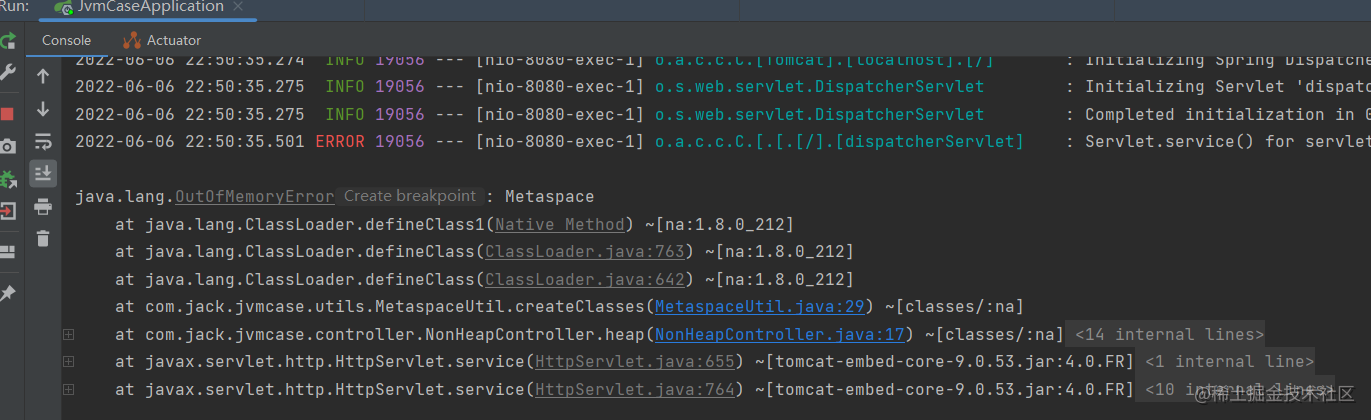
方法区是一种规范,真正的实现在JDK 8中就是Metaspace元空间,在JDK6或7中就是Perm Space永久代。 方法区是各个线程共享的内存区域,在虚拟机启动时创建。方法区中存储的是 类信息、常量、静态变量、即时编译器编译后的代码等数据 。当方法区无法满足内存分配需求时,将抛出OutOfMemoryError异常,我们同样来感受一下。
先在项目中引用asm的架包,这个是创建类信息的工具
<dependency>
<groupId>asm</groupId>
<artifactId>asm</artifactId>
<version>3.3.1</version>
</dependency>
然后把方法区的大小也设置成50M
写一个创建类信息的工具类,这个是网上的模板代码
public class MetaspaceUtil extends ClassLoader {
public static List<Class<?>> createClasses() {
List<Class<?>> classes = new ArrayList<Class<?>>();
for (int i = 0; i < 10000000; ++i) {
ClassWriter cw = new ClassWriter(0);
cw.visit(Opcodes.V1_1, Opcodes.ACC_PUBLIC, "Class" + i, null,
"java/lang/Object", null);
MethodVisitor mw = cw.visitMethod(Opcodes.ACC_PUBLIC, "<init>",
"()V", null, null);
mw.visitVarInsn(Opcodes.ALOAD, 0);
mw.visitMethodInsn(Opcodes.INVOKESPECIAL, "java/lang/Object",
"<init>", "()V");
mw.visitInsn(Opcodes.RETURN);
mw.visitMaxs(1, 1);
mw.visitEnd();
MetaspaceUtil test = new MetaspaceUtil();
byte[] code = cw.toByteArray();
Class<?> exampleClass = test.defineClass("Class" + i, code, 0, code.length);
classes.add(exampleClass);
}
return classes;
}
}
启动下项目
访问下请求非堆的方法
@RestController
public class NonHeapController {
List<Class<?>> list = new ArrayList<Class<?>>();
@GetMapping("/nonheap")
public String heap() {
while (true) {
list.addAll(MetaspaceUtil.createClasses());
}
}
}
看下编辑器已经报错了
 感受结束
感受结束
Java虚拟机栈
Java虚拟机栈是线程独有的,里面保存着一个线程中方法的调用状态,它的生命周期是和线程绑定在一起。每一个被线程执行的方法,为该栈中的 栈帧 ,即每个方法对应一个栈帧,调用一个方法,就会向栈中压入一个栈帧;一个方法调用完成,就会把该栈帧从栈中弹出。
当我们运行如下一段代码的时候,压栈出栈的过程是这样的。
void a(){
b();
}
void b(){
c();
}
void c(){
}
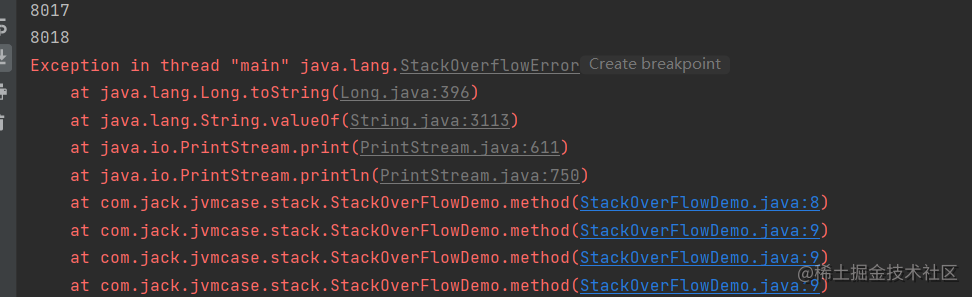
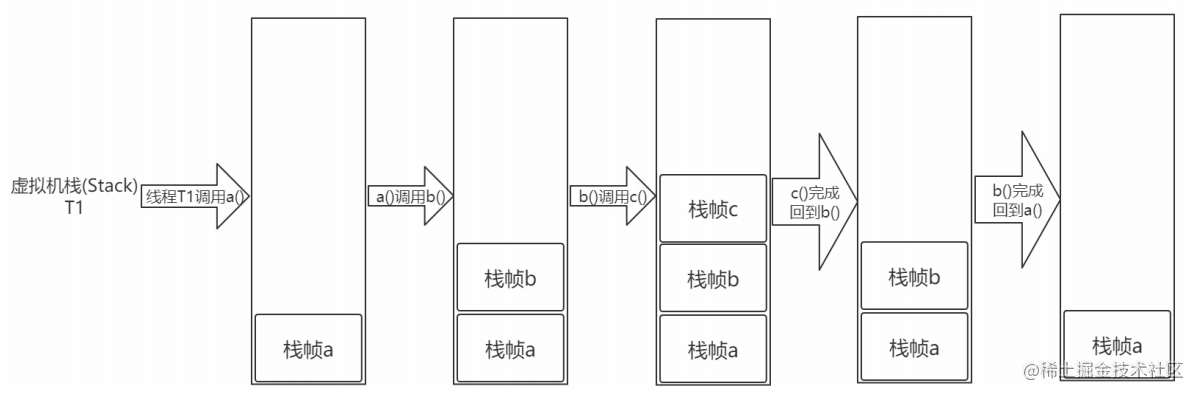 当我们发生递归的时候,不停的往里面压栈,由于栈的大小是固定的,所以超出以后也会发生OOM。感受一下
当我们发生递归的时候,不停的往里面压栈,由于栈的大小是固定的,所以超出以后也会发生OOM。感受一下
public class StackOverFlowDemo {
public static long count = 0;
public static void method() {
System.out.println(count++);
method();
}
public static void main(String[] args) {
method();
}
}
运行一下,报错了
我们看下栈帧里面有哪些东西
-
局部变量表:用来存储局部变量的
-
操作数栈:为了进行算术运算的一个临时保存地方
-
动态链接: 将符号引用转化为直接引用,上面讲解析的时候会转换一部分 ,这叫静态解析,还有一部分就是运行期间转换,这叫动态链接
-
返回地址:GOTO JUMP为了让后续的方法能够顺利执行
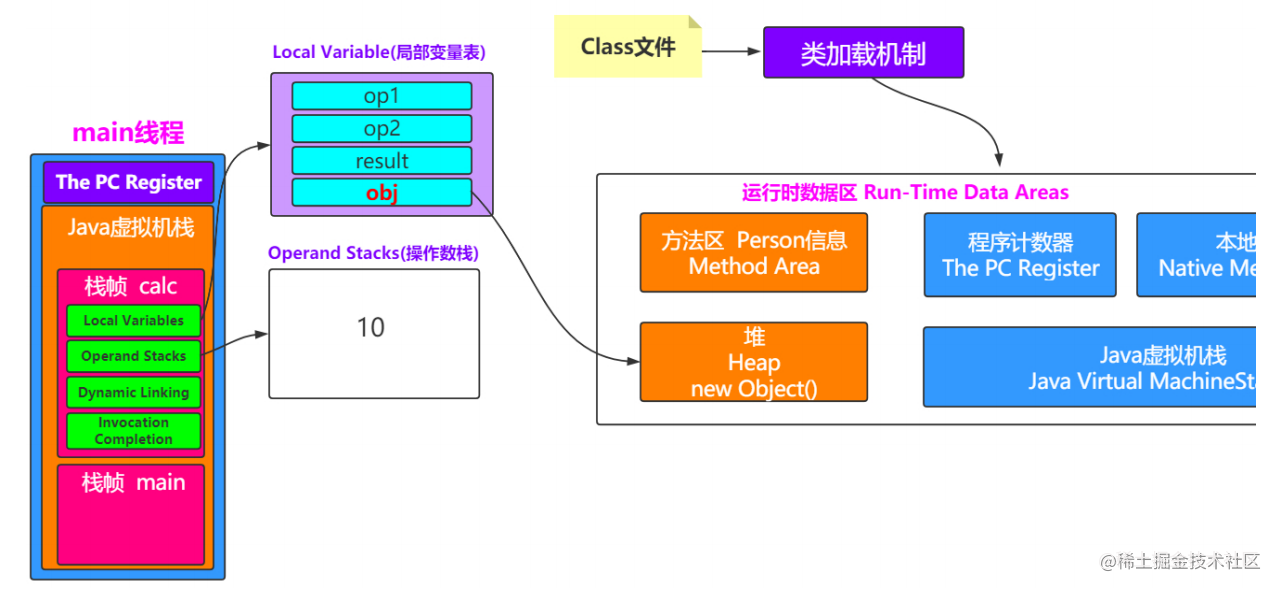
程序计数器
也是线程独有的,如果线程正在执行Java方法,则计数器记录的是正在执行的虚拟机字节码指令的地址。如果正在执行的是Native方法,则这个计数器为空。
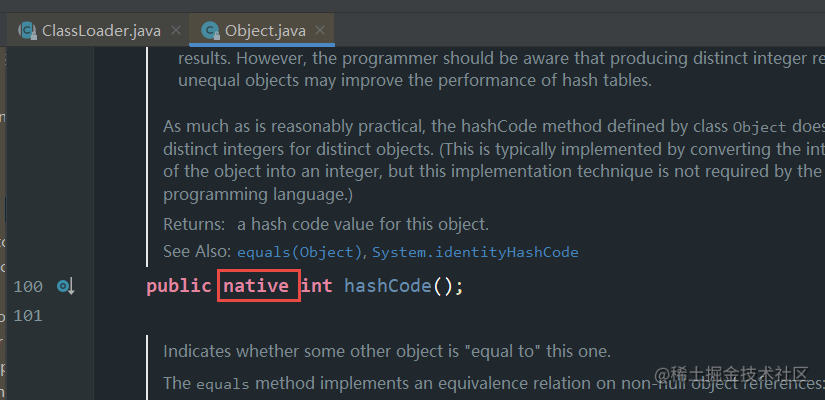
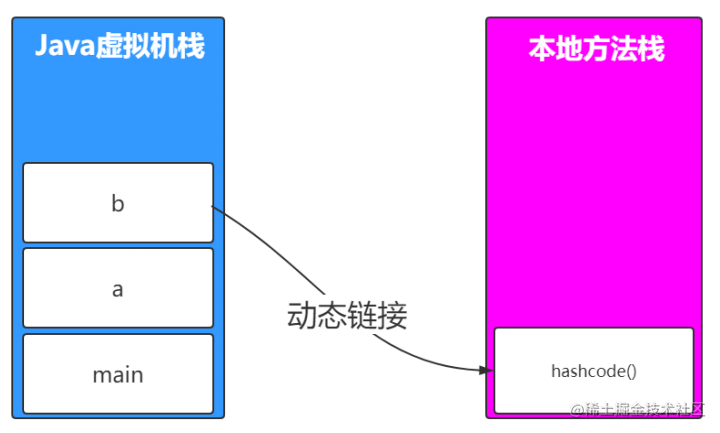
本地方法栈
类比java虚拟机栈,我们看下Object类里面的hashCode()方法,这是一个native方法,当调用到java编写的方法的时候可以压入到java虚拟栈,而hashCode是native方法怎么办,则是压入要本地方法栈。
 通过动态链接链接过去
通过动态链接链接过去
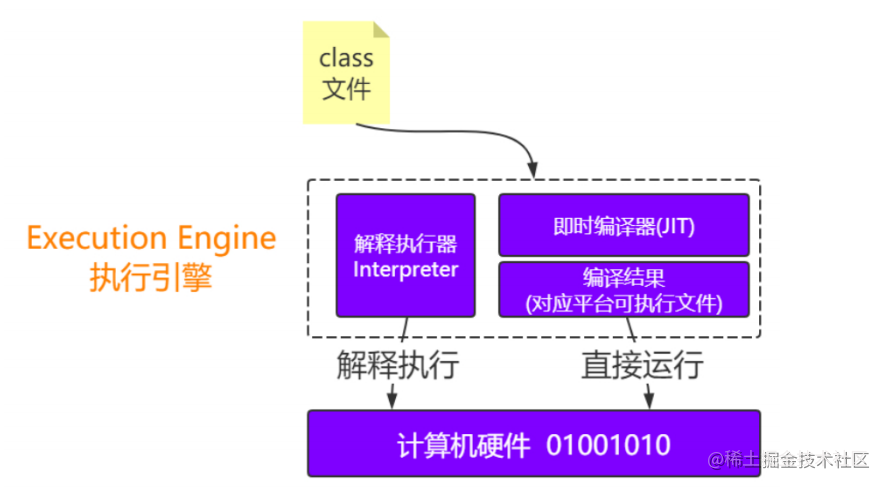
Execution Engine
我们看到官网上的Execution Engine只有JIT Compiler,这个是编译器,我画的图上会多一个Interpreter,这个是解释器,为什么官网上没画,是因为JDK1.0开始就默认已经有了,而JIT是后面的版本不停的加入的。
编译器
什么是编译器, 编译器是将源代码编译(翻译)成低级语言的程序 ,这里的javac就是编译器,javac把 Helloworld.java 文件编译成 Helloworld.class 文件,交给JVM运行,因为JVM只能认识class字节码文件。同时在不同的操作系统上安装对应版本的JDK,里面包含了各自屏蔽操作系统底层细节的JVM, 这样同一份class文件就能运行在不同的操作系统平台之上,得益于JVM。这也是Write Once,Run Anywhere的原因所在。 javac编译器称为前端编译器 。
解释器
解释器是直接执行用编程语言编写的指令的程序。只有在执行程序时,才 一条一条的解释 成机器语言给计算机来执行,使用解释器来运行程序会比直接运行编译过的机器码来得慢。 Interpreter就是解释Java字节码文件。
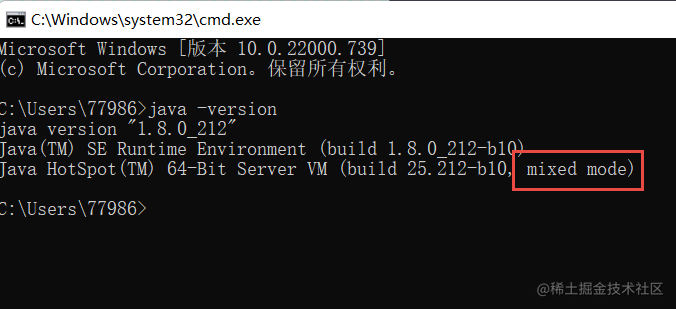
执行引擎有三种执行模式。
混合模式
混合模式是JVM的默认工作模式,即JVM同时使用 解释模式和编译模式 。我们可以敲java -version看下是mixed模式。
解释器上面已经介绍了,就是把class文件一行一行的解释成机器语言给电脑执行, 那么JIT编辑器的作用就是对于字节码中某个方法或代码块执行特频繁时,将其认定为热点代码,然后将热点代码编译成本地代码,并且会进行优化,以此来提高执行效率 (这个也是HotSpot的由来)。而被调用很少(甚至只有一次)的方法在解释模式下执行,从而减少编译和优化成本。使用混合模式可以获得最好的执行效率。
JIT编译器称为后端编译器,与javac编译器不同。 因为javac编译的是java文件,JIT编译的是字节码文件。 虚拟机中内置了两个JIT编译器,client compiler(c1)和server compiler(c2),程序会根据虚拟机运行模式(client模式还是server模式)决定使用哪个编译器。
解释模式
- 不经过JIT直接由解释器Interpreter解释执行所有字节码。
- 特点:启动快(不需要编译),执行慢。
- 可通过-Xint参数指定为纯解释模式。
编译模式
- 不加筛选的将全部代码编译成机器码,不考虑其执行的频率是否有编译的价值。
- 特点:启动慢(编译过程较慢),执行快。
- 可通过-Xcomp参数指定为纯编译模式。
Garbage Collector
GC即垃圾收集器,请参考另一篇《一篇文章搞懂GC垃圾回收》 ,整个JVM架构到这里就结束了,喜欢的小伙伴 点赞、关注、收藏,一键三连哦~
本文代码在: github.com/xuhaoj/jvm-…